一、ollama 与 docker 简介
(一)ollama(Ollama)
ollama 是一个强大的工具,它为模型的管理和运行提供了便利。它可以简化模型的下载、配置和启动过程,让用户能够快速地将不同的模型集成到自己的工作流程中。例如,在处理多个不同类型的大语言模型时,ollama 可以轻松管理这些模型之间的切换和调用,提高开发效率。
(二)docker
docker 则是容器化技术的代表,它能够将应用程序及其依赖项打包成一个独立的容器。在 DeepSeek 部署中,使用 docker 可以确保 deepseek - r1 在不同环境中具有一致的运行状态。无论在开发环境、测试环境还是生产环境,只要安装了 docker,就可以运行相同的 deepseek - r1 容器,避免了因环境差异导致的兼容性问题。
二、利用 ollama 和 docker 配置 deepseek-r1 的准备工作
(一)硬件需求
同常规的 DeepSeek 部署类似,需要一台性能不错的计算机。内存建议 16GB 以上,这样在运行容器和模型时,能够保证系统的流畅性。同时,配备 NVIDIA GPU 会显著提升模型的推理速度,对于处理大规模文本任务非常关键。
(二)软件安装
安装 docker:可以从 docker 官方网站获取适合你操作系统的安装包,按照官方指引进行安装。在安装完成后,确保 docker 服务正常运行,可通过简单的命令行测试来验证(sheel中输入docker)。
安装 ollama:根据你使用的操作系统,选择合适的安装方式。例如,在 Linux 系统中,可以通过特定的脚本进行安装。安装完成后,配置好 ollama 的运行环境变量,确保其能够被系统正确识别。
三、配置 deepseek-r1 的详细步骤

可以看出DeepSeek-r1完全模型在各方面优于OpenAI,在某些方面评估甚至强于OpenAI,参数量适合于本地部署办公使用。
(一)使用 ollama 获取 deepseek-r1 模型
通过 ollama 的命令行工具,输入特定的命令来搜索和下载 deepseek - r1 模型。ollama 会自动从官方或指定的源获取模型文件,并将其存储在本地的模型库中。
(二)利用 docker 创建 deepseek-r1 容器
基于下载好的 deepseek - r1 模型,使用 docker 命令创建一个新的容器。在创建容器时,需要指定容器的名称、挂载的目录(以便与本地文件系统进行交互)以及容器运行所需的环境变量。
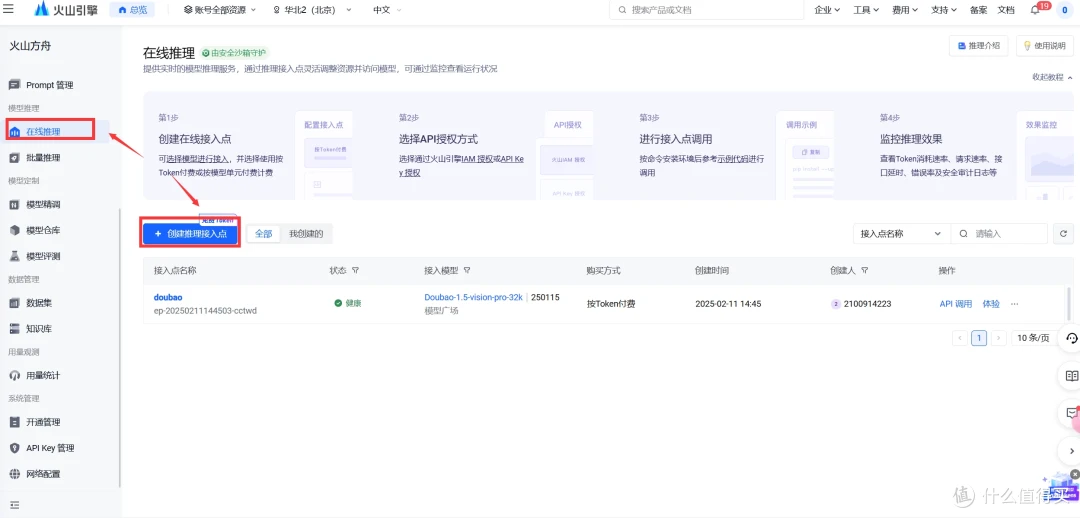
查看模型列表
可以访问 ollama 官方的模型仓库library查看支持的模型列表,点击浏览某个模型,可看到详细说明,如模型参数、大小、运行命令等信息。
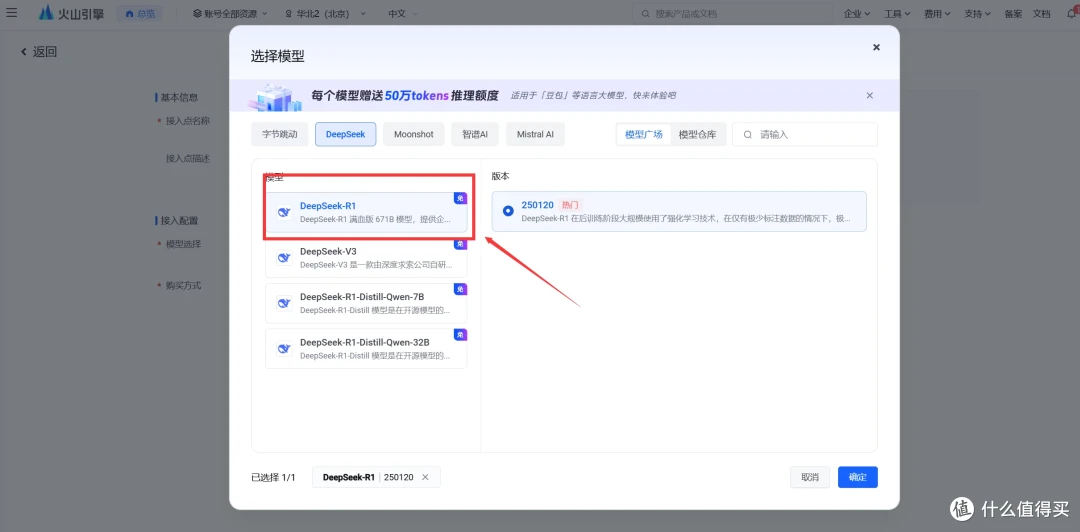
下载模型命令
使用ollama pull命令进行下载。例如,若要下载图片中的deepseek - r1 7b 模型,在命令行中输入
ollama pull deepseek-r1:7b
(若不指定具体版本如 7b 等,默认下载最新版本)。首次使用该命令运行模型时,ollama 也会自动从网上下载模型。
注意事项
下载速度可能受网络状况影响,如果网络不稳定,下载模型可能需要较长等待时间。
部分模型对硬件资源有一定要求,如运行较大的模型(像 llama3 - 70b)可能会较慢,甚至出现硬件资源不足无法正常运行的情况,下载前可了解模型对硬件的需求。(主要是系统内存的要求)
配置容器的网络设置,确保容器能够与外部进行通信。可以根据实际需求,设置容器的端口映射,使本地应用能够访问到容器内运行的 deepseek - r1 服务。
(三)启动和测试 deepseek-r1 服务
完成容器创建后,使用 docker 命令启动 deepseek - r1 容器。容器启动后,ollama 会自动加载 deepseek - r1 模型,并启动相关的服务进程。
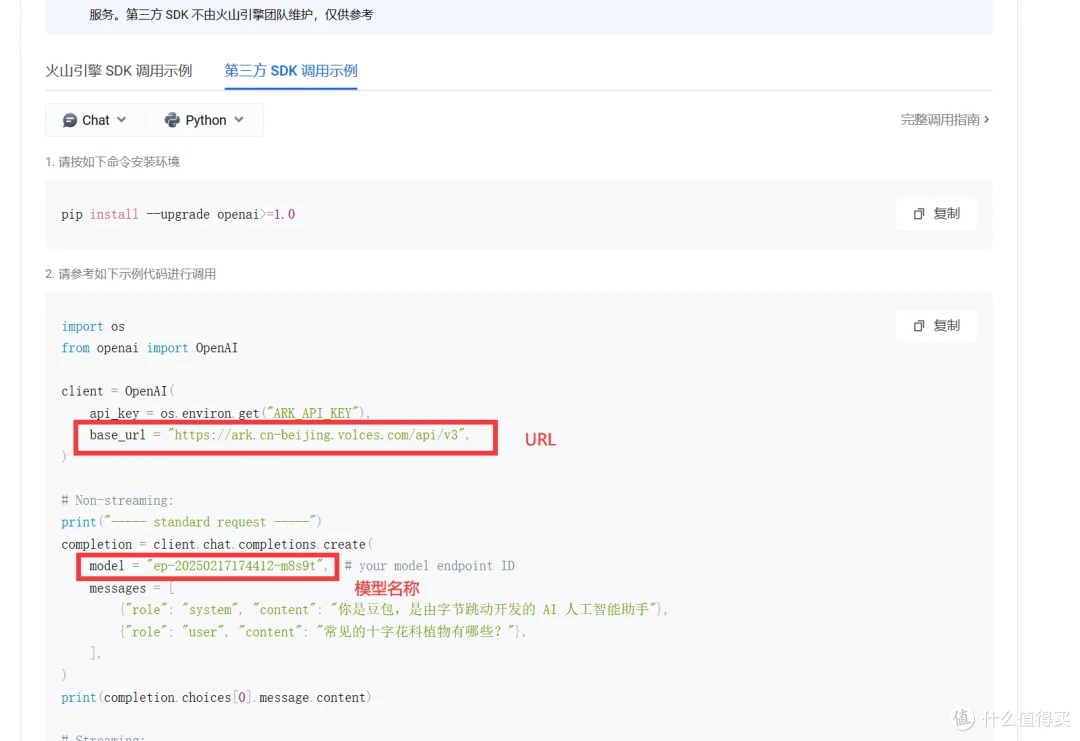
通过编写简单的测试脚本,向运行在容器内的 deepseek - r1 服务发送请求,验证模型是否正常工作。例如,可以发送一段文本,请求模型生成回答,检查返回的结果是否符合预期。
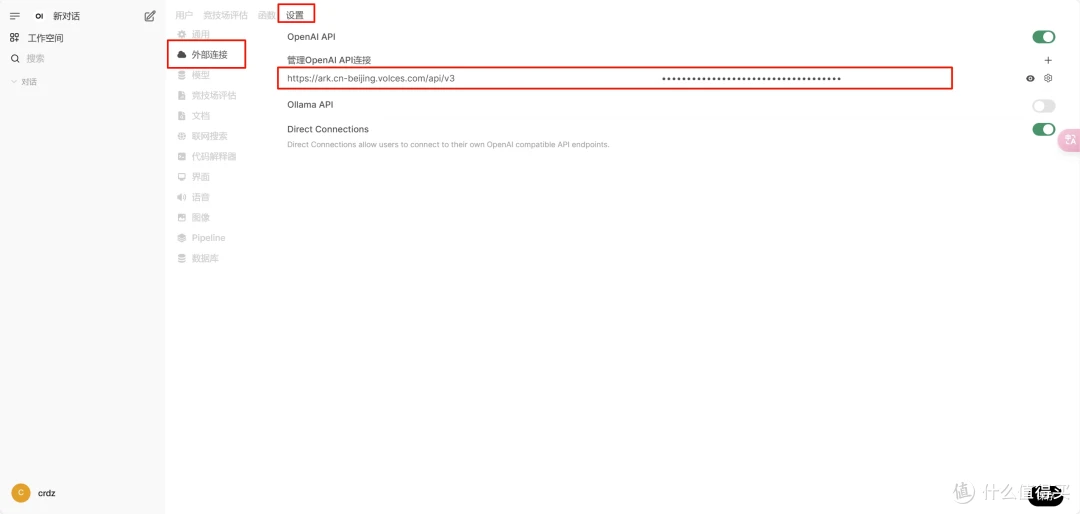
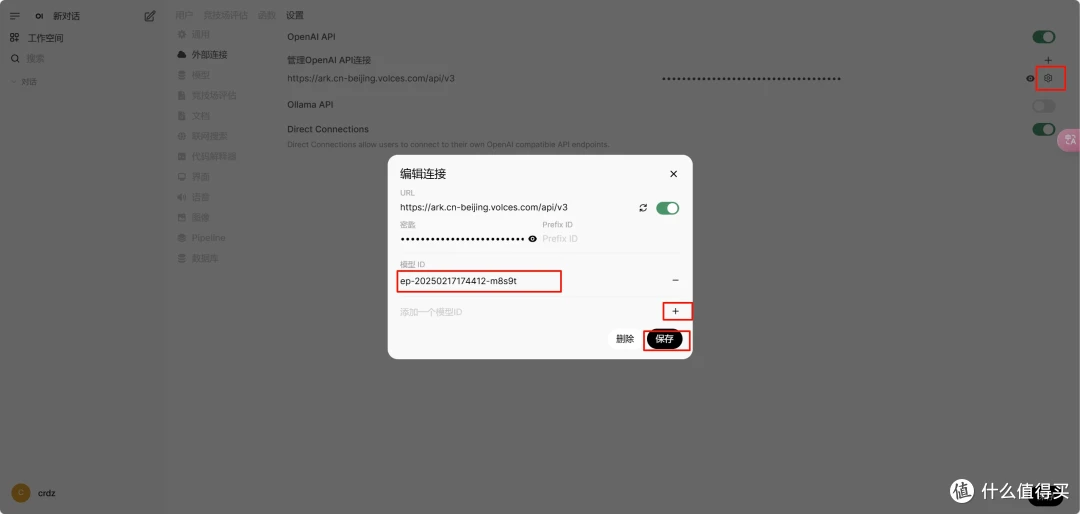
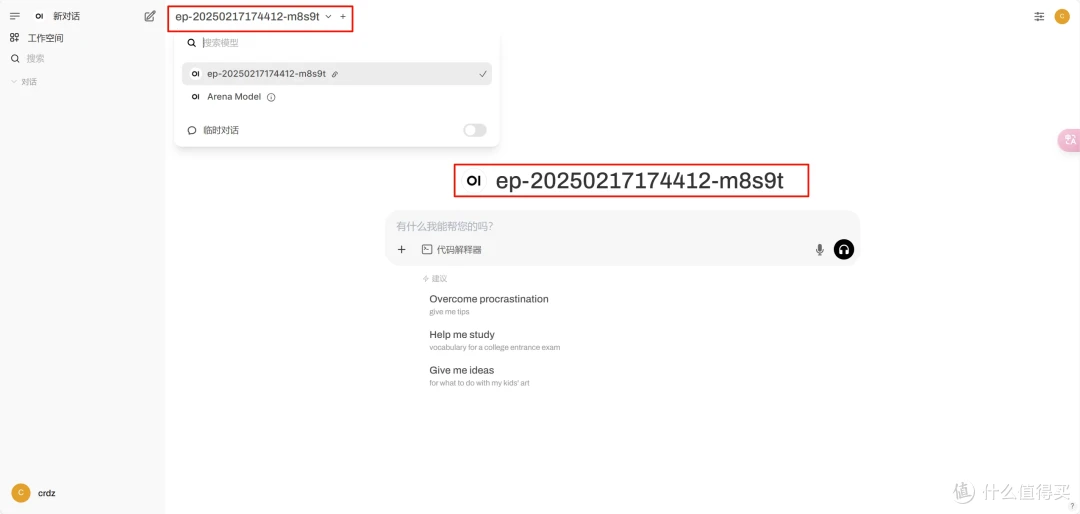
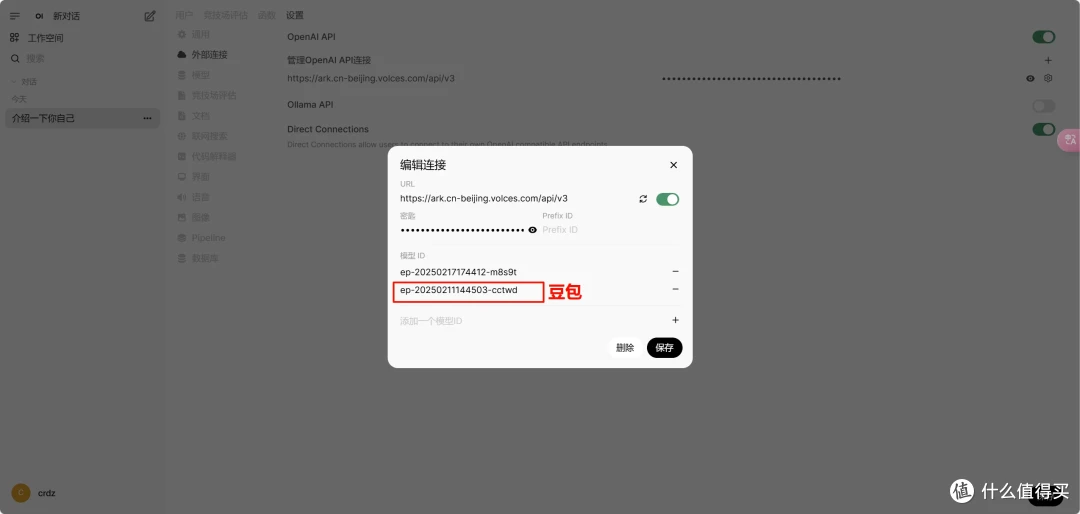
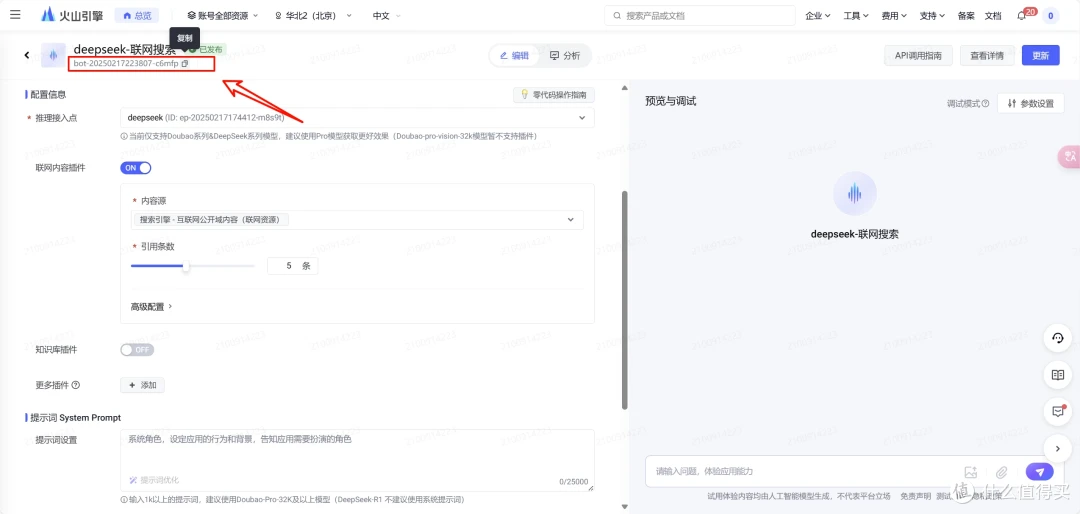
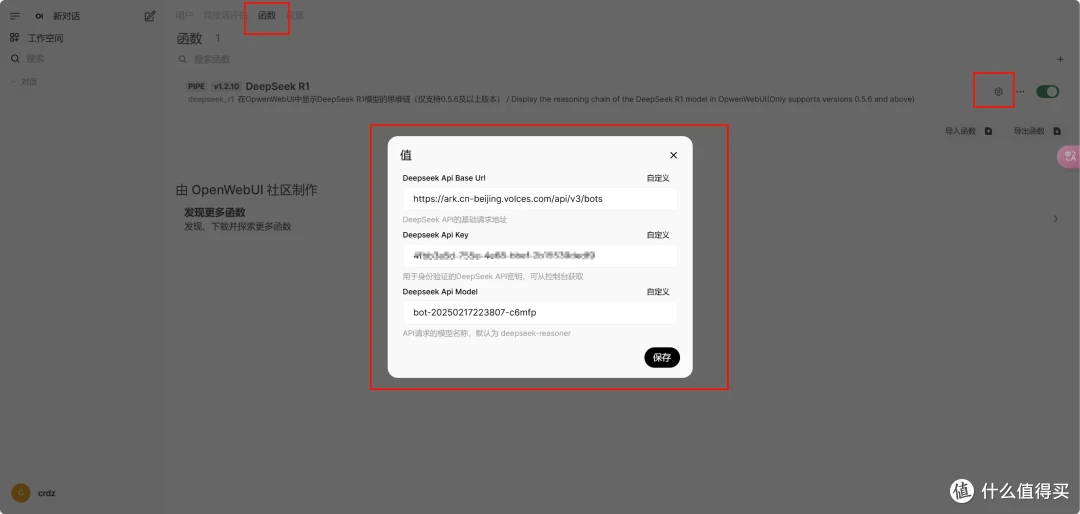
(四)WebUi的配置
搭建部署 Open WebUI 的方式
Docker方式(官网推荐)
Open WenUI 官网:GitHub - open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, ...)
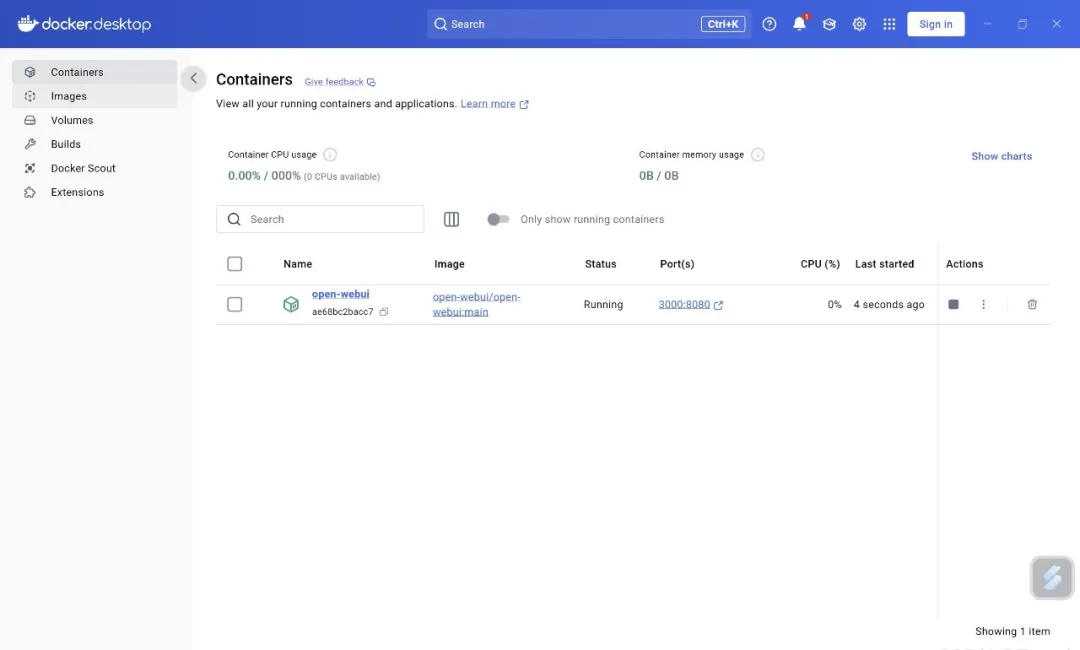
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v D:devopen-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
此命令启动一个docker容器
docker run:这是 Docker 用于运行容器的基本命令,它会根据指定的镜像创建并启动一个新的容器实例。-d:表示以守护进程(detached)模式运行容器,即容器会在后台运行,不会占用当前命令行终端的输入输出流,方便执行其他命令。-p 3000:8080:端口映射参数,将容器内部的 8080 端口映射到主机的 3000 端口。这样,通过访问主机的 3000 端口,就可以访问到容器内运行在 8080 端口上的open-webui应用。--add-host=host.docker.internal:host-gateway:此参数用于向容器内的/etc/hosts文件中添加一条主机映射记录,将host.docker.internal映射到host-gateway。这在容器需要与主机进行通信时非常有用,特别是在一些特殊网络环境下,使得容器能够通过host.docker.internal这个域名访问到主机。-v D:devopen-webui:/app/backend/data:这是卷挂载(volume mount)参数,将主机上的D:devopen-webui目录挂载到容器内的/app/backend/data目录。这意味着主机和容器可以共享这个目录下的文件,主机目录中的任何更改都会实时反映到容器内,反之亦然。常用于数据持久化或在容器和主机之间传递数据。--name open-webui:为运行的容器指定一个名称为open-webui,方便后续对容器进行管理和操作,例如使用docker stop open-webui停止容器,或docker start open-webui启动容器。--restart always:表示无论容器因为何种原因停止,Docker 都会自动尝试重新启动它,确保容器始终处于运行状态。ghcr.io/open-webui/open-webui:main:这是容器所使用的镜像名称和标签,指定从 GitHub Container Registry(ghcr.io)上拉取open-webui/open-webui镜像的main版本。如果本地没有该镜像,Docker 会自动从指定的镜像仓库下载。
启动ollama容器
1.使用该命令启动CPU版运行本地AI模型
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
2.此命令用于启动GPU版本运行AI模型
前提是笔记本已配置NVIDIA的GPU驱动,可在shell中输入nvidia-smi查看详细情况
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama

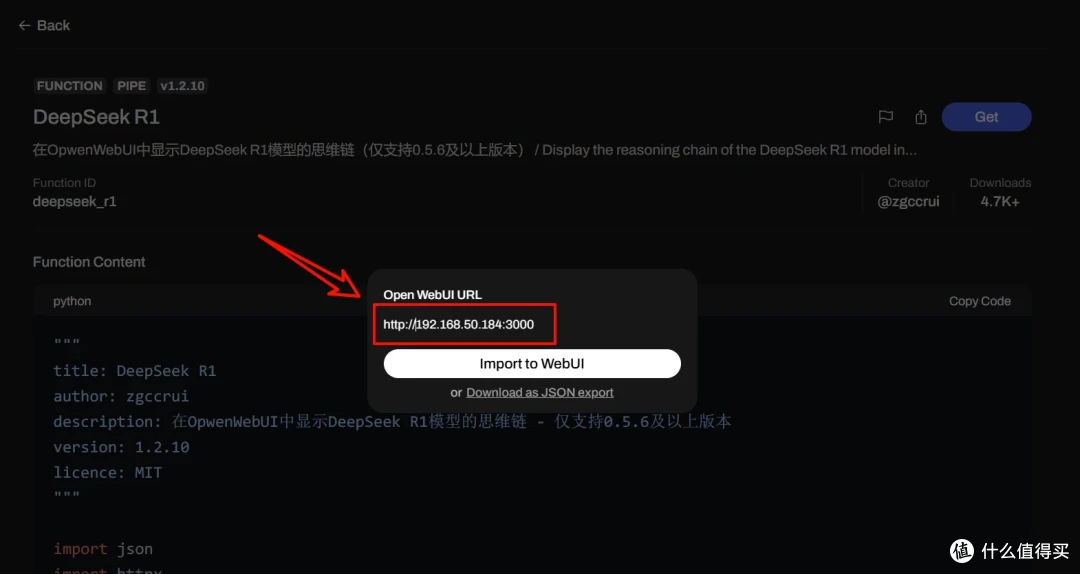
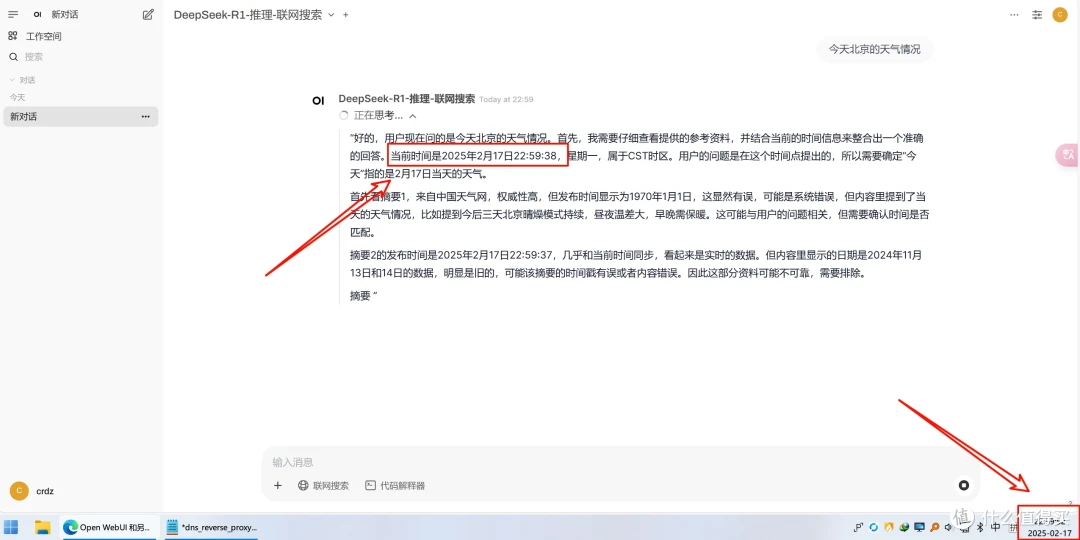
然后就可以访问docker中给出的open webui的地址启动web界面,选择好模型就可以进行问答对话了,恭喜你拥有了自己的AI小助手!
四、这种配置方式的优势
(一)快速部署
ollama 和 docker 的结合,大大缩短了 deepseek - r1 的部署时间。通过简单的命令行操作,即可完成模型的获取和容器的创建,相比传统的手动配置方式,效率得到了极大提升。
(二)环境隔离
docker 的容器化技术实现了环境的隔离,使得 deepseek - r1 在独立的环境中运行,不会受到本地系统其他软件的干扰。同时,也方便对模型进行版本管理和维护,当需要更新或切换模型版本时,只需要重新创建或更新容器即可。
(三)易于扩展
在后续的应用中,如果需要增加模型的计算资源,或者部署多个 deepseek - r1 实例,可以轻松地通过 docker 的集群管理功能进行扩展。ollama 也能够方便地管理多个模型之间的协同工作,满足不同业务场景的需求。
五、可能遇到的问题及解决方法
(一)网络问题
在下载模型或容器通信过程中,可能会遇到网络不稳定的情况。解决方法是检查网络连接,尝试更换网络环境或使用代理服务器。同时,ollama 和 docker 都提供了相关的网络配置选项,可以根据实际情况进行调整。
(二)资源冲突
当本地系统中已经运行了其他占用端口或资源的服务时,可能会与 deepseek - r1 容器产生冲突。可以通过修改容器的端口映射或调整本地服务的配置,来避免资源冲突。
利用 ollama 和 docker 配置 deepseek - r1 实现 DeepSeek 本机部署,为我们提供了一种高效、便捷且稳定的部署方式。随着人工智能技术的不断发展,这种基于容器化和模型管理工具的部署方法,将在更多的应用场景中发挥重要作用,推动大语言模型技术在本地开发和应用中的普及。
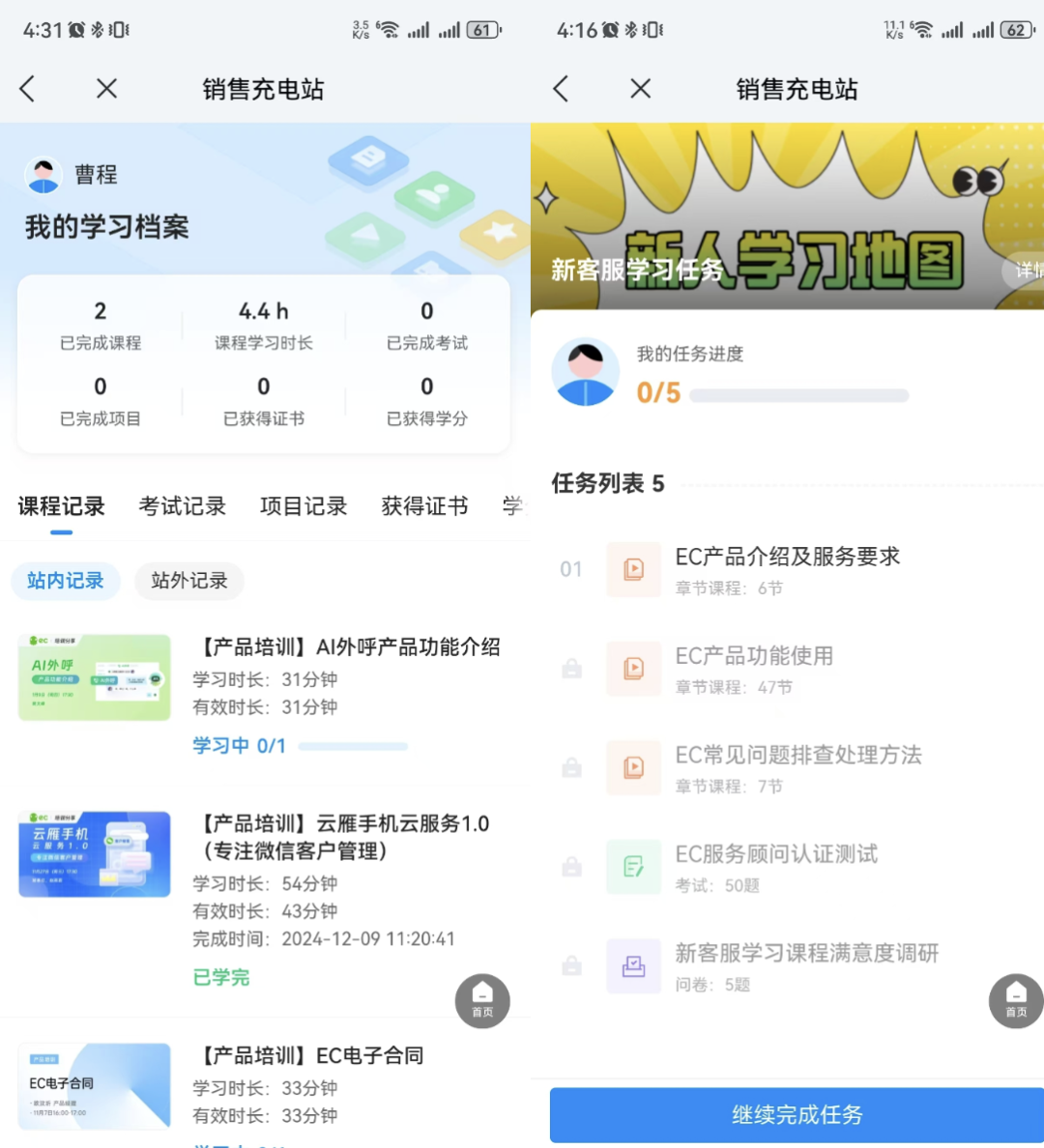
 销售充电站知识库界面
销售充电站知识库界面