作为一个合格的程序员,应该抱着在哪里都要加班的理想。
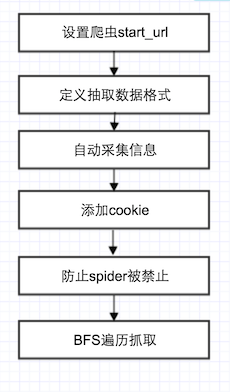
为了在家调试方便,老高使用frp将自己放在公司的开发机器的ssh端口开放出来了,但是配置frp客户端的过程中总是出现下面的一句话:
2019/08/30 23:42:47 [W] [service.go:82] login to server failed: EOF
EOF
开始怀疑是frp的版本问题,于是客户端和服务端都换上了最新的版本,结果还是无法解决问题,继续尝试更换端口,问题依旧。
网上搜索一圈,发现遇到login to server failed: EOF问题的人还真不少,下面看看老高是如何解决的吧!
本地抓包
开启Wireshark,选择网卡,输入过滤规则:
tcp and ip.addr==xxx.xxx.220.109

后面的那三个RST包很可疑,其中还有三个IRC协议的包,打开看一下,发现原来是认证数据。
{"version":"0.28.2","hostname":"","os":"darwin","arch":"amd64","user":"","privilege_key":"144fa23b09635f403ccd18","timestamp":1567119104,"run_id":"","pool_count":1}服务端抓包
打开终端,输入命令
# xxxx 为frp监听端口tcpdump -i eth0 port xxxx -n
23:57:54.041136 IP 180.167.229.162.64674 > xx.xx.xx.xx.PPPP: Flags [S], seq 2454088299, win 65535, options [mss 1460,nop,wscale 6,nop,nop,TS val 1598952560 ecr 0,sackOK,eol], length 0
23:57:54.041203 IP xx.xx.xx.xx.PPPP > 180.167.229.162.64674: Flags [S.], seq 2502814427, ack 2454088300, win 65160, options [mss 1460,sackOK,TS val 3508779989 ecr 1598952560,nop,wscale 6], length 0
23:57:54.171283 IP 180.167.229.162.64674 > xx.xx.xx.xx.PPPP: Flags [.], ack 1, win 2058, options [nop,nop,TS val 1598952691 ecr 3508779989], length 0
23:57:54.171670 IP 180.167.229.162.64674 > xx.xx.xx.xx.PPPP: Flags [P.], seq 1:13, ack 1, win 2058, options [nop,nop,TS val 1598952692 ecr 3508779989], length 12
23:57:54.171694 IP xx.xx.xx.xx.PPPP > 180.167.229.162.64674: Flags [.], ack 13, win 1018, options [nop,nop,TS val 3508780120 ecr 1598952692], length 0
23:57:54.171896 IP xx.xx.xx.xx.PPPP > 180.167.229.162.64674: Flags [P.], seq 1:13, ack 13, win 1018, options [nop,nop,TS val 3508780120 ecr 1598952692], length 12
23:57:54.172366 IP 180.167.229.162.64674 > xx.xx.xx.xx.PPPP: Flags [P.], seq 13:25, ack 1, win 2058, options [nop,nop,TS val 1598952692 ecr 3508779989], length 12
23:57:54.172391 IP 180.167.229.162.64674 > xx.xx.xx.xx.PPPP: Flags [R.], seq 25, ack 1, win 8224, length 0
23:57:54.301735 IP 180.167.229.162.64674 > xx.xx.xx.xx.PPPP: Flags [R.], seq 13, ack 1, win 8224, length 0
23:57:54.302089 IP 180.167.229.162.64674 > xx.xx.xx.xx.PPPP: Flags [R.], seq 13, ack 13, win 8224, length 0
好嘛,注意最后三个包,也是RST,而且方向刚好和我在本地抓包相反,很明显,这是受到了替身攻击!