OpenStack Nova 的高性能虚拟机支撑
CPU 计算平台体系架构
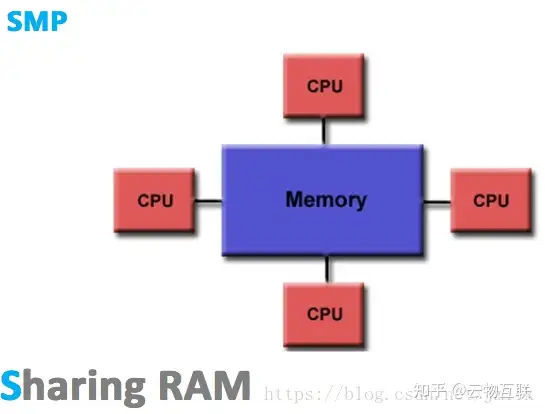
SMP 架构
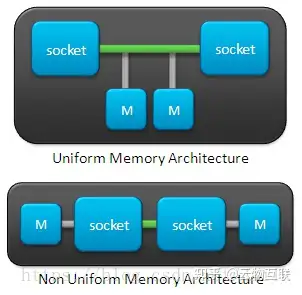
SMP(Sysmmetric Multi-Processor System,对称多处理器系统),顾名思义,SMP 架构由多个具有对称关系的处理器组成。所谓对称,即处理器之间是水平的镜像关系,无有主从之分。SMP 架构使得一台计算机不再由单个 CPU 组成;
SMP 的结构特征就是「多处理器共享一个集中式存储器」,每个处理器访问存储器的时间片一致,使工作负载能够均匀的分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。
这里写图片描述
虽然系统具有多个处理器,但由于共享一个集中式存储器,所以只会运行一个操作系统和数据库的副本(实例),能够保持单机特性。同时也要求系统需要保证共享存储器的数据一致性。如果多个处理器同时请求访问这些共享资源,就会引发资源竞态,需要软硬件实现加锁机制来解决这个问题。所以,SMP 又称为 UMA(Uniform Memory Access,一致性存储器访问),所谓一致性指的就是在任意时刻,多个处理器只能为内存的每个数据保存或共享一个唯一的数值。
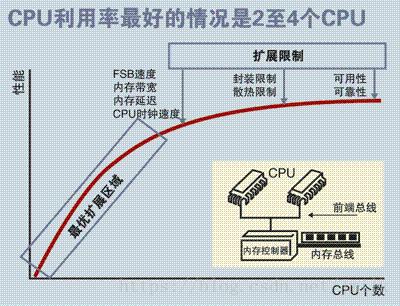
很显然,这样的架构设计注定没法拥有良好的处理器数量扩展性,因为共享内存的资源竞态总是存在的,处理器利用率最好的情况只能停留在 2 到 4 颗。
这里写图片描述
综合来说,SMP 架构广泛的适用于 PC 和移动设备领域,能显著提升并行计算性能。但 SMP 却不适合超大规模的服务器端场景,例如:云计算。
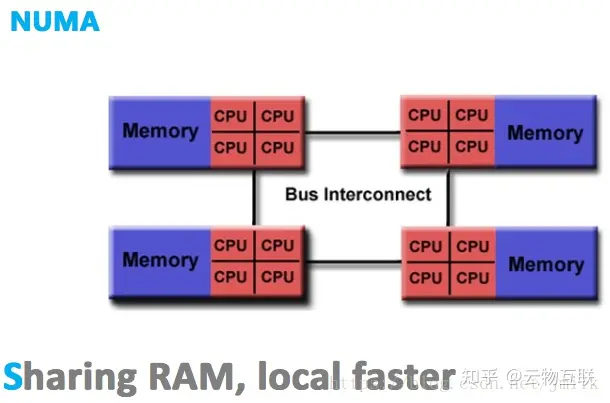
NUMA 结构
现代的计算机系统中,处理器的处理速度要远快于主存的速度,所以限制计算机计算性能的瓶颈在存储器带宽上。SMP 架构因为限制了处理器访问存储器的频次,所以处理器可能会时刻对数据访问感到饥饿。
NUMA(Non-Uniform Memory Access,非一致性存储器访问)架构优化了 SMP 架构扩展性差以及存储器带宽窄的问题。
实际上 NUMA 和 SMP 架构是类似的,同样只会保存一份操作系统和数据库的副本,表示 NUMA 架构中的处理器依旧能够访问到整个存储器。两种主要的区别在于 NUMA 架构采用了分布式存储器,将处理器和存储器划分为不同的节点(NUMA Node),每个节点都包含了若干的处理器与内存资源。
这里写图片描述
NUMA 的结构特征就是「多节点」,每个节点都可以拥有多个处理器和内存资源,多节点的设计有效提高了存储器的带宽和处理器的扩展性。假设系统含有 4 个 NUMA 节点,那么在理想情况下系统的存储器带宽将会是 SMP 架构的 4 倍。而且在内存资源充裕的情况下,再多扩展几个节点当然也只是水到渠成的事情。
但就如上文所提到,NUMA 节点内的处理器实际上会可以访问整体存储器的。按照节点内外,内存被分为节点内部的本地内存以及节点外部的远程内存。当处理器访问本地内存时,走的是内部总线,当处理器访问远程内存时,走的是主板上的 QPI 互联模块。显然,访问前者的速度要远快于后者,NUMA(非一致性存储器访问)因此而得名。
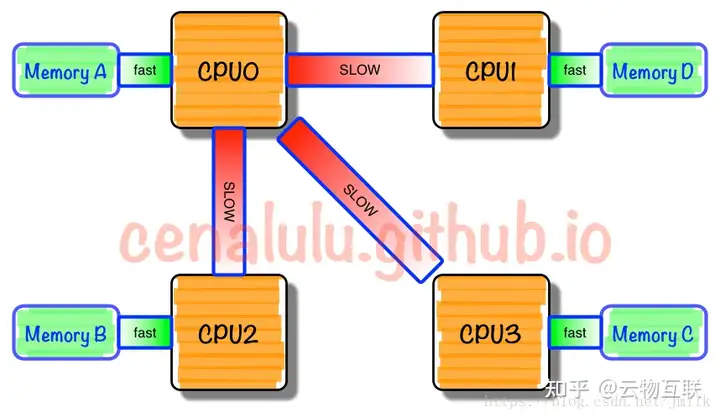
这里写图片描述
**由于这个特性,基于 NUMA 架构开发的应用程序应该尽可能避免跨节点的远程内存访问。**因为,跨节点内存访问不仅仅是通信速度慢,还需要处理不同节点间内存、缓存的数据一致性。可见,线程在不同的节点间切换,是需要花费大成本的。
NUMA 和 UMA(SMP) 的异同:
NUMA 与 SMP 中的处理器都可以访问整个系统的物理存储器
NUMA 采用了分布式存储器,提供了分离的存储器给各个节点,避免了 SMP 中多个处理器无法同时访问单一存储器的问题
NUMA 节点的处理器访问内部存储器所需要的时间,比访问其他节点的远程存储器要快得多
NUMA 既保持了 SMP 单一操作系统副本、简便应用程序编程以及易于管理的特点,又继承了大规模并行处理 MPP 的可扩展性,是一个折中的方案
这里写图片描述
虽然 NUMA 的多节点设计具有较好的处理器数量扩展性,最多可以支持几百个 CPU。但因为 NUMA 没有实现彻底的主存隔离,所以 NUMA 依旧没有实现处理器数量的无限扩展,这是为了追求更高的并发性能所作出的妥协(一个节点也未必就能完全满足多线程并发,还是会存在多节点间线程切换的问题)。
NUMA 结构的基本概念:
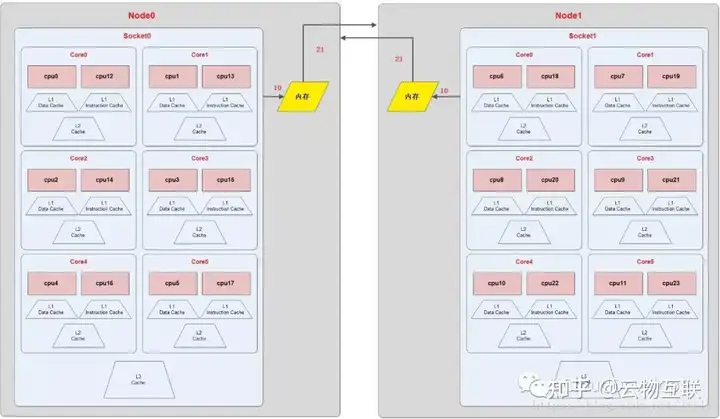
Node:包含有若干个物理 CPU 的组.
Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽。
Core:物理 CPU 封装内的物理 Core。
Thread:使用超线程技术虚拟出来的逻辑 Core(一般的,物理 Core 和逻辑 Core 的比例是 1:2),需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread。
NOTE:一个 NUMA Node 包含若干个 Socket(Socket 是一颗物理 CPU 的封装),一个 Socket 包含有若干个 Core(物理/虚拟)。
这里写图片描述
上图的 NUMA Topology 表示:
两个 Node
一个 Node 具有一个 Socket,即一个 pCPU
一个 pCPU 具有 6 个 Core
一个 Core 具有 2 个 Processor
所以总共的逻辑 CPUs Processor = 2*1*6*2 = 24
MMP 结构
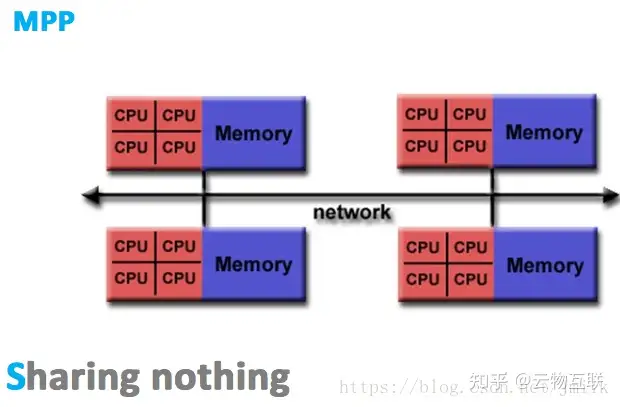
MPP(Massive Parallel Processing,大规模并行处理)架构,既然 NUMA 扩展性的限制是没有完全实现资源的独立性,那么 MPP 的解决思路就是为处理器提供彻底的独立资源。MPP 拥有多个独立的 SMP 单元,每个 SMP 单元独占并只会访问自己本地的内存、I/O 等资源,SMP 单元间通过节点互联网络进行连接(Data Redistribution,数据重分配),是一个完全无共享(Share Nothing)的 CPU 计算平台结构。
这里写图片描述
MPP 结构的特征就是「多 SMP 单元组成,单元之间完全无共享」。除此之外,MPP 结构还具有以下特征:
每个 SMP 单元内都可以包含一个操作系统副本,所以每个 SMP 单元都可以运行自己的操作系统
MPP 需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程,目前一些基于 MPP 技术的服务器往往通过系统级软件(e.g. 数据库)来屏蔽这种复杂性
MPP 架构的局部区域内存的访存延迟低于远地内存访存延迟,因此 Linux 会自定采用局部节点分配策略,当一个任务请求分配内存时,首先在处理器自身节点内寻找空闲页,如果没有则到相邻的节点寻找空闲页,如果还没有再到远地节点中寻找空闲页,在操作系统层面就实现了访存性能优化
因为完全的资源隔离特性,所以 MPP 的扩展性是最好的,理论上其扩展无限制,目前的技术可实现 512 个节点互联,数千个 CPU 。
Nova 的高性能虚拟机
在 Icehouse 版本之前,Nova 定义的 libvirt.xml,不会考虑 Host NUMA 的情况。导致 Libvirt 在默认情况下,有可能发生跨 NUMA node 获取 CPU/Memory 资源的情况,导致 Guest 性能下降。Openstack 在 Juno 版本中新增 NUMA 特性,用户可以通过将 Guest 的 vCPU/Memory 绑定到 Host NUMA Node上,以此来提升 Guest 的性能。

这里写图片描述
PS:Guest 是 ComputeNode 上的一个 Linux 进程,vCPU 是 Guest 进程内的一个特殊的线程,被 Host OS 调度。
Nova 虚拟机 CPU/RAM 设计的背景
基础概念:
vCPU:虚拟 CPU,分配给虚拟机的逻辑 CPU。根据虚拟机拓扑的不同,一个虚拟机 CPU 可以是一个 CPU 封装元件(socket)、一个 CPU 核(core)、或者一个 CPU 线程(thread)。
pCPU:物理 CPU, 虚拟机主机所展示的逻辑 CPU,根据主机拓扑的不同,一个物理可以是一个 CPU 封装元件(socket)、一个 CPU 核(core)、或者一个 CPU 线程(thread)。
NUMA:非一致内存访问架构,内存访问时间取决于内存页面和处理器核心之间的位置。
Node:一个包含 CPU 或者内存(或二者兼具)的 NUMA 系统单元
Cell:Node 的通名词,供 Libvirt API 使用
Socket:包含在 NUMA 系统单元内的单个独立 CPU 封装元件
Core:一个 CPU 封装元件中的一个处理单元
Thread:超线程,一个 CPU 核中的一个超流水线
KSM:Linux 内核内存共享技术(Kernel Shared Memory)
THP:透明巨型页,为进程提前分配巨型页的一种 Linux 技术
pCPU:物理 CPU ,主机插槽上的 CPU,可以通过 /proc/cpuinfo 中的不同的 physical id 个数来统计 pCPU 的个数。 physical id 对应 socket_id Socket:表示一颗物理 CPU 的封装,对应主板上的一个 CPU 插槽 pCPU Cores:一块物理 CPU 上所具有的芯片组(CPU 寄存器+中断逻辑 etc.)数量,一个芯片组就是一个 CPU 的 Core,现在我们普遍认为一个物理 CPU 具有多个 Cores。 Hyper-Threading:超线程,可以将一个物理 CPU 的 Core,虚拟成若干个(通常为 2 个)伪 Core,达到一个物理 Core 可以处理多个线程的效果。 Logical Processor,简称 Processor:逻辑 CPU,可以通过 /proc/cpuingo 中的 processor 字段来统计 Processor 的个数,也可以使用下述公式计算:
逻辑 CPU 数量 = 物理 CPU 数量 x 物理 CPU Cores(一个物理 CPU 具有若干个 Core)[x 2(如果开启了超线程,这个值通常为 2)]
e.g.
酷睿 i5 760:原生四核心四线程处理器,没有采用超线程技术。一个物理 CPU,具有 4 个 Core,没有超线程,所以逻辑 CPU Processor = 1*4
NOTE:一般来说,物理 CPU 个数 × 每颗核数就应该等于逻辑 CPU 的个数,如果不相等的话,则表示服务器的 CPU 支持超线程技术 NOTE:同一个 Socket 中,具有相同 Core ID 的 Processor 是同一个物理 CPU Core 的超线程 NOTE:具有相同 Physical ID 的 Processor 是同一个物理 CPU 封装的 Thread(伪 Core)或 Core
操作系统许可(Licensing)
操作系统供应商许可规则,可能会严格约束操作系统所支持的 CPU 封装元件(sockets) 的数目。此时,为虚拟机分配的虚拟 CPU,应该偏向处理单元(core),而不是封装单元(socket)。
操作系统许可的影响,意味着用户在上传镜像到 glance 时,需要指明一个运行镜像的最佳的 CPU 拓扑,包含处理单元(core)与封装元件(socket)的分配。云平台管理员也可以修改程序的默认值,以避免用户超出常见的许可限制。也就是说,对于一个 4 虚拟 CPU 核的虚拟机,如果使用默认值限制最大的封装元件(socket)数目为 2,则可以设置其处理单元为 2(在 Socket 数量没有超出限制的前提下,虚拟机也能达到具有 4 Core 的效果),此时 windows 镜像也能够正常处理。
NOTE:OpenStack 管理员应该遵从操作系统许可需求,限制虚拟机使用的拓扑(例如:max_sockets==2)。设置默认的拓扑参数,以保证虚拟机操作系统镜像能够满足常规操作系统许可,而不必每一个用户都去设置镜像属性。
性能(Performance)
各种 CPU 拓扑的性能并不一致。例如,两个主机线程运行在同一个处理单元(core)上时,其性能就会低于运行在不同的处理单元(core)上。而当一个处理单元(core)有多个超线程(thread)时,操作系统调度器将决定线程的具体运行位置。超线程性能的影响,意味着除非指定将虚拟机超线程与主机的超线程一一绑定,否则无法为虚拟机指定超线程。如果不绑定虚拟机 CPU(vCPU) 与物理 CPU(pCPU) 的关系,则虚拟机应当始终不使用超线程(threads==1),而只是用 CPU 封装元件(sockets)与 CPU 处理单元(core),而没有必要向用户暴露超线程的配置能力。如果用户的虚拟机对负载比较敏感,那么用户最多会希望他们的镜像不运行在兄弟超线程(同一个处理单元上的超线程)上。
NOTE:如果不绑定 vCPU 和 pCPU,那么虚拟机不应该使用超线程(vCPU 会在不同 Core 的 thread 上浮动),而是虚拟机应该使用 Socket/Core。如果用户对虚拟机的性能要求比较高,那么不应该让虚拟机的 vCPU 运行在 Thread 上,而应该将 vCPU 运行在 Socket/Core 上。所以应该将 siblings Thread 过滤掉。
从 Intel 和 VMware 对外宣称的资料看,开启超线程后,物理核总计算能力是否提升以及提升的幅度和业务模型相关,平均提升在 20%-30% 左右。超线程对物理核执行资源的争抢,业务的执行时延会相应增加。当超线程相互竞争时,超线程的计算能力相比不开超线程时的物理核会下降30%左右。所以,超线程应该关闭还是开启,主要还是取决于应用模型:
对于时延敏感性任务,比如用户需要及时等待任务运行结果的,在节点负载过高,引发超线程竞争时,任务的执行时长会显著增加,影响用户体验。
对于后台计算型任务,比如超算中心上运行的后台计算型任务(一般要运行数小时或数天),建议开启超线程提高整个节点的吞吐量。
NUMA Topology
现在虚拟化主机都支持 NUMA 拓扑,会将内存与物理 CPU 分布在 2 个或者更多的 NUMA 节点上。
主要驱动 NUMA 应用的因素是高存储带宽,有效的缓存效率以及灵活 PCIe I/O 设备的布局。也就是说,每一个 NUMA 单元内部都由自己专有的内存总线,用于访问专用内存,而所有 NUMA 单元使用共享总线访问远端的内存。假如有一个具有 4 个 NUMA 单元的系统,每一个单元内部有 1GB/s 的存储带宽,同时共享总线也具有 1GB/s 的带宽。如果所有的处理器总是使用 NUMA 单元内部内存,那么系统就拥有了 4GB/s 的存储带宽潜力。如果所有处理器都是用远端存储,那么系统就只有了 1GB/s 的存储带宽潜力。使用共享的总线可能触发 NUMA 单元之间的缓存异常同步,对于内存密集型工作负载的性能会产生显著影响。当 I/O 性能至关重要时,加上共享总线上的无效 Cache 资源浪费,连接到远程 PCIe 总线上的设备(也就是说连接不同NUMA单元)作业性能将会急剧下降。
因此,虚拟机在 NUMA 单元上的错误布局,或者不正确的 PCI 设备分配选择,将会导虚拟化主机资源的严重浪费。这点影响将会抹掉任何内存与 CPU 决策所带来的好处,包括 guest CPU topology,vCPU 与 pCPU 绑定,以及使用大页内存。因此标准的策略将是一个虚拟机完全局限在单个 NUMA 节点。
NOTE:NUMA topology 具有高存储带宽,高缓存效率,高扩展性以及 PCIe I/O 设备布局灵活性好的优点。 NOTE:跨 NUMA node 具有 node 间缓存异常同步,总线延时高,存储带宽低,浪费缓存资源等导致性能急剧下降的缺点,尤其在内存密集型工作负载场景中。 NOTE:标准的 NUMA topology 策略是将一个虚拟机完全局限在单个 NUMA 节点中。
Guest NUMA Topology
如果虚拟机的虚拟 CPU 或者内存分配大过了 NUMA 节点,或者 NUMA 节点可用的 PCIe 设备不足时,必须针对虚拟机做出合适的策略,或者禁止创建过大 NUMA 节点的虚拟机,或者允许虚拟机跨越多 NUMA 运行。在虚拟机迁移时,可以更改这些策略,也就是说,在对主机进行维护而疏散主机时,会选择接受临时降低性能而选择次优的 NUMA 布局。布局的问题还要考虑到虚拟机的具体使用场景,例如,NFV 的部署就要求严格的 NUMA 布局。
如果一个虚拟机具有多个 guest NUMA 节点,为了操作系统能够最大化利用其分配到的资源,主机的 NUMA 拓扑必须暴露给虚拟机。虚拟机的 guest NUMA单元应该与虚拟化主机的 host NUMA单元进行映射。这样可以映射大块的虚拟机内存到虚拟化主机内存节点,设置虚拟 CPU 与物理 CPU 的映射。
也就是说,如果虚拟机有 4 个虚拟 CPU 需要跨越两个虚拟化主机 NUMA 单元,虚拟 CPU 0/1 绑定到第一个主机 NUMA 节点,而虚拟 CPU 2/3 将会绑定到第二个主机 NUMA 节点上,但是并不强制绑定每一个 vCPU 与 host NUMA 单元内特定 pCPU 的关系,这将由操作系统调度器指定。此时,如果虚拟主机具有超线程特性,则暴露超线程特性给虚拟机,同时在 NUMA 单元内绑定 vCPU 与 pCPU 的关系。
NOTE:如果 guest 的 vCPU/RAM 分配大于单个 host NUAM node,那么应该划分为多个 guest NUMA topology,并分别映射到不同的 host NUMA node 上。 NOTE:如果 host 开启了超线程,那么应该在单个 host NUMA node 上进行 vCPU 和 pCPU 的绑定,否则 vCPU 会被分配给 siblings thread,性能不如物理 Core 好。
大页内存
绝大多数现代 CPU 支持多种内存页尺寸,从 4KB 到 2M/4M,最大可以达到 1GB;所有处理器都默认使用最小的 4KB 页。如果大量的内存可以使用大页进行分配,将会明显减少 CPU 页表项,因此会增加页表缓存的命中率,降低内存访问延迟。
如果操作系统使用默认的小页内存,随着运行时间,系统会出现越来越多的碎片,以至于很难申请到大页的内存。在大页内存大小越大时,该问题越严重。因此,如果有使用大页内存的需求,最好的办法是在系统启动时就预留好内存空间。
当前的 Linux 内核不允许针对特定的 NUMA 节点进行这样的设定,不过,在不久的将来这个限制将被取消。更进一步的限制是,由于 MMIO 空洞的存在,内存开始的 1GB 不能使用 1GB 的大页。**Linux 内核已经支持透明巨型页(THP,transparent huge pages)特性。该特性会尝试为应用程序预分配大页内存。**依赖该特性的一个问题是,虚拟机的拥有者,并不能保证给虚拟机使用的是大页内存还是小页内存。
内存块是直接指定给特定的 NUMA 节点的,这就意味着大页内存也是直接存在于 NUMA 节点上的。**因此在 NUMA 节点上分配虚拟机时,计算服务需要考虑在 NUMA 节点或者主机上可能会用到的大页内存(NUMA node 或 host 存在哪一些大页内存类型和数量状况)。**为虚拟机内存启用大页内存时,可以不用考虑虚拟机操作系统是否会使用。
NOTE:有使用大页内存的需求,需要在系统启动时就预留好内存空间,Linux 内核使用 THP 来实现,但也存在着问题。 NOTE:如果希望让虚拟机使用大页内存,那么应该收集 NUMA 节点所拥有的内存页类型和数量信息。
专用资源绑定
计算节点可以配置 CPU 与内存的超配比例,例如,16 个物理 CPU 可以执行 256 个虚拟 CPU,16GB 内存可以允许使用 24GB 虚拟机内存。
超配的概念可以扩展到基本的 NUMA 布局,但是一旦提到大页内存,内存便不能再进行超配。当使用大页内存时,虚拟机内存页必须与主机内存页一一映射,并且主机操作系统能通过交换分区分配大页内存,这也排除了内存超配的可能。但是大页内存的使用,意味着需要支持内存作为专用资源的虚拟机类型。尽管设置专用资源时,不会超配内存与 CPU,但是 CPU 与内存的资源仍然需要主机操作系统提前预留。如果使用大页内存。必须在主机操作系统中明确预留。
对于 CPU 则有一些灵活性。因为尽管使用专用资源绑定 CPU,主机操作系统依然会使用这些 CPU 的一些时间。不管怎么样,需要预留一定的物理 CPU 专门为主机操作系统服务,以避免操作系统过多占用虚拟机 CPU,而造成对虚拟机性能的影响。Nova 可以保留一部分 CPU 专门为操作系统服务,这部分功能将会在后续的设计中加强。
允许内存超配时,超出主机内存的部分将会使用到 Swap。Swap 将会影响主机整体 I/O 性能,所以尽量不要把需要专用内存的虚拟机与允许内存超配的虚拟机放在同一台物理主机上。
如果专用 CPU 的虚拟机与允许超配的虚拟机竞争 CPU,由于 Cache 的影响,将会严重影响专用 CPU 的虚拟机的性能,特别在同一个 NUMA 单元上时。因此,最好将使用专用 CPU 的虚拟机与允许超配的虚拟机放在不同的主机上,其次是不同的 NUMA 单元上。
NOTE:确定 VMware 虚拟机支不支持使用大页内存 NOTE:大页内存需要明确的在物理主机中预留 NOTE:为了虚拟机能够更加好的“独占”物理 CPU,一般的,也会预留一些物理 CPU 资源给物理主机使用 NOTE:尽量不要将占用专用内存的虚拟机与使用内存超配的虚拟机放到同一个物理主机中运行 NOTE:尽量不要将占用专用 CPU 的虚拟机与使用 CPU 超配的虚拟机放到同一个物理主机中运行,其次是不要放到同一个 NUMA node 中运行
内存共享
Linux 内核有一项特性,叫做内核共享存储(KSM),该特性可以使得不同的处理器共享相同内容的内存页。内核会主动扫描内存,合并内容相同的内存页。如果有处理器改变这个共享的内存页时,会采用 CoW 的方式写入新的内存页。
当一台主机上的多台虚拟机使用相同操作系统或者虚拟机使用很多相同内容内存页时,KSM 可以显著提高内存的利用率。因为内存扫描的消耗,使用 KSM 的代价是增加了 CPU 的负载,并且如果虚拟机突然做写操作时,会引发大量共享的页面,此时会存在潜在的内存压力峰值。虚拟化管理层必须因此积极地监控内存压力情况并做好现有虚拟机迁移到其他主机的准备,如果内存压力超过一定的水平限制,将会引发大量不可预知的 Swap 操作,甚至引发 OOM。ZSwap 特性允许压缩内存页被写入 Swap 设备,这样可以大量减少 Swap 设备的 I/O 执行,减少了交换主机内存页面中固有的性能下降。
NOTE:虚拟化管理层应该积极的监控内存压力,适时的将虚拟机迁移到其他物理主机。
PCI 设备
PCI 设备与 NUMA 单元关系密切,PCI 设备的 DMA 操作使用的内存最好在本地 NUMA 节点上。因此,在哪个 NUMA 单元上分配虚拟机,将会影响到 PCI 设备的分配。
NOTE:将 PCI 设备和虚拟机分配到同一个 NUMA node 上。
从上述背景知识我们能够清晰的认识到,为了最大化利用主机资源,好好利用 NUMA 与大页内存等工具显得尤为重要。即使使用默认配置,Nova 也能够做到 NUMA 布局的优化以及考虑到大页内存的使用。显式的配置(通过配置虚拟机套餐类型 Flavor)只是为了满足性能优化或者虚拟机个性化需求,亦或者云平台提供商希望为不同的价格方案设置认为的设置。显示配置还能够限制用户可使用的拓扑,以防止用户使用非最优 NUMA 拓扑方案。
NOTE:只有当虚拟机的虚拟 CPU 与主机的物理 CPU 一一绑定时,配置超线程参数(threads != 1)才有意义。这不是一个最终用户需要考虑的东西,但是云平台管理员希望能够通过设置虚拟机类型明确避免使用主机超线程(如果 vCPU 和 pCPU 没有绑定,那么应该过滤物理主机的超线程 ID)。这可以通过使用主机聚合调度的方式实现。
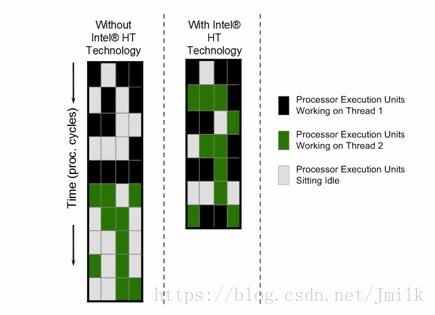
超线程对性能的影响
超线程技术仅仅是在一个物理核心上使用了两个物理任务描述符,物理计算能力并没有增加。现在很多程序如 WEB Application,都采用多 Worker 设计,在超线程的帮助下,两个被调度到同一核心不同超线程的 Worker,通过共享 Cache,TLB,大幅降低了任务切换的开销。另外,在某个 Worker 不忙的时候,超线程允许其它的 Worker 也能使用物理计算资源,有助于提升物理核整体的吞吐量。但由于超线程对物理核执行资源的争抢,业务的执行时延也会相应增加。
这里写图片描述
对于 CPU 密集型任务的测试:仅运行一个负载和同时在一个核的两个超线程上运行负载的时间对比,可以看出在存在超线程竞争时,超线程计算能力大概是物理核的 60% 左右。
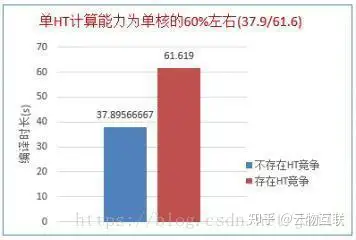
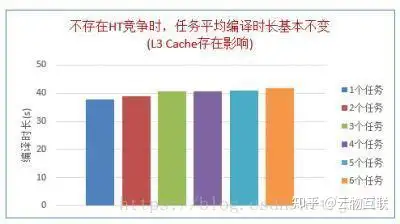
不同数量负载同时运行时的平均编译时间,此时没有两个负载运行在同一个核的两个超线程上。可以看出,不存在超线程竞争时,负载平均运行时间基本不变。
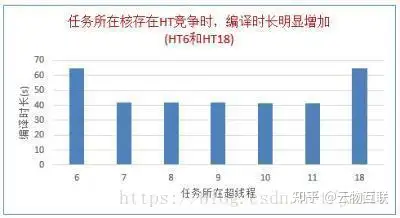
在同一个核两个超线程上的负载,其运行时间大幅增加。
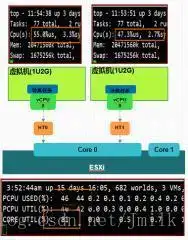
在 vSphere 的 ESXi 主机上运行两个 1CPU 的虚拟机,分别绑定到一个核的两个超线程上,在虚拟机内部运行计算任务,确保虚拟机内部 CPU 占用率在 50% 左右,可以看到,ESXi 主机上两个超线程使用率在 45% 左右,物理核负载已经达到 80%。
NOTE:将对于计算型虚拟机的 vCPU 绑定到主机的一个 thread 上,虚拟机的性能是不好的。对于时延敏感性任务,比如用户需要及时等待任务运行结果的,在节点负载过高(NFV),引发超线程竞争时,任务的执行时长会显著增加,影响用户体验;对于后台计算型任务,比如超算中心上运行的后台计算型任务(一般要运行数小时或数天),建议开启超线程提高整个节点的吞吐量。
CPU 绑定
**CPU 绑定:**将虚拟机的 vCPUs 绑定到 pCPUs,vCPU 只会在指定的 pCPU 上运行,避免 pCPU 间线程切换(上下文切换,内存数据转移)带来的性能开销。
openstack flavor set FLAVOR-NAME \ --property hw:cpu_policy=CPU-POLICY \ --property hw:cpu_thread_policy=CPU-THREAD-POLICY
使用此属性参数,将虚拟机的 vCPUs 连接到物理主机的 pCPUs 上。该配置能够提高虚拟机的性能。
CPU-POLICY 具有下列两种参数类型
shared:(默认的)允许 vCPUs 跨 pCPUs 浮动,尽管 vCPUs 收到了 NUMA node 的限制也是如此。
dedicated:guest 的 vCPUs 将会严格的 pinned 到 pCPUs 的集合中。在没有明确 vCPU 拓扑的情况下,Drivers 会将所有 vCPU 作为 sockets 的一个 core 或一个 thread(如果启动超线程)。如果已经明确的将 vCPUs Topology Pinned 到 CPUs Topology 中时,会严格执行 CPU pinning,将 guest CPU 的拓扑匹配到已经 pinned 的 CPUs 的拓扑中。此时的 overcommit ratio 为 1.0。例如:虚拟机的两个 vCPU 被 pinned 到了一个物理主机的 core 的两个 thread 上,那么虚拟机将会获得一个 core(对应的两个 thread)的拓扑。
NOTE:这里常结合 NUMA topology 来一起使用。如果设定为 shared,那么即便为虚拟机分配了一个 NUMA node,但 vCPUs 仍会在 NUMA node 所拥有的 pCPUs 间浮动;如果设定为 dedicated,那么虚拟机就会严格按照 guest NUMA topology 和 host NUMA topology 的映射关系将 vCPUs pinned to pCPUs,实现 CPU 的绑定。而且这种映射,往往是一个 vCPU 被绑定到一个 pCPU 的 Core 或 Thread 上(如果开启超线程)。
CPU-THREAD-POLICY
prefer:(默认的)主机也许是 SMT 架构,如果是 SMT 架构,那么将会优先将一个 vCPU 绑定到一个物理主机的 thread siblings 上,否则按照一般的方式将 vCPU 绑定到 core 上。
isolate:主机不应该是 SMT 架构,或者能够识别 thread siblings 并从逻辑上屏蔽它。每一个 vCPU 都将会被 pinned 到一个物理 CPU 的 Core 上(如果是多核 CPU)。如果物理机是 SMT 架构支持超线程,那么物理 Cores 就具有 Thread siblings,这样的话,如果一个 guest 不同的 vCPU 被 pinned 到不同的物理 Core 上,那么这个物理 Core 将不会再继续接受其他 guest 的 vCPU。所以,需要保证物理 Core 上没有 Thread siblings。
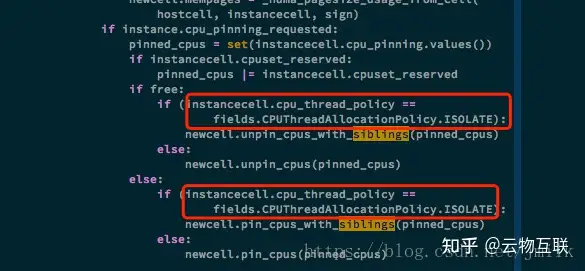
NOTE:unpin_cpus_with_siblings、pin_cpus_with_siblings 将属于同一个 thread siblings 的 CPUs 一次性 Pinned 掉,等同于消耗掉了一颗物理 Core。这两个方法是为了在超线程场景中,能够消除超线程带入的重叠 Thread,保持了物理 Core 的唯一性。
require:物理主机必须是 SMT 架构,每一个 vCPU 都分配给 thread siblings。但如果没有足够的 thread siblings,则会调度失败。如果主机不是 SMT 架构,则配置无效。
NOTE:只有设定 hw:cpu_policy=dedicated 时,hw:cpu_thread_policy 才会生效。可见,后者设定的是 vCPU pinning to pCPU 的策略。
NOTE:在启动了超线程的 SMT-Base(simultaneous multithreading-based,基于同步多线程) 架构中,Core 通常被成为 hardware thread,而使用超线程技术虚拟出来的 Cores 被称为 thread siblings。
NOTE:SMT 架构,也就是以前的 Hyper-Threading 超线程技术,支持将一个物理 Core 虚拟为多个 Thread(伪核)。
NOTE:应该使用 HostAggregate 来区分开 pinned 和 unpinned 的虚拟机,因为 unpinned 的虚拟机不会考虑到 pinned 的虚拟机的资源需求,避免发生资源占用。
NOTE:一个虚拟机在物理主机上就是一个进程,一个 vCPU 在物理主机上就是一个特殊的线程。
NOTE:专有 CPU 约束,如果为虚拟机设置物理 CPU 绑定,那么其他虚拟机要避免使用该虚拟机的专有物理 CPU。
在主机配置时,为所有虚拟机创建两个资源组,为两个组分配不同的物理。CPU。使用专有资源的虚拟机与共享资源的虚拟机分别使用两个不同的资源组。
准备一些不超配的主机只用于专用资源。
当出现一个需要专有资源的虚拟机时,动态更新所有现有虚拟机的物理 CPU 绑定。
为所有的虚拟机预先设置物理 CPU 亲和性,以预留一部分物理 CPU 为后面的专有资源虚拟机使用。
为虚拟机设置固定的调度时间片,允许他们在物理 CPU 之间自由调度。
_get_host_numa_topology:
cells:对应 NUMA nodes
online_cpus:表示所有的 Logical Processors 逻辑核,对应 CPU ID,例如:set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23])
cpuset:表示同一个 Socket 中的 Logical Processors 逻辑核,例如:Socket 0 的 cpuset=set([0, 1, 2, 3, 4, 5, 12, 13, 14, 15, 16, 17])
siblings:同一个物理 CPU Core 虚拟出来的 Logical Processors 的集合(通常为 2 个)。cpuset 中的 CPU 所拥有的 Logical Processors 的集合。例如 cpu 0 和 cpu 12 所拥有的 siblings 都是 set([0, 12]) 表示 0 和 12 是「超线程虚拟出来的兄妹 CPU」,两者均在同样的 Socket 和同样的 Core 中。
基本上 siblings[X] & cpuset == siblings[X],因为 siblings[X] 集合的元素就是 cpuset 中的 cpu id 的组合。
NUMA 亲和
NUMA 亲和:将虚拟机绑定 NUMA Node,guest vCPUs/RAM 都分配在同一个 NUMA node 上,充分使用 NUMA node local memory,避免访问 remote memory 的性能开销。
openstack flavor set FLAVOR-NAME \ --property hw:numa_nodes=FLAVOR-NODES \ --property hw:numa_cpus.N=FLAVOR-CORES \ --property hw:numa_mem.N=FLAVOR-MEMORY
使用此属性参数,将虚拟机的 vCPUs 线程限制到指定的 NUMA node 中,保证每一个 vCPU 都使用同一个 NUMA node 的 pCPU/RAM。若虚拟机所需要的 pCPU/RAM 资源需求大于一个 host NUAM node 资源时,可以通过下列属性参数定义划分为若干个在 host NUMA node 资源范围内的 guest NUMA topologys,再将 guest NUMA topologys 分别映射到不同的 host NUMA node 上。
FLAVOR-NODES:整数,设定 Guest NUMA nodes 的个数。如果不指定,则 Guest vCPUs 可以运行在任意可用的 Host NUMA nodes 上。
N:整数,Guest NUMA nodes ID,取值范围在 [0, FLAVOR-NODES-1]。
FLAVOR-CORES:逗号分隔的整数,设定分配到 Guest NUMA node N 上运行的 vCPUs 列表。如果不指定,vCPUs 在 Guest NUMA nodes 之间平均分配。
FLAVOR-MEMORY:整数,单位 MB,设定分配到 Guest NUMA node N 上 Memory Size。如果不指定,Memory 在 Guest NUMA nodes 之间平均分配。
NOTE:只有在设定了 hw:numa_nodes 后 hw:numa_cpus.N 和 hw:numa_mem.N 才会生效。另外,只有当 Guest NUMA node 存在非对称访问 CPUs/RAM 时(一个 Host NUMA node 无法满足虚拟机的 vCPUs/RAM 资源需求时),才需要去设定这些参数。
NOTE:N 仅仅是 Guest NUMA node 的索引,并非实际上的 Host NUMA node 的 ID。例如,Guest NUMA node 0,可能会被映射到 Host NUMA node 1。类似的,FLAVOR-CORES 的值也仅仅是 vCPU 的索引。因此,Nova 的 NUMA 特性并不能用来约束 Guest vCPUs/RAM 绑定到某一个 Host NUMA node 上。要完成 vCPU 绑定到指定的 pCPU,需要借助 CPU Pinning policy 和 Nova 底层隐式实现的 CPU binding(映射)机制。
WARNING:如果 hw:numa_cpus.N 和 hw:numa_mem.N 设定的值大于虚拟机本身可用的 CPUs/Memory 的话,则触发异常。
EXAMPLE:Flavor 定义 Guest 有 4 个 vCPU,4096MB 内存,设定 Guest 的 NUMA topology 为 2 个 NUMA node,vCPU 0、1 运行在 NUMA node 0 上,vCPU 2、3 运行在 NUMA node 1上。并且占用 NUMA node 0 的 Memory 2048MB,占用 NUMA node1 的 Memory 2048MB。
openstack flavor set aze-FLAVOR \ --property hw:numa_nodes=2 \ --property hw:numa_cpus.0=0,1 \ --property hw:numa_cpus.1=2,3 \ --property hw:numa_mem.0=2048 \ --property hw:numa_mem.1=2048 \
使用该 flavor 创建的虚拟机,将会具有上述 Guest NUMA topology,并由 Libvirt Driver 隐射到 Host NUMA node 上。
Nova 分配 NUMA 的两种方式:
自动分配 NUMA 的约束和限制:仅指定 Guest NUMA nodes 的个数,然后由 Nova 根据 Flavor 的规格平均将 vCPU/Memory 分布到不同的 Host NUMA nodes 上(默认从 Host NUMA node 0 开始分配,依次递增)。这将最大程度的降低配置参数的复杂性。如果没有 NUMA 节点的定义,管理程序可以在虚拟机上自由使用 NUMA 拓扑。
不能设置
numa_cpus和numa_mem自动从 0 节点开始平均分配
手动指定 NUMA 的约束和限制:不仅指定 Guest NUMA nodes 的个数,还指定了每个 Guest NUMA nodes 上分配的 vCPU ID 和 Memory Size,设定了 Guest NUMA topology。由 Nova 来完成 Guest NUMA nodes 和 Host NUMA nodes 的映射关系。
设定的 vCPU 总数需要和虚拟机 flavor 中的 CPU 总数一致
设定的 Memory 大小需要和虚拟机 flavor 中的 memory 大小一致
必须设置
numa_cpus和numa_mem需要从 Guest NUMA node 0 开始指定各个 numa 节点的资源占用参数
NOTE 1:nova-compute 的 ResourceTracker 会定时上报 Host NUMA 的资源信息。 NOTE 2:Setup Flavor extra-specs 实际上是设定 Guest NUMA Topology。 NOTE 3:Guest vCPU/Memory 不能大于虚拟机自身 flavor 所拥有的 CPU/Memory 规格。 NOTE 4:如果 Guest NUMA node 的 vCPU/Memory 规格大于 Host NUMA node 的 CPU/Memory 规格,则应该讲 Guest NUMA node 划分为多个 nodes。 NOTE 5:如果 hw:numa_cpus.N 或 hw:numa_mem.N 设定的值比 Host 可用 CPU/Memory 大,则会引发错误。 NOTE 6:hw:numa_cpus.N 与 hw:numa_mem.N 只在设置了 hw:numa_nodes 后有效。 NOTE 7:N 是 Guest NUMA node 的索引 ID,并非实际上的 Host NUMA node ID。例如,Guest NUMA node(hw:numa_mem.0),可能会被映射到 Host NUMA node 1。类似的,FLAVOR-CORES 也值是 vCPU 的编号,并不对应 pCPU。因此,Nova 的 NUMA 特性并不能用来约束 Guest vCPU/Memory 所处于的 Host NUMA node。要完成 vCPU 绑定到指定的 pCPU,还需要应用 Nova 的 CPU binding 机制。 NOTE 8:在最终的 XML 文件里面可能并没有 numatune 信息,因此从 XML 无法看出 Guest NUMA node 的 Memory 是从哪个 Host NUMA node 上分配的,在 RHEL 中,默认的 Memory 分配方式与 CPU 分配方式是一致的,但是在 SUSE OS 上,就需要指定 numatune 信息才能生效。
除了通过 Flavor extra-specs 来设定 Guest NUMA topology 之外,还可以通过 Image Metadata 来设定。e.g.
glance image-update --property \ hw_numa_nodes=2 \ hw_numa_cpus.0=0 \ hw_numa_mem.0=512 \ hw_numa_cpus.1=0 \ hw_numa_mem.1=512 \ image_name
NOTE:当用户镜像的 NUMA 约束与虚拟机类型的 NUMA 约束冲突时,以虚拟机类型约束为准。
调度器使用虚拟机类型的参数 numa_nodes 决定如何布置虚拟机。如果没有设置 numa_nodes 参数, 调度器将自由决定在哪里运行虚拟机,而不关心单个 NUMA 节点是否能够满足虚拟机类型中的内存设置,尽管仍然会优先考虑一个 NUMA 节点可以满足情况的主机。
如果参数
numa_nodes设置为 1,调度器 将会选择单个 NUMA 节点能够满足虚拟机类型中内存设置的主机。如果参数
numa_nodes设置大于 1,调度器将会选择 NUMA 节点数量与 NUMA 节点中内存能够满足虚拟机类型中 numa_nodes 参数与内存设置的主机。
ComputeNode 将会暴露他们的 NUMA 拓扑信息(例如:每个 NUMA 节点上有多少 CPU 和内存),以及当前的资源利用率。这些数据会被加入到计算节点的数据模型(compute_nodes)中。
应用场景:
hw:huma_nodes=1,应该让 Guest 的 vCPU/Memory 从一个固定的 Host NUMA node 中获取,避免跨 NUMA node 的 Memory 访问,减少不可预知的通信延时,提高 Guest 性能。hw:huma_nodes=N,当 Guest 的 vCPU/Memory 超过了单个 Host NUMA node 占有的资源时,手动将 Guest 划分为多个 Guest NUMA node,然后再与 Host NUMA node 对应起来。这样做有助于 Guest OS 感知到 Guest NUMA 并优化应用资源调度。(e.g. 数据库应用)hw:huma_nodes=N,对于 Memory 访问延时有高要求的 Guest,即可以将 vCPU/Memory 完全放置到一个 Host NUMA node 中,也可以主动将 Guest 划分为多个 Guest NUMA node,再分配到 Host NUMA node。以此来提高总的访存带宽。(e.g. NFV/搜索引擎)如果 N == 1,表示 Guest 的 vCPU/Memory 固定从一个 Host NUMA node 获取
如果 N != 1,表示为 Guest 划分 N 和 Guest NUMA node,并对应到 N 个 Host NUMA node 上
大页内存
大页内存:使用大页来进行内存分配,那么将会明显减少 CPU 页表项,因此会增加页表缓存的命中率,降低内存访问延迟。
与 NUMA 不同,如果虚拟机类型中声明了大页内存,则需要主机能够进行预留该内存块。因为这些内存同时也作为该主机上的 NUMA 节点专用内存,所以必须提前显式声明。例如,如果主机配置了大页内存,也应该从 NUMA 节点中分配。
透明巨型页技术允许主机出现内存超配,并且调度程序可以使用该特性。如果主机支持内存预分配,主机将会上报是否支持保留内存或者 THP,甚至在严格条件下,可以上报剩余可用内存页数。如果虚拟机使用的主机类型中将 huge_pages 参数设置为 strict 时,并且没有主机在单 NUMA 节点中拥有足够的大页内存可用,调度器将会返回失败。
openstack flavor set FLAVOR-NAME \ --property hw:mem_page_size=PAGE_SIZE
PAGE_SIZE
small:(默认)使用最小的 page size,例如:4KB on x86 架构
large:只为 Guest 使用的 larger page size,例如:2MB 或 1GB on x86 架构
any:有 Nova virt drivers 决定,不同的 driver 具有不同的实现。
<pagesize>:字符串,显式自定义 page size,例如:4KB/2MB/2048/1GB
NOTE:针对虚拟机的 RAM 可以启动 large page 特性,可以有效提供虚拟机性能。
NOTE:将大页内存分配给虚拟机,可以不考虑 GuestOS 是否使用。如果 GuestOS 不使用,则会识别小页内存。相反,如果 GuestOS 是需要使用大页内存的,则必须要为虚拟机分配大页内存,否则虚拟机的性能将达不到预期。
NOTE:专有内存约束
为专有资源虚拟机使用大页内存。这需要主机拥有足够的可用大页内存,并且虚拟机内存大小是大页内存大小的倍数。
在主机配置时,为所有虚拟机创建两个资源组,为两个组分配不同的物理内存区域。使用专有资源的虚拟机与共享资源的虚拟机分别使用两个不同的资源组。
专用内存的分配的复杂性还在于,主要虚拟机之外,KVM 还有许多不同的内存分配的需求,有些虚拟机处理视频内容,会在 KVM 过程处理 I/O 请求时,分配任意大小的内存。有些情况下,这也会影响虚拟 CPU 的使用,因为 KVM 模拟程序线程代表的就是虚拟机行为。更进一步讲,主机操作系统也需要内存与 CPU 资源。
只有当系统中有可用大页内存时,虚拟化程序才启动虚拟机。设置虚拟机类型参数
page_sizes=large虚拟化管理程序将会优先尝试大页内存,不可用时,使用小页内存启动虚拟机。设置虚拟机类型参数 page_sizes=any
虚拟机程序将不选择大页内存启动虚拟机,即使大页内存可用。设置虚拟机类型参数
page_sizes=small只有当系统中有可用的 1GB 大页内存时,虚拟化管理程序才启动虚拟机,并且将不会使用 2MB 的大页内存。设置虚拟机类型参数
page_sizes=1GB
PCI passthrough
可以通过下述属性参数来分配 PCI 直通设备给虚拟机。
openstack flavor set FLAVOR-NAME \ --property pci_passthrough:alias=ALIAS:COUNT
ALIAS:字符串,在 nova.conf 中配置的特定 PCI 设备的 alias。(DEFAULT pci_alias)
COUNT:整数,分配给虚拟机的 ALIAS 类型的 PCI 设备数量
Nova 实现 NUMA 的流程
1.nova-api 对 flavor metadata 或 image property 中的 NUMA 配置信息进行解析,生成 Guest NUMA topology,保存为 instance['numa_topology']
2.nova-scheduler 通过 NUMATopologyFilter 判断 Host NUMA topology 是否能够满足 Guest NUMA topology,进行 ComputeNode 调度

这里写图片描述
3.nova-compute 再次通过 instance_claim 检查 Host NUMA 资源是否满足建立 Guest NUMA。

这里写图片描述
4.nova-compute 建立 Guest NUMA node 和 Host NUMA node 的映射关系,并根据映射关系调用 libvirt driver 生成 XML 文件。
<domain> <cputune> /* vCPU 与 Host NUMA node 的绑定关系,4-7, 12-15 在一个 Host NUMA Node 节点上,0-3,8-11 在另外一个 Node 上 */ /* cpuset 设定的 pCPU 是由 libvirt 根据 Host NUMA node 资源信息自动分配的*/ <vcpupin vcpu="0" cpuset="4-7,12-15"/> <vcpupin vcpu="1" cpuset="4-7,12-15"/> <vcpupin vcpu="2" cpuset="0-3,8-11"/> <vcpupin vcpu="3" cpuset="0-3,8-11"/> <emulatorpin cpuset="0-15"/> </cputune> *** <cpu match="host-model"> <model fallback="allow"/> <topology sockets="2" cores="2" threads="1"/> /* Guest NUMA Topology,一个 cell 表示一个 Guest NUMA node,默认从 0 开始编号 */ <numa> /* cpus 表示该 Guest NUMA node 内包含的 vCPU ID,memory 表示该 Guest NUMA nova 包含的 Memory Size 大小,单位 KB*/ <cell id="0" cpus="0-1" memory="1048576"/> <cell id="1" cpus="2-3" memory="1048576"/> </numa> </cpu> </domain>
Resource Tracker 会刷新 Host NUMA 资源的使用情况:
这里写图片描述
对 NUMA 相关数据的解析和处理,提供了以下 class: vim nova/virt/hardware.py
class VirtNUMATopologyCell(object):
NUMA 单元,定义了 NUMA cell 内的基本数据成员。
class VirtNUMATopologyCellLimit(VirtNUMATopologyCell):
NUMA 限制量单元,定义了 NUMA cell 内可以使用资源的最大限。
class VirtNUMATopologyCellUsage(VirtNUMATopologyCell):
NUMA 使用量单元,定义了 NUMA cell 内已使用的资源。
class VirtNUMATopology(object):
NUMA 拓扑单元,定义了 NUMA 的基本数据成员,即 cells[]
class VirtNUMAInstanceTopology(VirtNUMATopology):
为 guest VM 提供 NUMA 相关的操作。
class VirtNUMAHostTopology(VirtNUMATopology):
为 Host 提供 NUMA 相关的操作。
查看 Host NUMA topology:
[root@control01 ~]# numactl --hardware available: 1 nodes (0) # 1 NUMA nodes node 0 cpus: 0 1 2 3 4 5 6 7 # 8 Processor node 0 size: 16383 MB # 15G Memory/Node node 0 free: 195 MB # 195M Memory/Node node distances: # 跨 Node 访问 Memory 的成本 node 0 0: 10 root@aju-dev-vmware:~# sudo virsh nodeinfo sudo: unable to resolve host aju-dev-vmware CPU model: x86_64 CPU(s): 4 CPU frequency: 2299 MHz CPU socket(s): 4 Core(s) per socket: 1 Thread(s) per core: 1 NUMA cell(s): 1 Memory size: 8176640 KiB
查看 Guest NUMA topology:
从 libvirt.xml 查看

Host OS 上执行 numastat -c qemu-system-x86_64
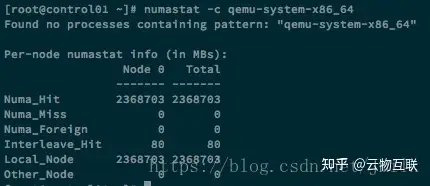
查看 Instance 的 NUMA Topology 信息
NFV 支撑:

发布于 2023-05-21 21:39・IP 属地北京



























