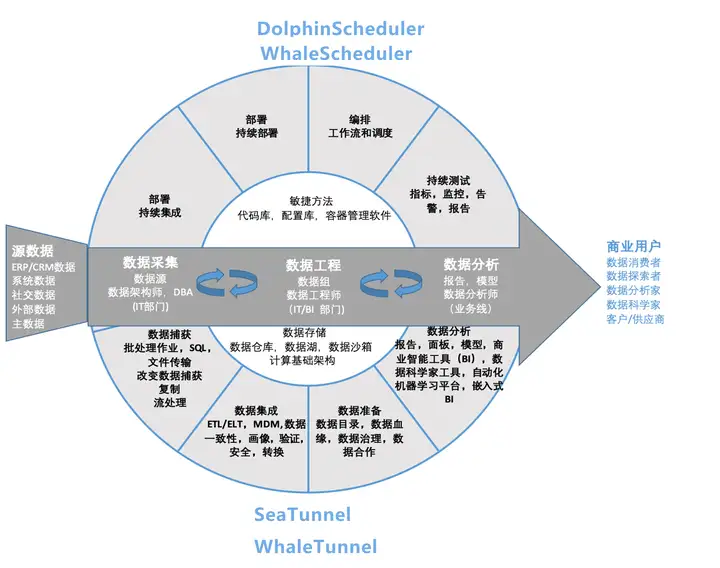
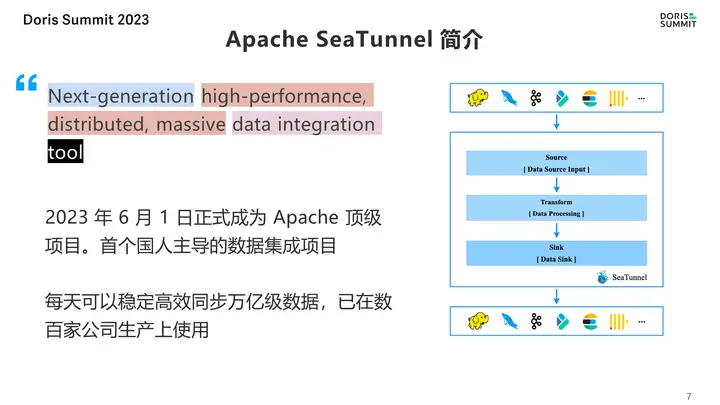
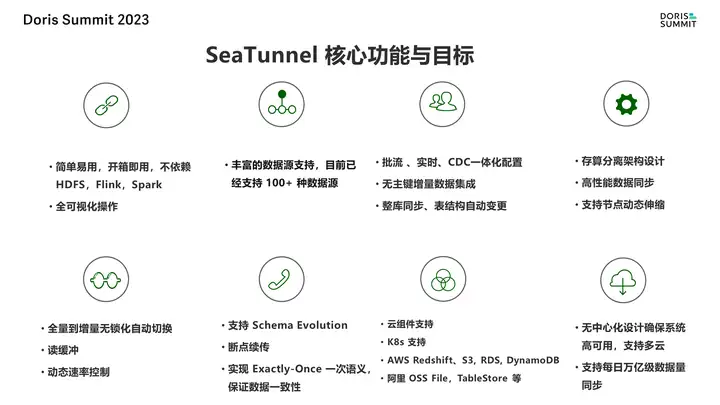
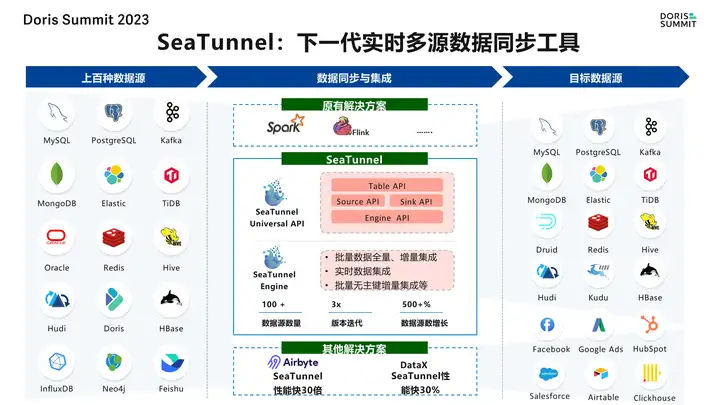
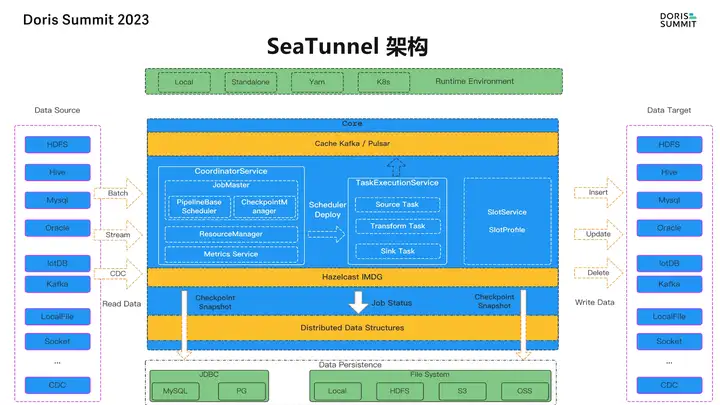
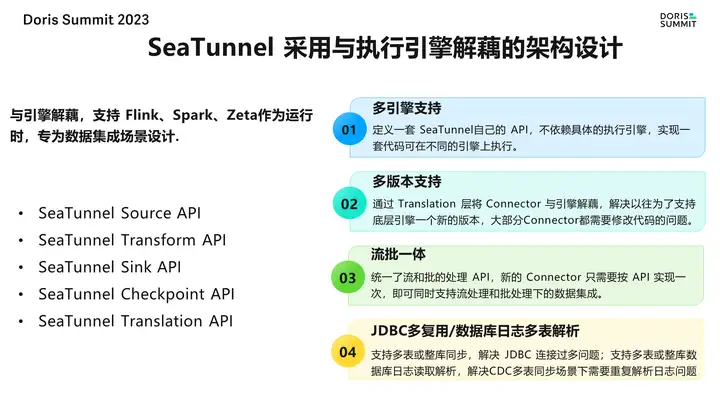
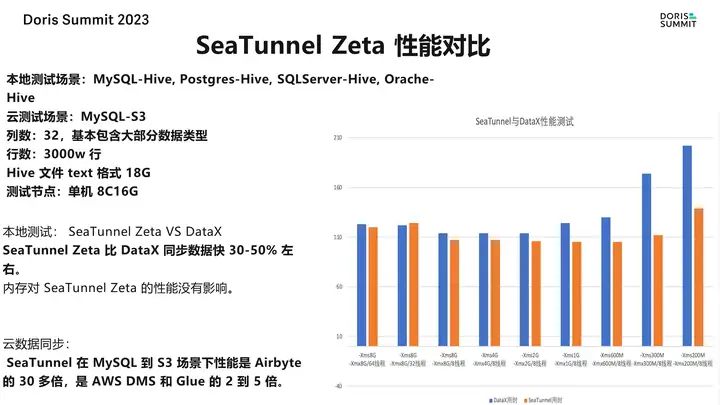
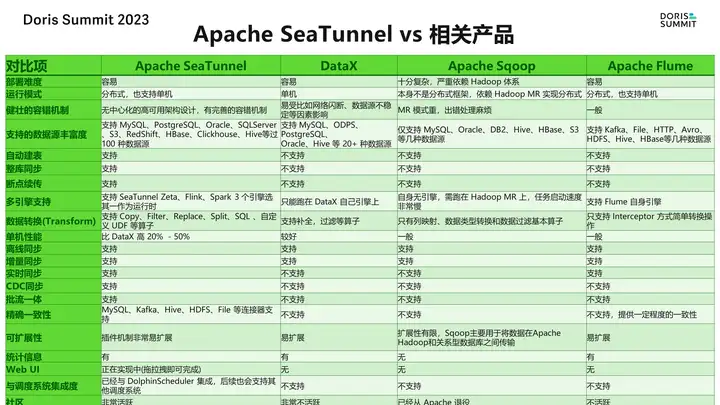
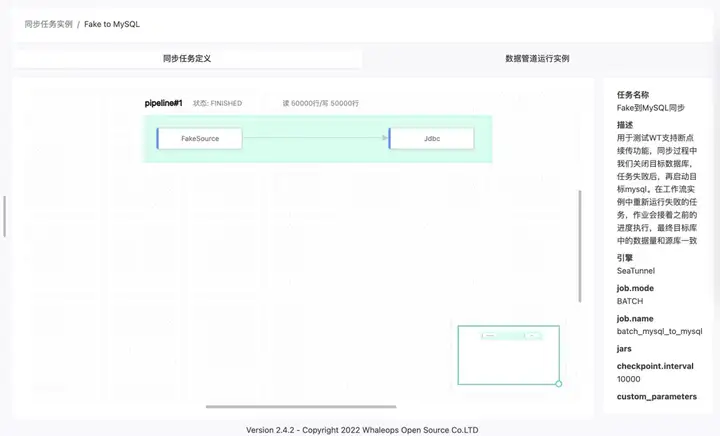
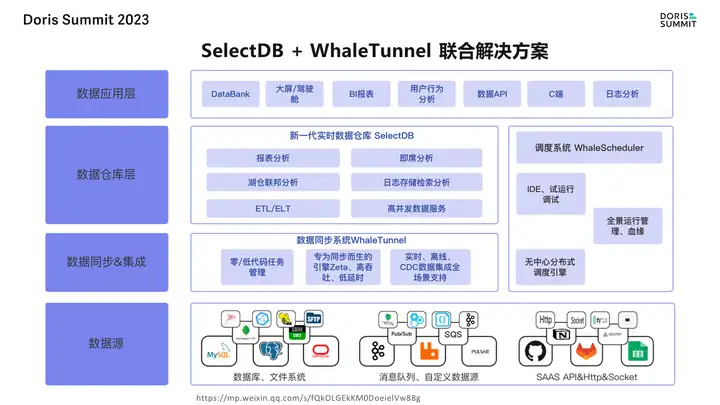
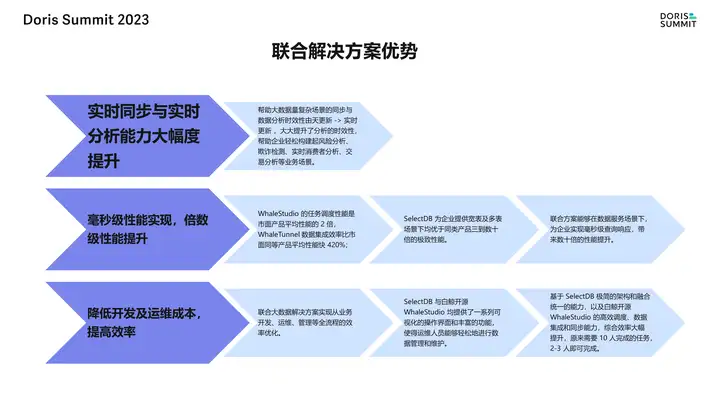
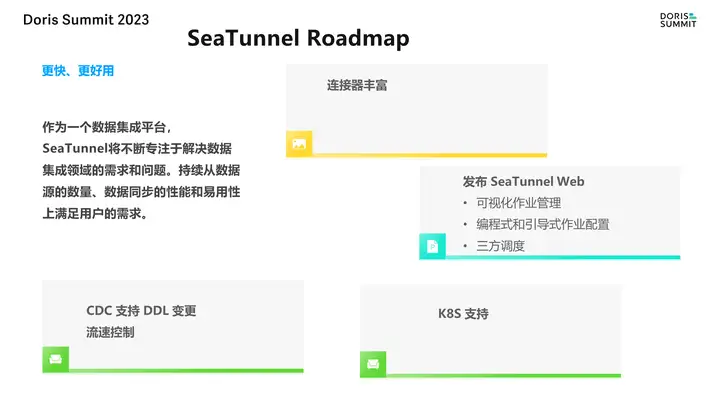
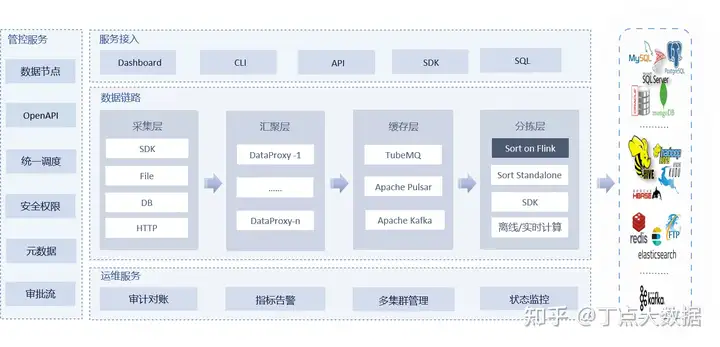
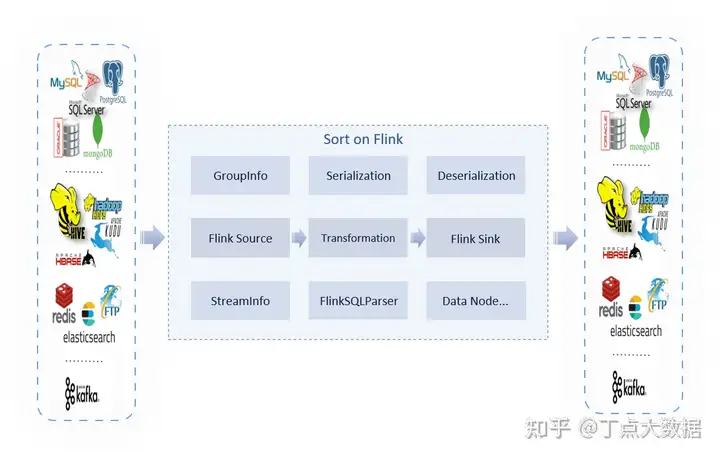
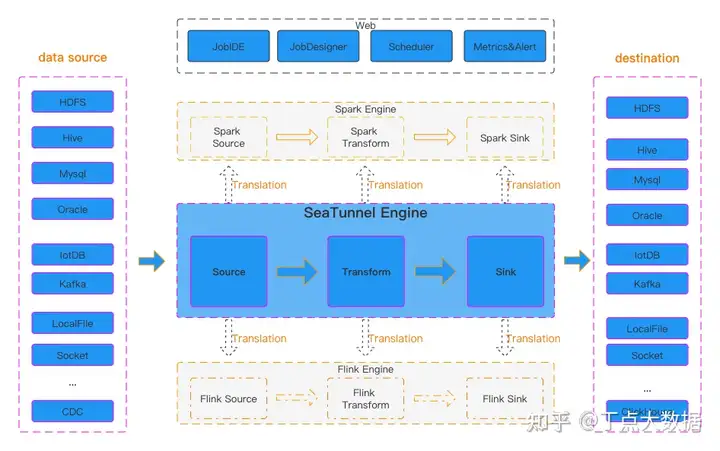
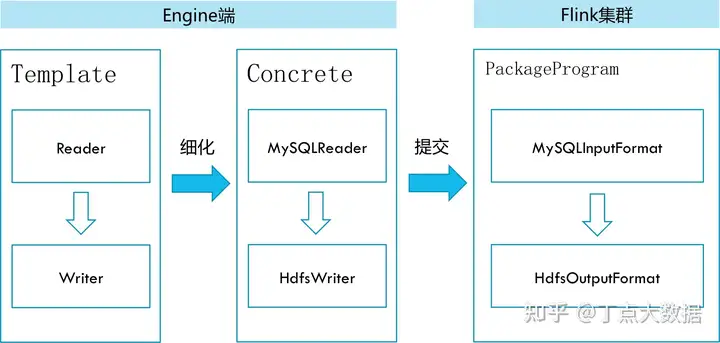
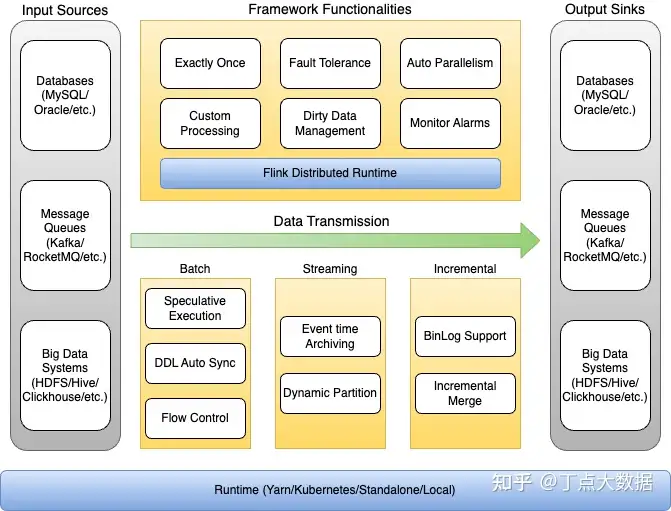
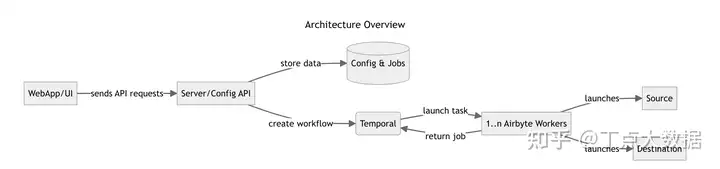
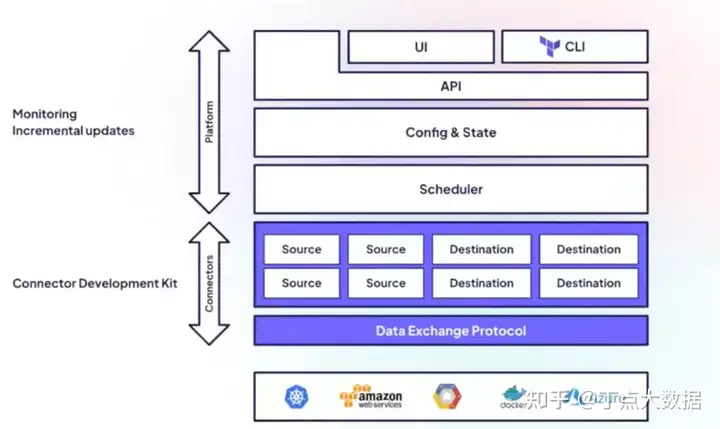
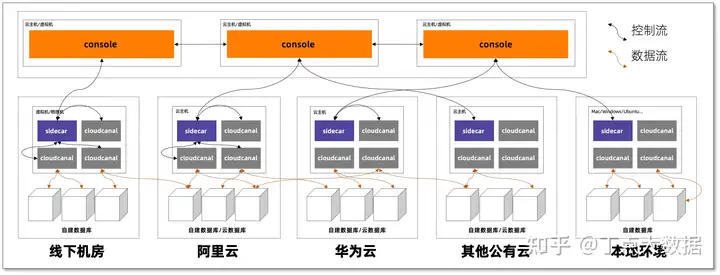
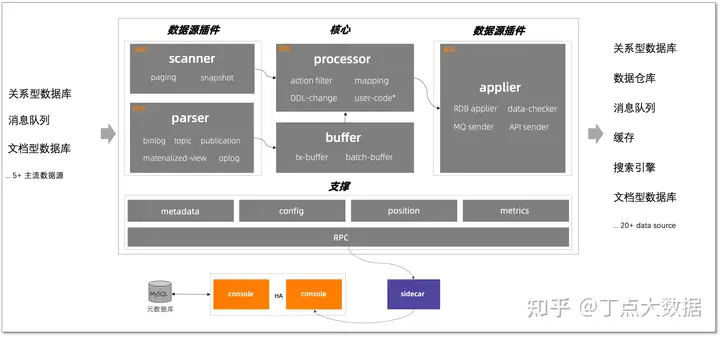
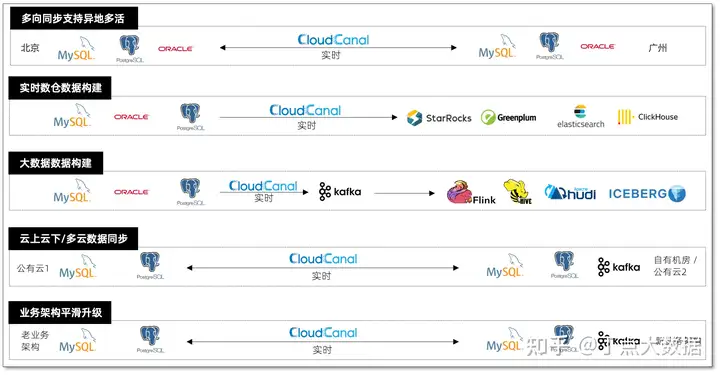
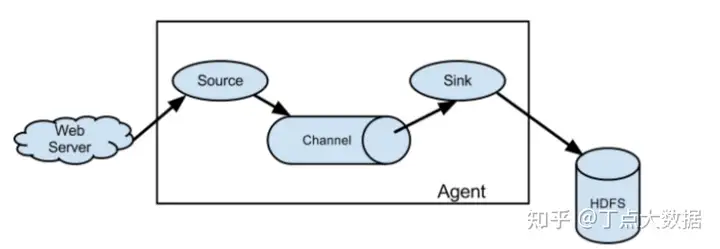
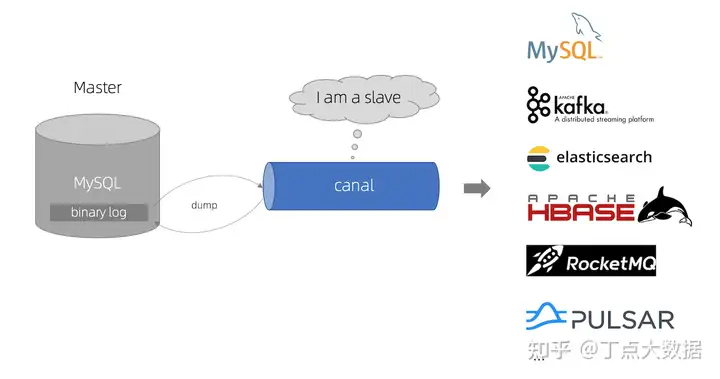
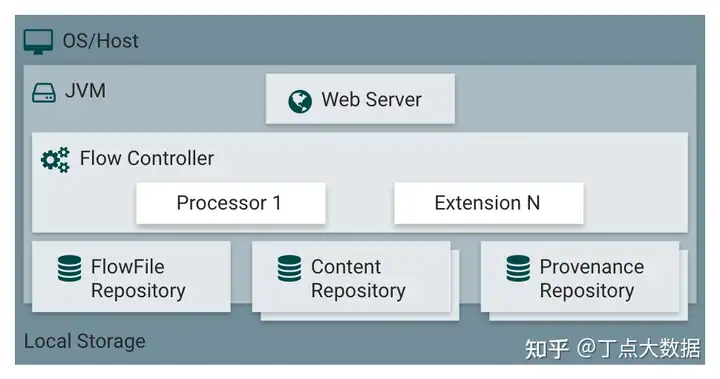
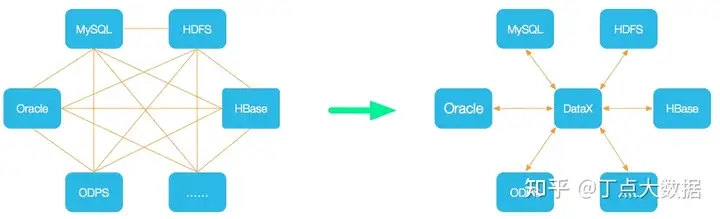
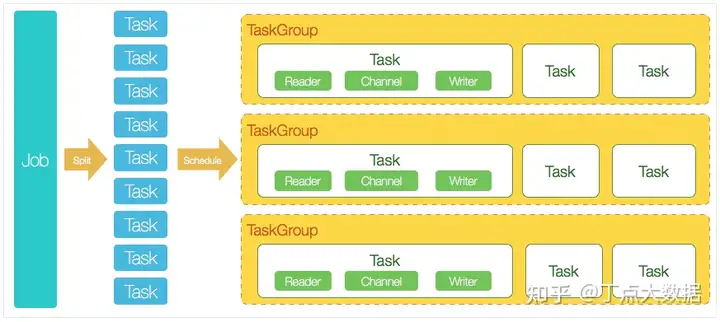
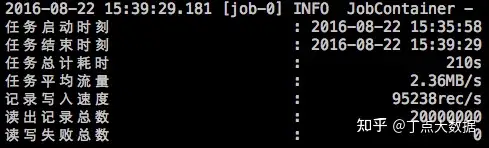
豆包自动生产1000本推荐书单
以下是一份包含各类优秀书籍的 1000 本书单示例,但这只是一个宽泛的推荐,你可以根据自己的兴趣和需求进行选择:
1. 文学名著类:
- 中国文学:
- 《红楼梦》曹雪芹:中国古典小说的巅峰之作,以贾、史、王、薛四大家族的兴衰为背景,展现了封建社会的人生百态。
- 《三国演义》罗贯中:描绘了三国时期的政治、军事斗争,塑造了众多鲜明的人物形象。
- 《水浒传》施耐庵、罗贯中:讲述了梁山好汉的故事,反映了当时的社会矛盾和人民的反抗精神。
- 《西游记》吴承恩:充满奇幻色彩的长篇小说,讲述了唐僧师徒四人西天取经的经历。
- 《活着》余华:以平实的文字叙述了主人公福贵悲惨的一生,展现了人性的坚韧和生命的意义。
- 《平凡的世界》路遥:描绘了 20 世纪 70 年代到 80 年代中国农村的变迁,刻画了众多平凡人的奋斗历程。
- 《白鹿原》陈忠实:以陕西关中地区白鹿原上白鹿村为缩影,展现了中国近代农村的历史变迁。
- 《围城》钱钟书:以幽默的笔触讽刺了知识分子的生活和人性的弱点。
- 《呼兰河传》萧红:记录了东北小城呼兰河的风土人情以及作者的童年生活。
- 《狂人日记》鲁迅:中国现代文学史上第一篇白话小说,具有深刻的思想内涵和批判精神。
- 外国文学:
- 《百年孤独》加西亚·马尔克斯:拉丁美洲魔幻现实主义文学的代表作,讲述了布恩迪亚家族七代人的传奇故事。
- 《战争与和平》列夫·托尔斯泰:以 19 世纪俄国历史为背景,展现了战争的残酷和人性的美好。
- 《安娜·卡列尼娜》列夫·托尔斯泰:探讨了爱情、婚姻、家庭等主题,塑造了安娜这一经典的女性形象。
- 《巴黎圣母院》维克多·雨果:通过描写巴黎圣母院副主教克洛德和吉普赛女郎埃斯梅拉达的故事,展现了美与丑、善与恶的对比。
- 《悲惨世界》维克多·雨果:描绘了法国社会的广阔画面,展现了人性的光辉和救赎。
- 《傲慢与偏见》简·奥斯汀:以英国乡绅阶层的日常生活为背景,讲述了伊丽莎白和达西之间的爱情故事。
- 《呼啸山庄》艾米莉·勃朗特:充满激情和复仇的爱情悲剧,具有强烈的艺术感染力。
- 《红与黑》司汤达:反映了法国 19 世纪社会的阶级矛盾和个人奋斗。
- 《高老头》巴尔扎克:揭露了资本主义社会金钱的罪恶和人与人之间的冷漠。
- 《简·爱》夏洛蒂·勃朗特:讲述了简·爱自尊自爱、追求平等爱情的故事。
- 《堂吉诃德》塞万提斯:一部反骑士小说的骑士小说,充满了幽默和讽刺。
- 《罪与罚》陀思妥耶夫斯基:探讨了人性的善恶、道德与法律等问题。
- 《卡拉马佐夫兄弟》陀思妥耶夫斯基:深刻揭示了人性的复杂性和宗教哲学问题。
- 《了不起的盖茨比》弗朗西斯·斯科特·菲茨杰拉德:描绘了美国 20 世纪 20 年代的社会风貌和人们的梦想与幻灭。
- 《老人与海》海明威:通过老渔夫桑迪亚哥与大鱼搏斗的故事,展现了人类的勇气和毅力。
- 《麦田里的守望者》J.D.塞林格:反映了青少年的成长困惑和对社会的不满。
- 《小王子》安托万·德·圣-埃克苏佩里:以儿童的视角探讨了人生的真谛和爱的意义。
2. 哲学思想类:
- 《论语》孔子弟子及再传弟子:记录了孔子及其弟子的言行,是儒家思想的经典著作。
- 《老子》老子:道家思想的代表作,阐述了“道”的概念和无为而治的思想。
- 《庄子》庄子:充满哲学思辨和想象力,表达了道家的逍遥自在的思想。
- 《孟子》孟子:儒家经典之一,强调了人性本善和仁政的思想。
- 《荀子》荀子:主张性恶论,强调通过教育和后天的努力来改变人性。
- 《西方哲学史》罗素:系统地介绍了西方哲学的发展历程,是了解西方哲学的重要读物。
- 《理想国》柏拉图:描绘了一个理想的国家制度,探讨了正义、美德等哲学问题。
- 《沉思录》马可·奥勒留:古罗马皇帝的哲学思考,对人生、道德等问题有深刻的见解。
- 《存在与时间》马丁·海德格尔:对存在主义哲学的重要贡献,探讨了存在的本质和人类的存在方式。
- 《纯粹理性批判》伊曼努尔·康德:对人类理性的批判和反思,是哲学史上的经典之作。
- 《查拉图斯特拉如是说》弗里德里希·尼采:表达了尼采的超人哲学和对传统道德的批判。
3. 历史传记类:
- 中国历史:
- 《史记》司马迁:中国第一部纪传体通史,具有极高的史学价值和文学价值。
- 《资治通鉴》司马光:编年体通史巨著,为后人提供了丰富的历史经验和教训。
- 《三国志》陈寿:记录了三国时期的历史,是了解三国历史的重要文献。
- 《汉书》班固:中国第一部纪传体断代史,对西汉历史的研究具有重要意义。
- 《后汉书》范晔:记载了东汉历史的纪传体史书。
- 《明朝那些事儿》当年明月:以通俗易懂的方式讲述了明朝的历史,深受读者喜爱。
- 《万历十五年》黄仁宇:从独特的视角分析了明朝万历年间的历史事件和社会现象。
- 《曾国藩传》萧一山:全面地介绍了曾国藩的一生,对其政治、军事、文化等方面的成就进行了评价。
- 《苏东坡传》林语堂:生动地描绘了苏轼的人生经历和文学成就。
- 《武则天正传》林语堂:对武则天的一生进行了详细的叙述和评价。
- 世界历史:
- 《全球通史》L.S.斯塔夫里阿诺斯:从全球的角度讲述了人类历史的发展,具有广阔的视野。
- 《人类简史》尤瓦尔·赫拉利:融合多学科知识,探讨了人类的演化和发展。
- 《罗马帝国衰亡史》爱德华·吉本:对罗马帝国的兴衰进行了深入的研究和分析。
- 《法国大革命史》托马斯·卡莱尔:详细地记录了法国大革命的过程和影响。
- 《第三帝国的兴亡》威廉·夏伊勒:对纳粹德国的崛起和灭亡进行了全面的描述。
- 《拿破仑传》埃米尔·路德维希:生动地刻画了拿破仑的一生,展现了他的军事才能和政治抱负。
- 《富兰克林自传》本杰明·富兰克林:美国开国元勋的自传,记录了他的成长经历和思想观念。
- 《甘地自传》莫罕达斯·卡拉姆昌德·甘地:讲述了甘地的非暴力抵抗运动和他的人生哲学。
- 《乔布斯传》沃尔特·艾萨克森:记录了苹果公司创始人乔布斯的传奇人生。
- 《爱因斯坦传》沃尔特·艾萨克森:介绍了爱因斯坦的科学成就和人生经历。
4. 科学技术类:
- 《时间简史》斯蒂芬·霍金:介绍了宇宙的起源、黑洞、时间旅行等宇宙学前沿知识。
- 《万物简史》比尔·布莱森:以通俗易懂的方式讲述了科学的发展历程和科学知识。
- 《物种起源》查尔斯·达尔文:提出了生物进化论,对生物学的发展产生了深远的影响。
- 《梦的解析》西格蒙德·弗洛伊德:对人类的梦境进行了深入的分析,是精神分析学的经典著作。
- 《几何原本》欧几里得:古希腊数学的经典著作,对几何学的发展具有重要意义。
- 《自然哲学的数学原理》艾萨克·牛顿:阐述了牛顿力学的基本原理,是物理学的经典著作。
- 《相对论》阿尔伯特·爱因斯坦:包括狭义相对论和广义相对论,改变了人们对时空的认识。
- 《电磁通论》詹姆斯·克拉克·麦克斯韦:系统地阐述了电磁理论,是电磁学的重要著作。
- 《控制论》诺伯特·维纳:对控制论的基本概念和方法进行了阐述,对现代科学技术的发展产生了重要影响。
- 《从一到无穷大》乔治·伽莫夫:介绍了数学、物理学、生物学等领域的知识,具有启发性。
- 《寂静的春天》蕾切尔·卡森:引发了人们对环境保护的关注,是环保运动的经典之作。
5. 社会科学类:
- 《资本论》卡尔·马克思:分析了资本主义的经济制度,揭示了资本主义的本质和发展规律。
- 《国富论》亚当·斯密:奠定了现代经济学的基础,提出了自由市场经济的理论。
- 《社会契约论》让-雅克·卢梭:探讨了国家的起源、政治制度等问题,对现代政治思想产生了重要影响。
- 《乌合之众:大众心理研究》古斯塔夫·勒庞:分析了群体的心理和行为,对社会心理学的发展具有重要意义。
- 《自卑与超越》阿尔弗雷德·阿德勒:探讨了自卑心理的形成和克服方法,以及个体与社会的关系。
- 《枪炮、病菌与钢铁》贾雷德·戴蒙德:从地理环境的角度分析了人类社会的发展差异。
- 《人类行为的经济学分析》加里·贝克尔:将经济学的分析方法应用于人类行为的研究。
- 《新教伦理与资本主义精神》马克斯·韦伯:探讨了宗教信仰与资本主义发展的关系。
- 《疯癫与文明》米歇尔·福柯:对疯癫的历史和文化进行了研究,揭示了权力与知识的关系。
- 《第二性》西蒙娜·德·波伏娃:探讨了女性的地位和性别角色,是女性主义的经典著作。
6. 艺术文学类:
- 《艺术的故事》贡布里希:系统地介绍了艺术的发展历程,是艺术史的经典著作。
- 《美学散步》宗白华:对中国美学的理论和实践进行了深入的探讨。
- 《西方美学史》朱光潜:系统地介绍了西方美学的发展历程。
- 《中国书法史》刘涛:全面地介绍了中国书法的发展历程和不同时期的书法风格。
- 《人间词话》王国维:对中国古代诗词的审美和批评进行了深入的探讨。
- 《文心雕龙》刘勰:中国古代文学理论的经典著作,对文学创作和批评具有重要的指导意义。
- 《莎士比亚全集》威廉·莎士比亚:包括戏剧、诗歌等作品,是英国文学的瑰宝。
- 《托尔斯泰小说全集》列夫·托尔斯泰:收录了托尔斯泰的所有小说作品,展现了他的文学成就。
- 《巴尔扎克小说全集》巴尔扎克:法国现实主义文学的代表作品,反映了社会的种种问题。
- 《鲁迅杂文全集》鲁迅:鲁迅的杂文具有深刻的思想内涵和强烈的批判精神。
7. 励志成长类:
- 《少有人走的路》M·斯科特·派克:帮助人们理解人生的苦难和成长的意义。
- 《了不起的盖茨比》弗朗西斯·斯科特·菲茨杰拉德:通过主人公的经历,鼓励人们追求梦想。
- 《你当像鸟飞往你的山》塔拉·韦斯特弗:讲述了作者通过学习和自我觉醒,摆脱原生家庭束缚的故事。
- 《刻意练习:如何从新手到大师》安德斯·埃里克森、罗伯特·普尔:介绍了刻意练习的方法,帮助人们提高技能。
- 《终身成长》卡罗尔·德韦克:探讨了固定型思维和成长型思维的区别,鼓励人们培养成长型思维。
- 《逆商:我们该如何应对坏事件》保罗·史托兹:介绍了逆商的概念和提高逆商的方法,帮助人们应对挫折。
- 《坚毅:释放激情与坚持的力量》安杰拉·达克沃思:探讨了坚毅的品质对成功的重要性。
- 《自卑与超越》阿尔弗雷德·阿德勒:帮助人们认识自卑心理,通过努力实现自我超越。
- 《影响力》罗伯特·西奥迪尼:介绍了影响他人的方法和技巧,对人际交往和商业活动具有指导意义。
- 《原则》瑞·达利欧:分享了作者的生活和工作原则,对人们的决策和行为具有启发意义。
8. 儿童文学类:
- 《安徒生童话》安徒生:经典的童话作品,充满了幻想和人性的美好。
- 《格林童话》格林兄弟:收录了众多经典的童话故事,如《白雪公主》《灰姑娘》等。
- 《小王子》安托万·德·圣-埃克苏佩里:不仅适合儿童阅读,也深受成年人的喜爱,传达了关于爱和人生的真谛。
- 《夏洛的网》E.B.怀特:讲述了小猪威尔伯和蜘蛛夏洛之间的友谊,充满了温情。
- 《彼得·潘》詹姆斯·马修·巴利:描绘了永远不会长大的彼得·潘和他在永无岛的冒险故事。
- 《绿野仙踪》莱曼·弗兰克·鲍姆:讲述了小女孩多萝西在奥兹国的冒险经历,鼓励人们勇敢面对困难。
- 《爱的教育》亚米契斯:以日记的形式讲述了小学生安利柯的成长故事,充满了爱和教育的意义。
- 《柳林风声》肯尼斯·格雷厄姆:以动物为主角,描绘了英国乡村的生活和自然风光。
- 《秘密花园》弗朗西丝·霍奇森·伯内特:讲述了三个孩子在秘密花园中的成长故事,充满了对生命的热爱和对自然的赞美。
- 《小王子绘本》:以绘本的形式呈现《小王子》的故事,适合儿童阅读。