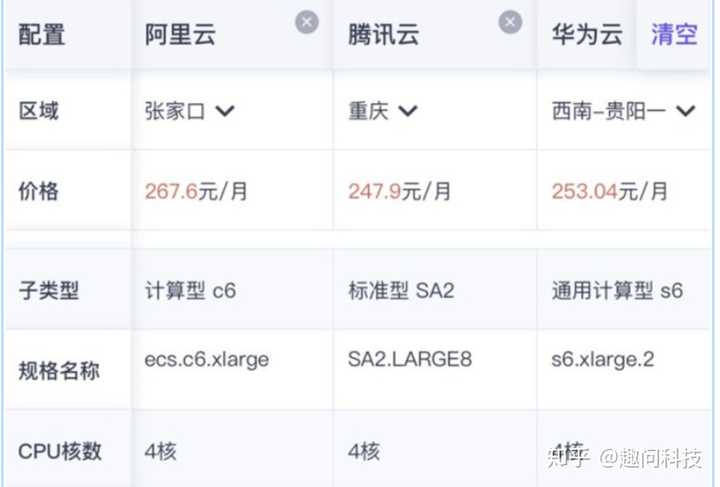
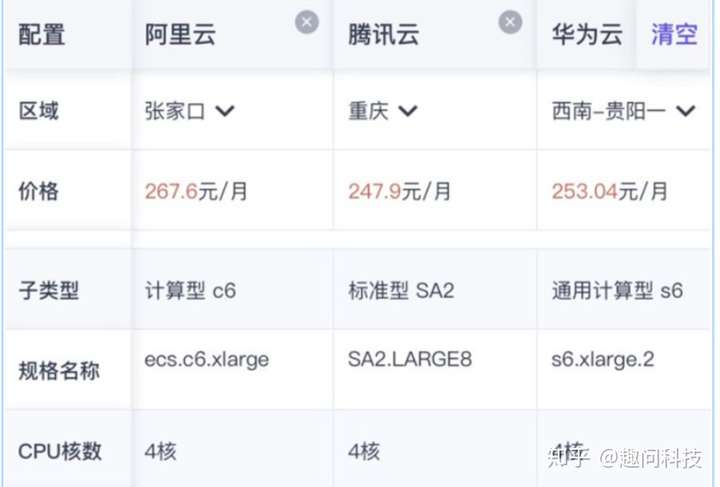
1.概述
1.1 简介
本文主要介绍中小型互联网企业,从本地机房迁移数据库到腾讯云的实践方法。其中包含了详细数据库迁移的方法和步骤,并且增加了实践演练和验证。实践与验证部分内容以常见的 Discuz! 论坛迁移上云做为案例。
1.2 相关概念
CVM:Cloud Virtual Machine 云服务器,在本文中代指腾讯云服务器。
CDB:Cloud Database云数据库,在本文中代指腾讯云数据库 Mysql。
TencentDB for Mysql:腾讯云基于开源数据库 MySQL 专业打造的高性能分布式数据存储服务,让用户能够在云中更轻松地设置、操作和扩展关系数据库。
DTS:Data Transmission Service(数据传输服务),支持 MySQL、MariaDB、PostgreSQL、Redis、MongoDB 等多种关系型数据库及 NoSQL 数据库迁移,可帮助用户在业务不停服的前提下轻松完成数据库迁移上云,利用实时同步通道轻松构建高可用的数据库容灾架构,通过数据订阅来满足商业数据挖掘、业务异步解耦等场景需求。
源数据库:简称源库,本文中代指准备迁移的IDC自建数据库。
目标数据库:简称目标库,本文中代指迁移的目标云数据库。
2.云化业务系统架构设计
 IDC业务迁移上云架构设计图例
IDC业务迁移上云架构设计图例
3.业务环境部署
下图展示了一个标准的 IDC 业务架构,此架构作为业务迁移前的标准架构,具体部署方式以实际用户的情况为准。
 IDC业务架构示例
IDC业务架构示例
4.服务器迁移
根据业务需求,迁移服务器到云上CVM云服务器中。通过云CVM业务访问本地IDC机房数据库(需考虑网络延迟)或者访问云上新建数据库(仅包含测试数据),验证应用服务迁移成功。本文使用一次性割接方案,切割前使用云服务器访问云数据库进行测试和验证。
具体实现细节不在本章详细展开,略。
 IDC服务器迁移CVM架构示例
IDC服务器迁移CVM架构示例
5.数据库迁移
本章节会详细介绍 IDC 自建数据库迁移到云上 CDB的方法和步骤。
 数据库迁移架构图示
数据库迁移架构图示
5.1 迁移流程概览
5.1.1 DTS迁移数据库流程原理图示
 DTS数据库迁移原理图
DTS数据库迁移原理图
5.1.2 DTS数据传输步骤概览
使用DTS数据传输服务完成数据库迁移上云,主要步骤如下图:
 数据库迁移步骤概览
数据库迁移步骤概览
5.1.1 DTS 迁移原理
对 IDC 自建数据库和云数据库 CDB 环境进行检查,打开防火墙,使 CDB 能够访问到 IDC 网络中的自建数据库。
利用 mydumper 工具从自建数据库导出 SQL 备份文件到中转机器。
将 SQL 备份文件导入到 CDB 中。
将 CDB 和自建数据建立主从关系,同步增量数据。
等主从同步完成,进行数据抽样对比。
用户主动断开主从,迁移完成,关闭 DFW 防火墙。
DTS 数据迁移任务包含冷备数据导出、增量数据同步两步骤。其中,冷备数据导出以及迁移后的数据对比过程会对源库负载产生一定的影响,建议在业务低峰期或在备库上进行数据迁移。
5.2 数据库迁移准备
5.2.1 网络规划
源数据库网络(本案例中的表格内容,均为案例的示例):
地域 | 公网 | 内网 | 源数据库地址 | 功能描述 | 关联系统名称 |
|---|
广州 | xx.xx.19.203 | 10.0.30.73 | xx.xx.19.203:3306 | 本地IDC数据库所在网络 | Discuz论坛 |
地域 公网 内网 源数据库地址 功能描述 关联系统名称
目标数据库网络:
地域 | VPC | subnet | AZ | 功能描述 | 关联系统名称 |
|---|
广州 | DefaultVPC | 广州3区 10.0.30.64/26 | 主广州3区/备广州4区 | 云数据库所在私有网络 | Discuz论坛 |
5.5.2 目标云数据库架构规划
实例名称 | 数据库类型即版本 | 架构 | 源库读写比例 | 源库读写分离 | 配合规格 | 硬盘 | 备份空间 |
|---|
Discuz数据库 | MySQL 5.6 | 高可用版一主一从 | 3:1 | 否 | 4核CPU 8G内存 | 100G | 每天备份,保存7天 |
5.2.3 云数据库参数规划
实例名称 | character_set_database | lower_case_table_names | binlog_format | tx_isolation | sql_mode | wait_timeout/interactive_timeout |
|---|
Discuz数据库 | utf8mb4(与源库保持一致) | 0 | ROW | READ-COMMITTED | NO_ENGINE_SUBSTITUTION(与源库保持一致) | 3600 |
5.2.4 安全组规划
根据访问数据库的来源IP,来规划数据库安全组设置。
实例名称 | 访问来源IP | 访问端口 | 访问协议 | 访问策略 | 关联系统名称 |
|---|
Discuz数据库 | 10.0.30.64/26 | 3306 | TCP | 允许 | Discuz论坛 |
5.3 购买与配置云数据库
根据规划的实例配置与网络信息,购买部署云上数据库资源。如果使用已购买的实例,建议针对规格配置、网络等进行二次检查和调整,同时需要先清空目标云数据库的数据,再进行正式的数据迁移,避免数据冲突导致迁移失败。
5.3.1 购买云数据库实例(可选,如已购买请跳过)
步骤1 点击如下链接,创建云数据库所在私有网络子网(本文中的截图均为案例示例)。
链接:https://console.cloud.tencent.com/vpc/subnet?rid=1
 创建私有网络子网
创建私有网络子网
步骤2 登录腾讯云官方网站,进入控制台,选择云数据库 MySQL。
链接:https://console.cloud.tencent.com/cdb
步骤3 选择广州地域,点击【新建】按钮,进入购买页面。
 新建Mysql实例
新建Mysql实例
步骤4 根据规划的云数据库网络和架构,进行初始参数的选择,案例示例如下:
 新建Mysql实例
新建Mysql实例
 新建Mysql实例
新建Mysql实例
根据页面提示,选择【新建安全组】或者选择已经存在的安全组。
 新建Mysql实例
新建Mysql实例
 新建安全组
新建安全组
 新建安全组
新建安全组
阅读云数据库服务条款,确定无误之后,点击“立即购买”,检查完账单信息并完成支付即可。
 新建Mysql实例
新建Mysql实例
步骤5 购买成功后,进入Mysql控制台,等待发货完成,如下图。
 Mysql控制台
Mysql控制台
步骤6 发货完成之后,点击数据库信息栏右侧的【初始化】,配置数据库参数,点击【确定】开始初始化操作。
各参数说明:
本案例中使用的设置如下:
参数名 | 值 |
|---|
字符集 | UTF8MB4 |
表名大小写敏感 | 开启,区分大小写 |
内网端口 | 3306 |
root帐号密码 | xxx |
效果如下图:
 实例初始化
实例初始化
5.3.2 设置云数据库参数
进入云数据库 MySQL 的控制台,依次点击:【管理】-【数据库管理】-【参数设置】,进行其他参数的设置。
本案例中调整的参数如下表:
参数 | 值 |
|---|
binlog_format | ROW |
tx_isolation | READ-COMMITTED |
sql_mode | NO_ENGINE_SUBSTITUTION |
wait_timeout/interactive_timeout | 3600 |
 参数设置
参数设置
 参数设置
参数设置
 参数设置
参数设置
5.4 源库迁移前的检查与配置
说明:由于不同版本的迁移工具检查项会有差异,本案例以 5.6 版本为例,其他版本以实际迁移时的检查内容为准。
步骤1 整实例迁移的目标 CDB 必须是空库,如果不为空,例如含有测试数据,请先清空目标实例,再进行迁移。
检查源库版本:
mysql> show variables like "version";
 源库操作示例
源库操作示例
步骤2 版本检查,目前仅支持同版本迁移(5.1/5.5/5.6/5.7),以及5.1->5.5,5.5->5.6迁移。此次迁移为5.6->5.6,满足要求。
步骤3 检查目标库的容量,必须大于源实例。
步骤4 在源库上创建迁移专用的账号(也可以使用权限符合要求的现有账号),建议赋予ALL PRIVILEGES权限,可以使用如下命令操作:
mysql> GRANT ALL PRIVILEGES ON *.* TO "迁移账号"@"%" IDENTIFIED BY "迁移密码";mysql> FLUSH PRIVILEGES;
 源库操作示例
源库操作示例
步骤5 确认源库全局变量,使用参数的目标值如下所示:
lower_case_table_names=0; 根据需要设置源与目标一致;
server_id=1000; 根据需要与目标库设置为不同值,且不为1;
log_bin = ON; 必须为ON;binlog_format=ROW; 必须为ROW;binlog_row_image = FULL; 必须为FULL;innodb_stats_on_metadata = OFF; 必须为OFF;wait_timeout = 3600; 根据需要设置 [3600,7200)范围内;
interactive_timeout = 3600; 根据需要设置与wait_timeout一致;
character_set_database = UTF8MB4; 根据需要设置源与目标一致;
tx_isolation = 'READ-COMMITTED'; 根据需要设置源与目标一致;
sql_mode = 'NO_ENGINE_SUBSTITUTION'; 根据需要设置源与目标一致;
max_allowed_packet=1073741824; 需大于等于1073741824。
 源库操作示例
源库操作示例
步骤6 开启源库二进制日志文件。
修改源库配置文件my.cnf,增加log-bin 参数,并重启数据库生效。
# vi /etc/my.cnf[mysqld]log-bin = [自定义文件名]# systemctl stop mysqld.service
# systemctl start mysqld.service
如下图所示,源库二进制日志已经开启。
 源库操作示例
源库操作示例
步骤7 其余参数可以动态修改,使用set global <参数名> = <参数值>即可。
注:源库配置文件/etc/my.cnf中如果存在不同的值,建议一并修改配置文件,避免源库发生异常重启重置参数值导致迁移失败。
 源库操作示例
源库操作示例
步骤8 检查源库的表设置,腾讯云数据库 MySQL 目前仅支持 InnoDB 引擎。使用如下 SQL 在源库进行检查输出非InnoDB引擎表,并根据步骤9-10修改。如果不存在非InnoDB表,那么跳过9-10步骤。
mysql> SELECT table_schema, table_name,engine FROM information_schema.tables WHERE engine <> 'InnoDB' AND table_schema NOT IN ('mysql' ,'performance_schema','information_schema'); 源库操作示例
源库操作示例
步骤9 在源实例的低峰期,针对MEMORY引擎表修改为Innodb引擎(如不存在非InnoDB引擎表可跳过此步骤)。
扫描MEMORY引擎表,并进行修改。
mysql> SELECT table_schema, table_name,engine FROM information_schema.tables WHERE engine = 'MEMORY' AND table_schema NOT IN ('mysql' ,'performance_schema','information_schema');mysql> alter table xxx engine='InnoDB'; 源库操作示例
源库操作示例
经过修改,源库已经不存在memory 引擎表:
 源库操作示例
源库操作示例
步骤10 在源实例的业务低峰期,针对row_format=fixed 表修改为row_format=dynamic;
扫描row_format 为fixed的表,并修改为Dynamic。
mysql> SELECT table_schema,table_name,row_format from information_schema.tables where Row_format like '%fix%' AND table_schema NOT IN ('mysql','performance_schema','information_schema');mysql> alter table xxx row_format = Dynamic; 源库操作示例
源库操作示例
经过修改,已经不存在row_format 为fixed的表:
 源库操作示例
源库操作示例
 源库操作示例
源库操作示例
5.5 创建数据库迁移任务
步骤1 点击如下链接,进入DTS数据传输服务控制台。
链接:https://console.cloud.tencent.com/dts/migration
步骤2 点击【新建迁移任务】,选择【华南地区(广州)】购买数据传输服务,目前数据传输服务免费使用。
 创建数据迁移任务
创建数据迁移任务
 创建数据迁移任务
创建数据迁移任务
步骤3 根据页面指引,设置迁移任务和源库类型,并测试源库的连通性。
本案例中所采用的参数值如下表:
参数 | 案例参数取值 |
|---|
任务名称 | discus迁移 |
运行模式 | 立即执行 |
源库类型 | MySQL |
服务提供商 | 普通 |
接入类型 | 公网 |
所属地域 | 华南地区(广州) |
主机地址 | xx.xx.19.203 (源库地址) |
端口 | 3306 (源库访问端口) |
帐号 | migrate (源库上预先创建的迁移账号) |
密码 | xxx (源库迁移账号户的密码) |
 创建数据迁移任务
创建数据迁移任务
 创建数据迁移任务
创建数据迁移任务
根据提示的IP地址,修改源实例防火墙,放通地址xx.xx.84.254、xx.xx.198.143 的访问权限;同时确定源库迁移账号的 host 字段包含图中提示的IP地址 xx.xx.84.254、xx.xx.198.143,允许其访问。调整完之后,点击【重新测试】,直到连通性测试全部通过。
 创建数据迁移任务
创建数据迁移任务
步骤4 根据页面指引,选择目标库类型MySQL,并在数据库实例下拉列表中选择目标,点击【新建】。
 创建数据迁移任务
创建数据迁移任务
步骤5 设置所要迁移的数据库。点击【保存】,进行迁移前校验。各参数的意义如下:
 创建数据迁移任务
创建数据迁移任务
步骤6 迁移任务的校验结果,只有所有校验项通过后才能启动迁移任务。任务校验结果存在 3 种状态:
 创建数据迁移任务
创建数据迁移任务
5.6 数据迁移
步骤1 迁移校验完成页面点击【启动任务】或者是【数据传输】页面中找到迁移任务,点击【立即启动】->【确定】来开始数据迁移。如果设定了迁移任务的定时时间,则迁移任务会在设定的时间开始排队并执行,如果没有设置定时任务,则迁移任务会立即执行。
 启动数据库迁移任务
启动数据库迁移任务
 启动数据库迁移任务
启动数据库迁移任务
步骤2 在数据迁移页面,可以实时查看迁移的进度和状态。
如下图所示,迁移任务共有7个步骤,检查环境、参数配置、冷备份导出、冷备份导入(至此全量数据完成迁移)、同步构建、数据对比、数据同步中状态。
 查看数据迁移任务
查看数据迁移任务
查看任务状态为准备完成,目标与源库时间延迟为0秒,表示增量同步接近实时同步。
 查看数据迁移任务
查看数据迁移任务
5.7 数据一致性校验
同步追加无延迟时,进行一次手动的数据一致性校验。
步骤1 登入 Discuz 网站,模拟新用户注册,写入数据到源库中。
 Discuz!论坛注册用户
Discuz!论坛注册用户
 Discuz!论坛注册用户
Discuz!论坛注册用户
 Discuz!论坛注册用户
Discuz!论坛注册用户
步骤2 登入目标库,检查论坛的用户信息是否正确的同步了。论坛的用户信息在 discuz 库的 pre_ucenter_members 表中。
 登入云数据库
登入云数据库
 登入云数据库
登入云数据库
 登入云数据库
登入云数据库
5.8 云上业务测试与验证
完成数据校验之后,源库的数据已经迁移到云上,且正在实时同步。根据预先制定的方案,可对云上环境进行切换前测试和验证。
5.8.1 验证云服务器访问云数据库(只读测试)
登入云服务器,验证 discuz 账户访问云数据库 10.0.30.67 正常。使用 discuz 账户,从云服务器访问云数据库内网地址,验证正常。
 验证云服务器访问云数据库操作示例
验证云服务器访问云数据库操作示例
5.8.2 其他业务测试(写测试、可选)
根据业务需要,进行其他切换前测试。如果涉及写数据库操作,那么请查看本章节;如果不需要,本章节可跳过。
步骤1 写云数据库操作之前,需断开DTS同步状态。验证数据同步一致性完成后,在DTS数据迁移页面找到迁移任务,点击【完成】按钮,二次校验后点击【确定】,断开本地IDC机房数据库与云数据库的同步。
注意事项:点击【完成】按钮后,源库的数据变更不会在同步到目标库中,并且不支持重新同步,请谨慎操作。如果不进行任何写操作测试,那么请跳出5.8.2章节。
链接:https://console.cloud.tencent.com/dts/migration
 完成数据库迁移任务
完成数据库迁移任务
完成数据库迁移任务
刷新腾讯云控制台,监控迁移完成任务状态,直到任务成功。
 完成数据库迁移任务
完成数据库迁移任务
步骤2 根据测试案例,进行云上环境的完整验证和测试,包括云数据库的写入测试。具体测试用例以实际需求为准,本章节略。
步骤3 针对测试发现的问题,评估和解决,直到全部测试用例验收通过。
步骤4 验证完成后,需清空云数据库中的测试数据,准备再次发起数据迁移。
步骤5 从5.3章节【购买与配置云数据库实例】开始,正式进行数据迁移,直到5.8.1 完成只读测试。经过数据校验一致并且只读测试通过后,可以进行第6章生产环境的切换准备。
6.生产环境切换
请选择一个合理的时间来完成业务的平滑切换,关键系统需要准备回退方案,本案例使用一次切换的方案,即业务环境与数据库环境同时进行切换。
6.1 云服务器切换前准备
步骤1 验证云上服务器访问 DB 的地址为腾讯云数据库。如果访问的是其他数据库地址,请根据如下步骤进行修改:
先登入云服务器,依次修改三个配置文件的数据库地址,使其访问云数据库:
# cd /data/wwwroot/discuz/upload/# vi ./config/config_global.php
 云服务器操作示例
云服务器操作示例
# cd /data/wwwroot/discuz/upload/# vi ./config/config_ucenter.php
 云服务器操作示例
云服务器操作示例
# cd /data/wwwroot/discuz/upload/# vi ./uc_server/data/config.inc.php
 云服务器操作示例
云服务器操作示例
步骤2 通过浏览器访问云服务器公网地址,验证论坛访问正常,此时目标云数据库被 DTS 设置为 read_only 状态,因此会遇到如下报错:
 登入论坛操作示例
登入论坛操作示例
6.2 云数据库切换(此过程包含业务停机)
6.2.1 云数据库切换过程图示
 云数据库割接切换图示
云数据库割接切换图示
6.2.2 云数据库切换实施步骤
步骤1 停止对源数据库的写入(即停止业务服务)。登入源库,运行show master status,观察10分钟,确定 binlog 文件和位点没有更新,确认没有新数据写入。
设置 5.6 版本的源库为 read only 模式,禁止新数据写入,同时应避免应用帐号权限过大包含 super 权限导致写入数据(super 权限的账户,允许在 read only 模式下写入)。设置 read_only 的操作如下:set global read_only = ON;。
注意:本案例以 5.6 版本为例;如果源实例为 5.7版本,其支持设置super_read_only,禁止包括 super 权限的账户写入,更安全。
 云数据库割接-源库操作示例
云数据库割接-源库操作示例
步骤2 关闭源库(可选)。关闭数据库可以完全杜绝任何写入操作,但是本操作为高危操作,请谨慎执行。
步骤3 断开云数据库与源库的同步。点击数据传输页面的【完成】,并点击【确定】。
注意事项:点击【完成】按钮后,源库的数据变更不会在同步到目标库中,并且不支持重新同步,请谨慎操作。
链接:https://console.cloud.tencent.com/dts/migration
 云数据库割接-完成数据库迁移任务
云数据库割接-完成数据库迁移任务
 云数据库割接-完成数据库迁移任务
云数据库割接-完成数据库迁移任务
步骤4 刷新腾讯云控制台,检查迁移任务的状态,直到任务成功。
 云数据库割接-完成数据库迁移任务
云数据库割接-完成数据库迁移任务
 云数据库割接-完成数据库迁移任务
云数据库割接-完成数据库迁移任务
此时目标库会自动切换为可读可写状态。
 云数据库割接-云数据库操作示例
云数据库割接-云数据库操作示例
步骤5 登入云服务器业务环境的公网地址,验证论坛访问是否正常。
 云数据库割接验证
云数据库割接验证
注册一个新账号 cutover,验证写入成功。
 云数据库割接验证
云数据库割接验证
 云数据库割接验证
云数据库割接验证
步骤6 交付给 QA 进行切换后的验收测试阶段(全量测试),同时观察目标库的运行情况。验收通过之后,进行6.3章节正式业务切换,如果验收异常,那么进行6.4迁移回滚。
6.3 正式业务切换(此时业务恢复)
修改业务公网域名的 DNS 信息,指向云主机公网地址,切换正式业务的流量到云上,并观察至少 2 小时,确认业务系统和云数据库均正常运行。
 业务割接图示
业务割接图示
6.4 云数据库切换失败回滚方案(可选)
注意事项:本章节仅用于切换数据库失败场景的回滚方案。如果云数据库切换后,业务一切正常,那么不需要执行本步骤。
 割接失败回滚图示
割接失败回滚图示
步骤1 启动源库(可选)。
如果没有执行关闭源库的动作,那么跳过此步骤。
步骤2 关闭源库只读设置,修改全局参数read_only=OFF。可以使用如下命令:
set global read_only = OFF;
 割接回滚-源库操作示例
割接回滚-源库操作示例
步骤3 验证测试自建 IDC 的应用可以正常访问。
 割接回滚-业务验证
割接回滚-业务验证
步骤4 进行用例测试,确保测试用例全部通过验收。
步骤5 修改业务DNS域名指向自建IDC机房应用服务器公网地址。开启业务访问,恢复业务。
步骤6 复盘切换失败原因和解决方案,并重新安排时间窗口进行云数据库迁移。
原创声明,本文系作者授权云+社区发表,未经许可,不得转载。
如有侵权,请联系 yunjia_community@tencent.com 删除。