在VM虚拟机上安装Microsoft Dynamics CRM 2016 步骤图解及安装注意事项(转载)
本文转载 出处:http://www.cnblogs.com/lujiangping/archive/2016/06/02/5552443.html
安装Dynamics CRM 2016环境配置要求:
系统版本:Windows Server 2012 R2(必须)
SQL 版本: SQLServer2014SP1-FullSlipstream-x64-ENU(必须)
Dynamics CRM 版本:CRM2016-Server-ENU-amd64(必须)
安装步骤:
1.在虚拟机安装windows server 2012 r2,安装完后把机器名改成简单好认的(比如SQL2014,CRMServer等),后面安装CRM会用到。
2.在服务管理中安装Active Directory Domain Services(AD DS),安装完后再安装.NET Framework3.5和4.5
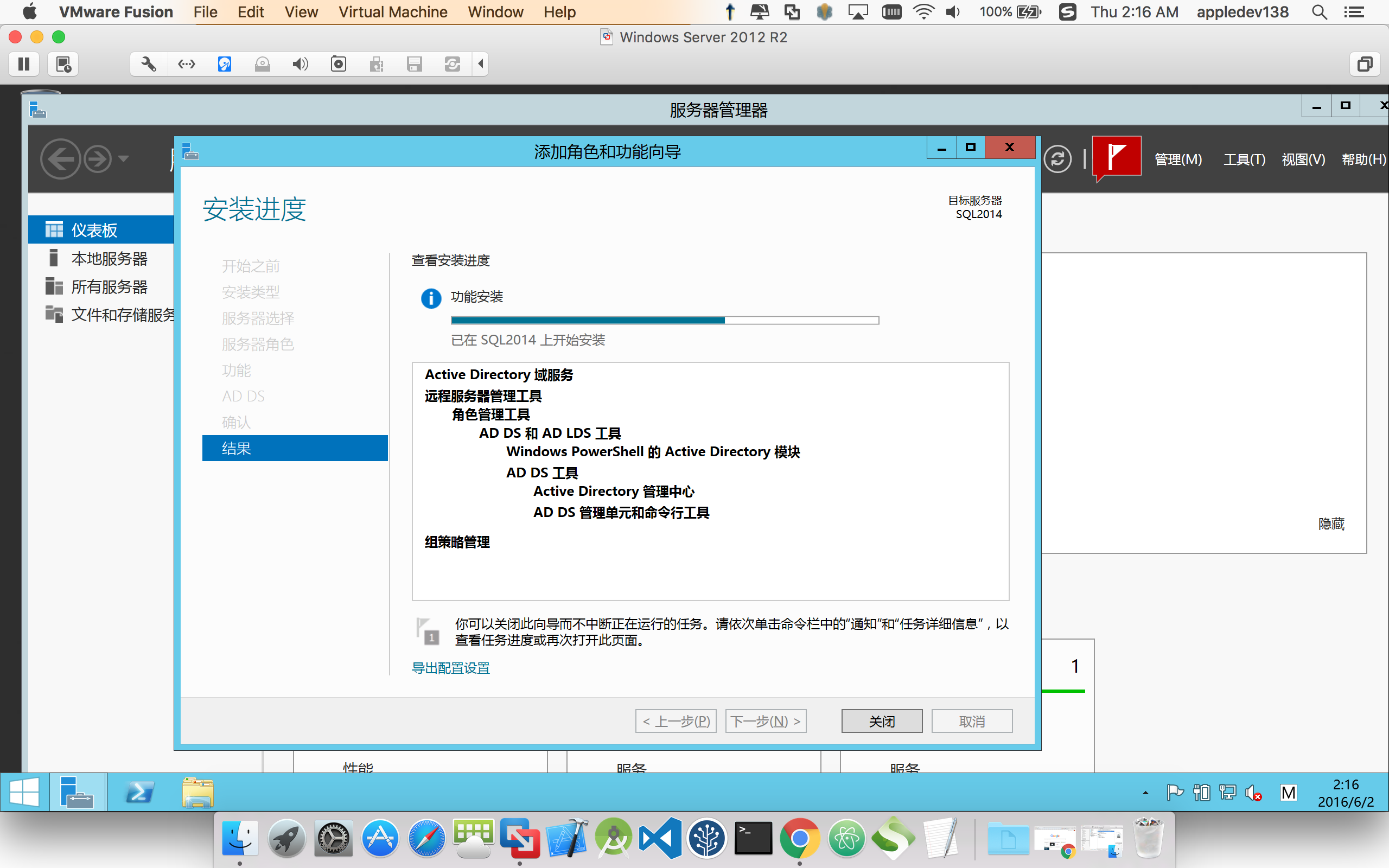
4.配置AD DS,在Server manger 顶栏小旗,点击提升为域控制器,新建林,输入域控制器名,如CRM.com,然后一路next,配置完后重启
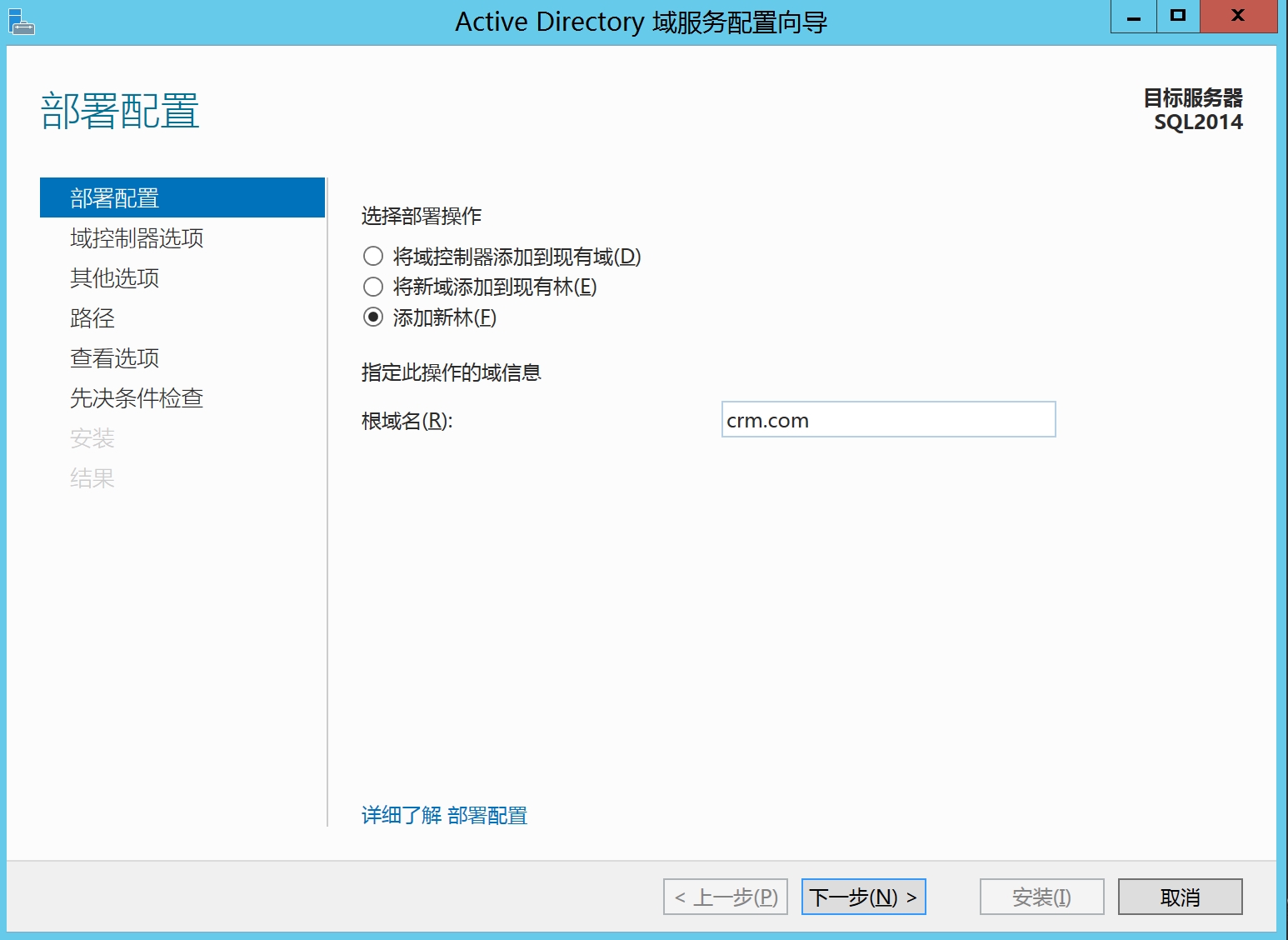
输入密码,通常为大写字母+小写字母+特殊字符
点击安装

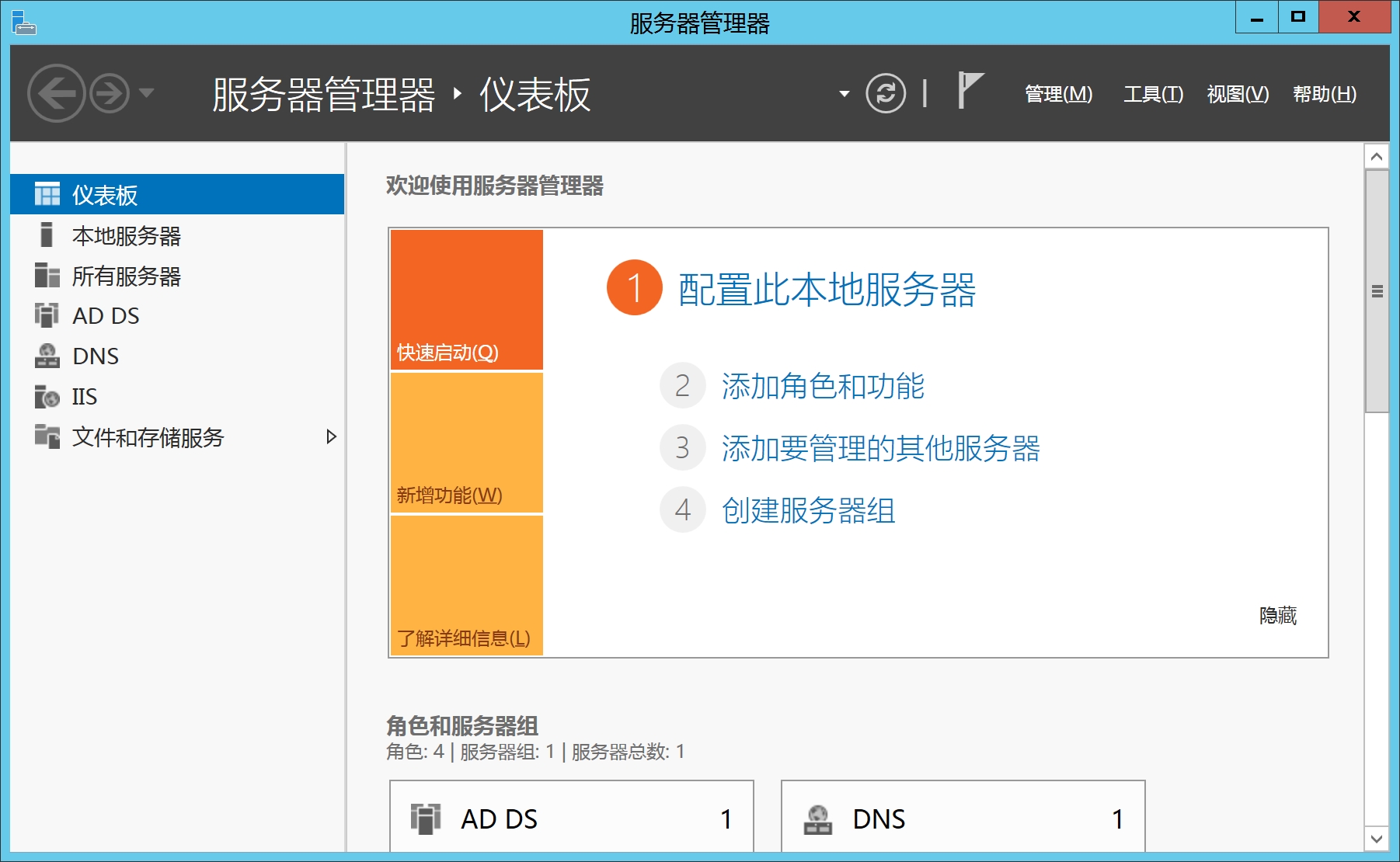
安装完AD DS,DNS Server和Web server(IIS)后服务器管理器面板
5.打开AD域用户和组,新建组织单元OU,如CRM2016, 然后在OU下新增一个User,如crmsvc,user密码改成永不过期
打开AD用户和计算机,Win + R 打开运行,输入dsa.msc,或者直接在开始下拉菜单找到AD用户计算机
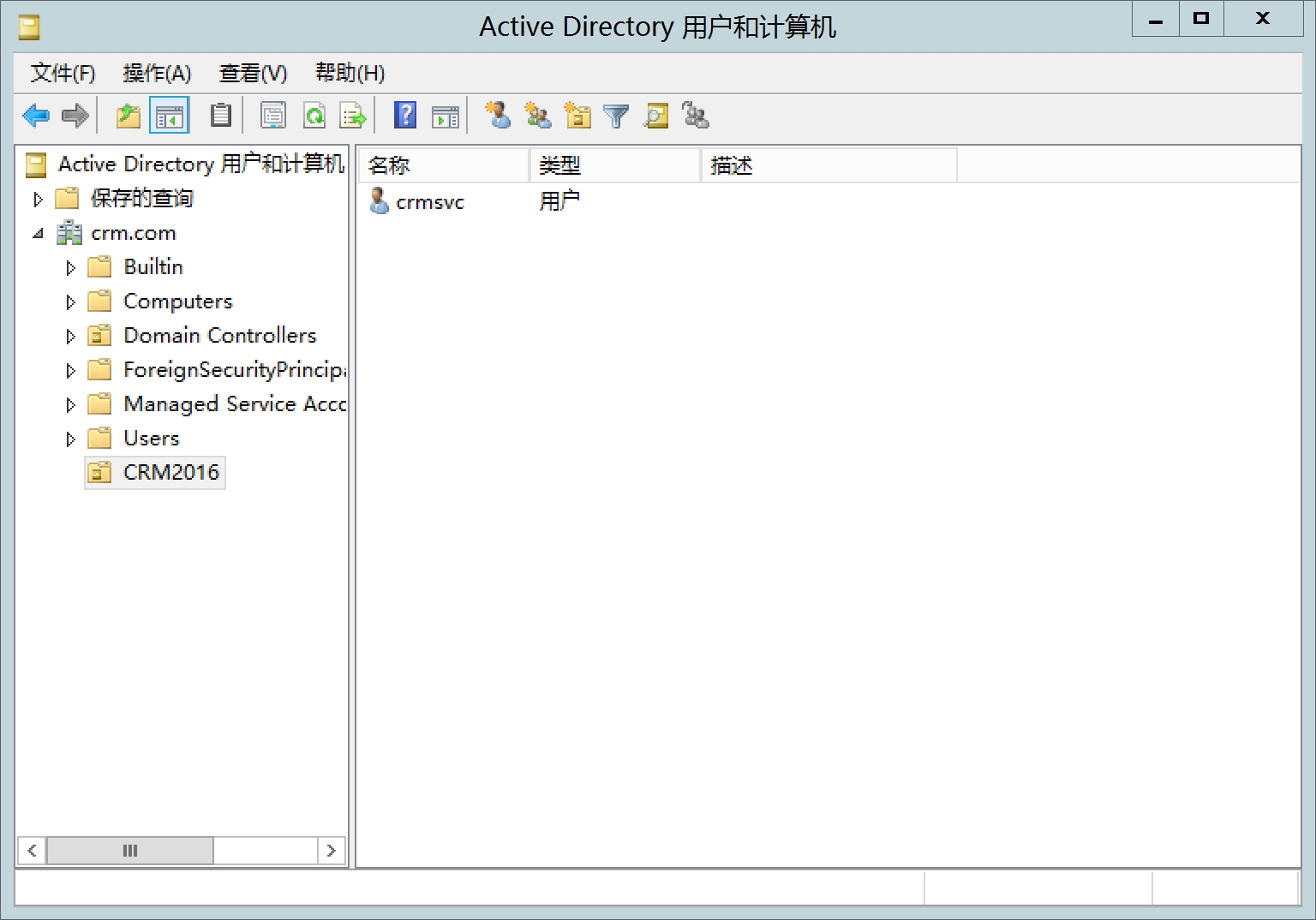
新建组织单元
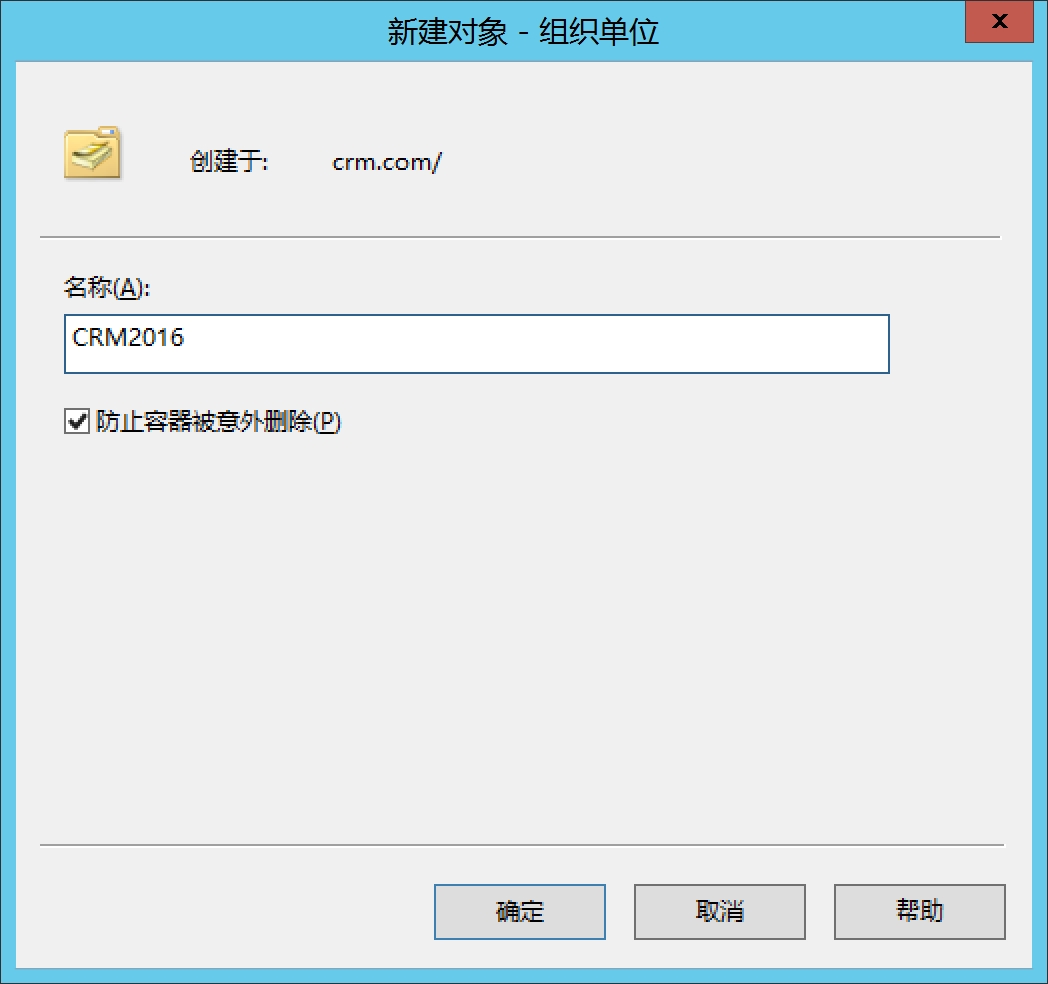
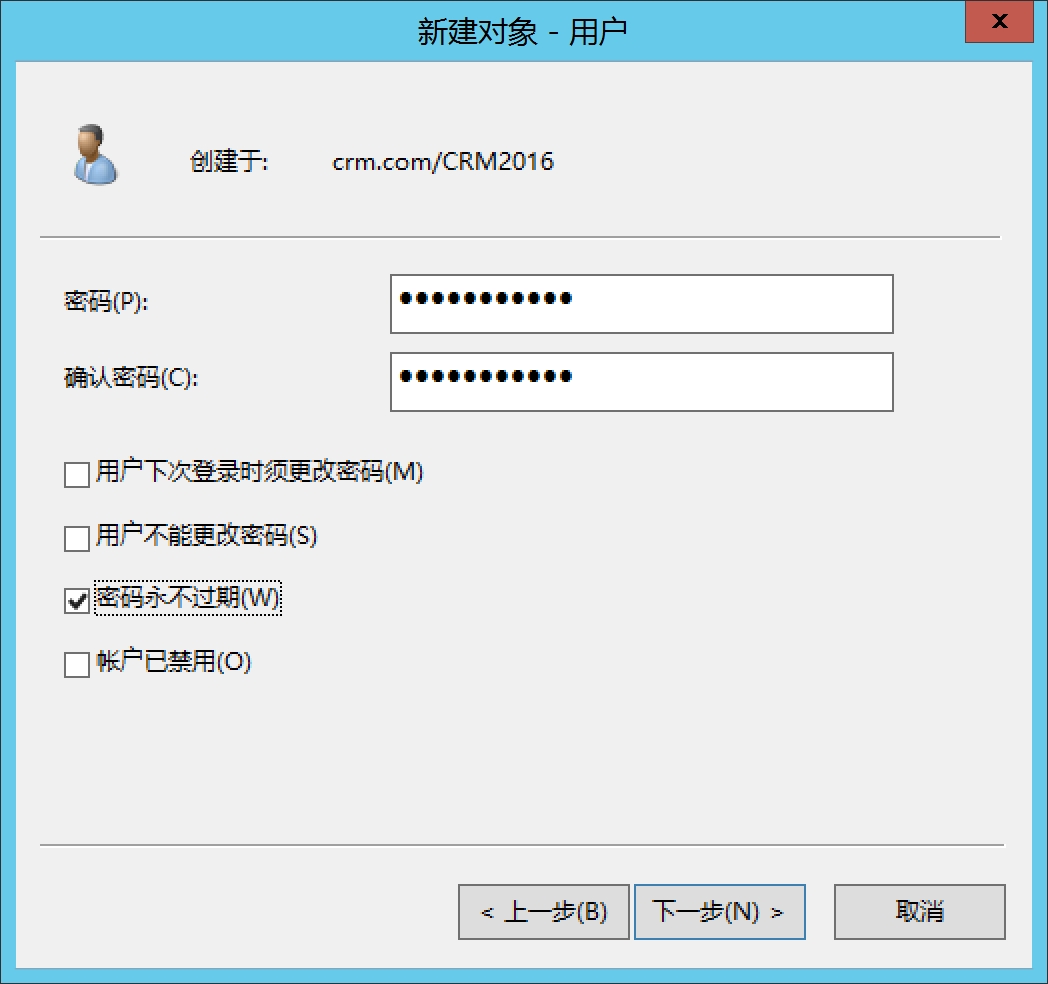
新建用户
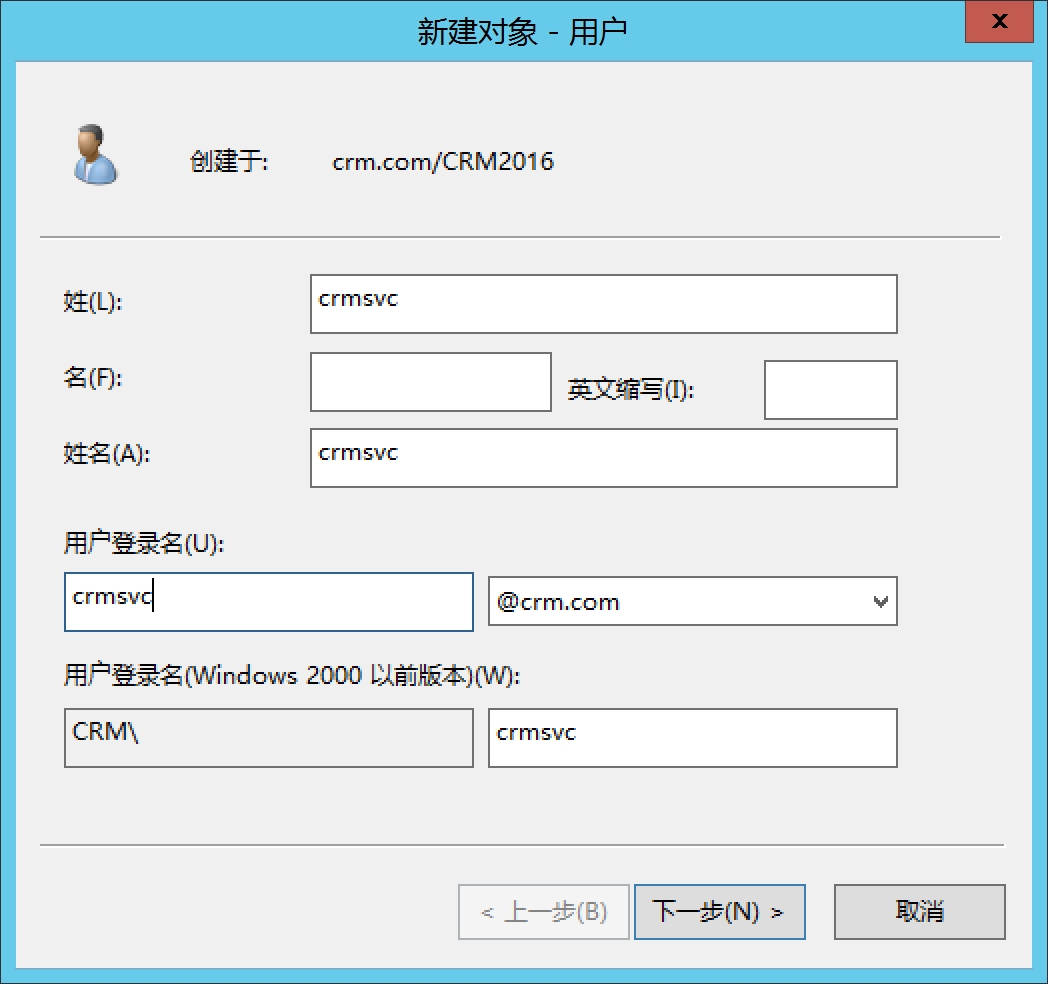
输入用户密码,取消用户下次登录必须修改密码,勾选用户密码永不过期
5.安装SQL server2014,可以参考:http://www.sqlcoffee.com/SQLServer2014_0005.htm
进入Installation,选择New SQL Server stand-alone installation or add features to an existing installation
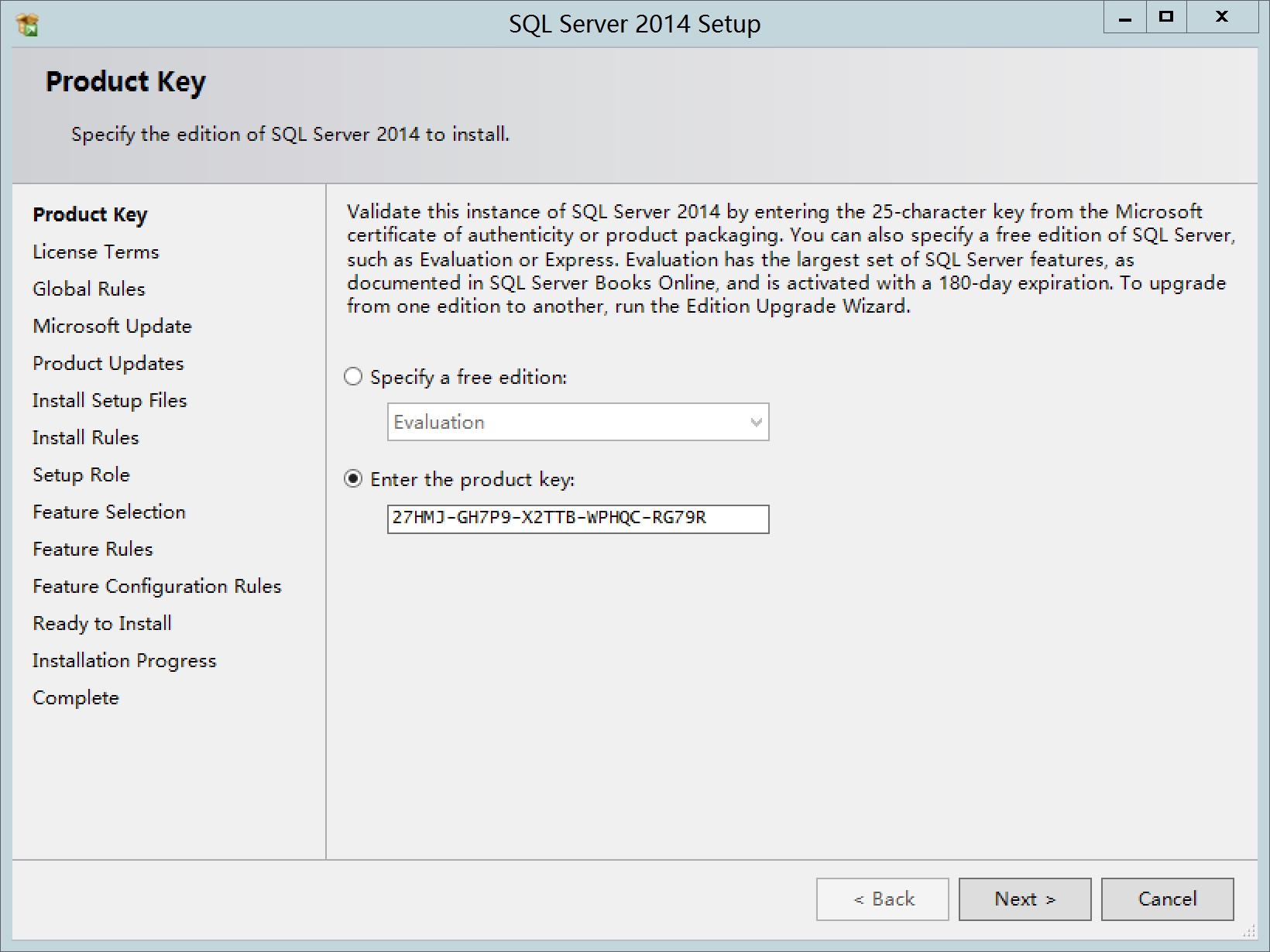
输入产品密钥
勾选I accept the license terms 和 Turn on customer Experience选项

下一步
规则检测过程中可能会有警告提示,按提示操作即可,Computer domain controller不用管,Microsoft .Net Application Security是可能没联网,Windows Firewell需要关闭防火墙
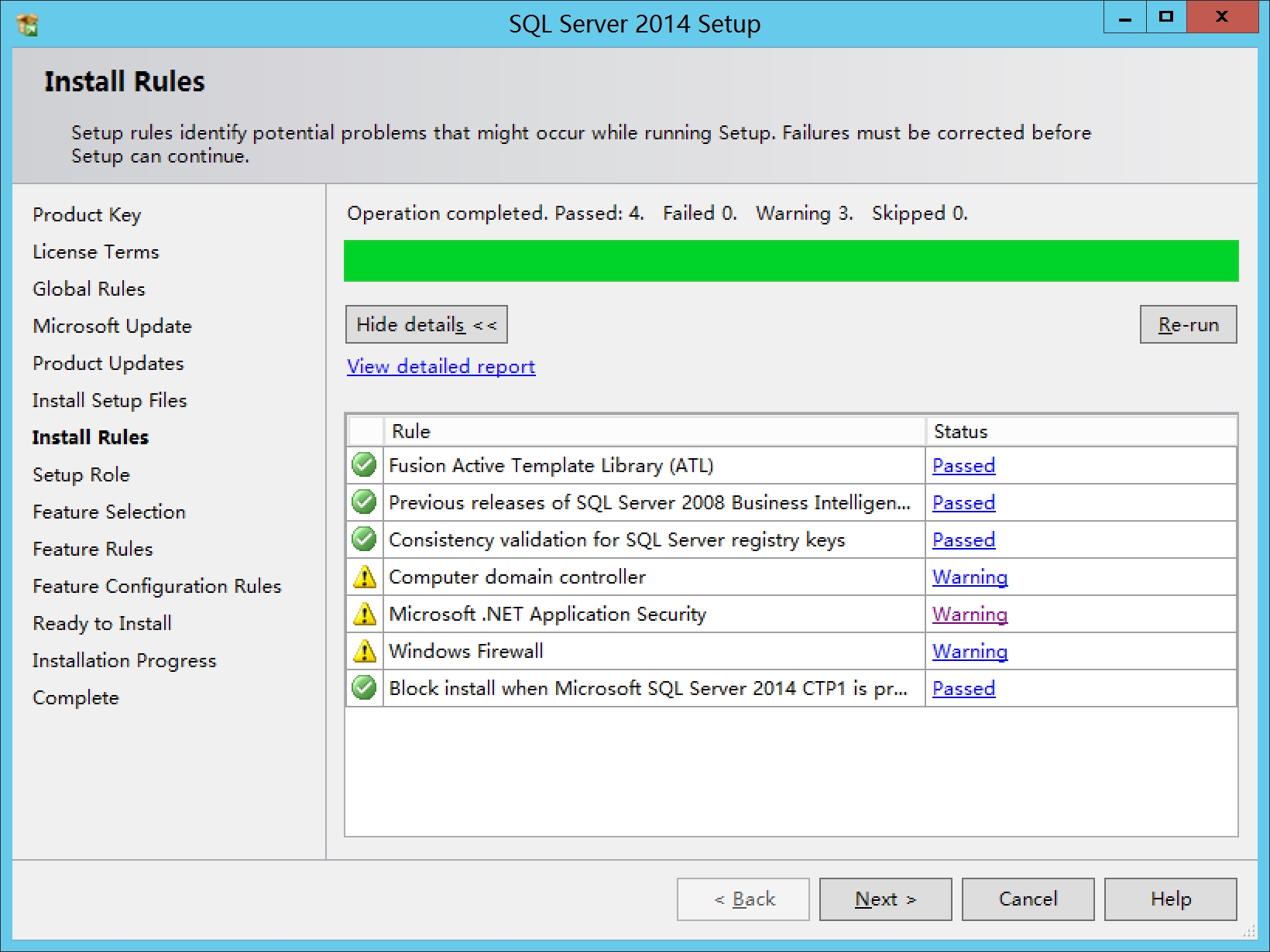
操作后
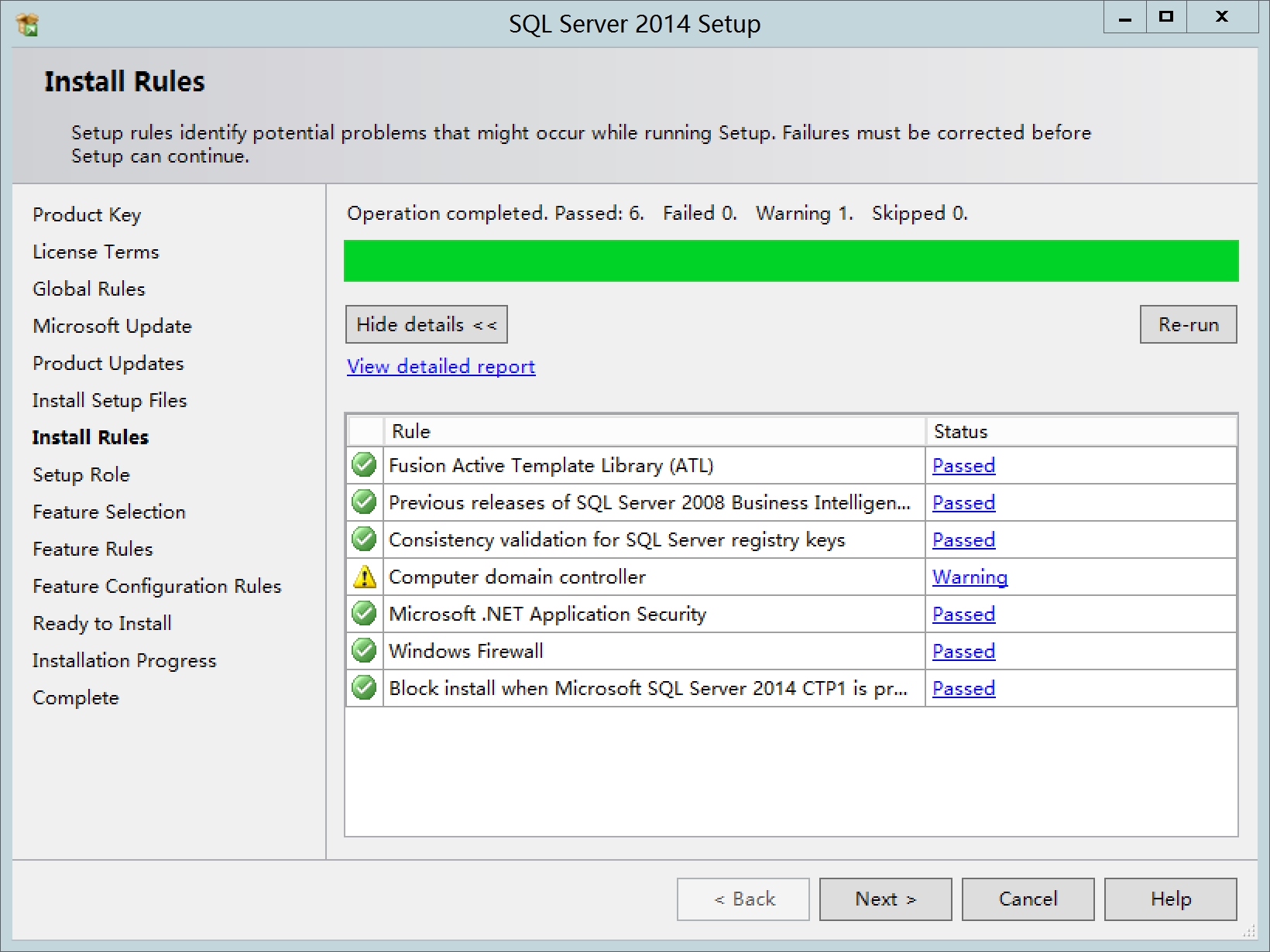
默认第一项,下一步

勾选Database Engine Services
Full-Text and Semantic Extractions for...
Reporting Services
Manager Tools Basic

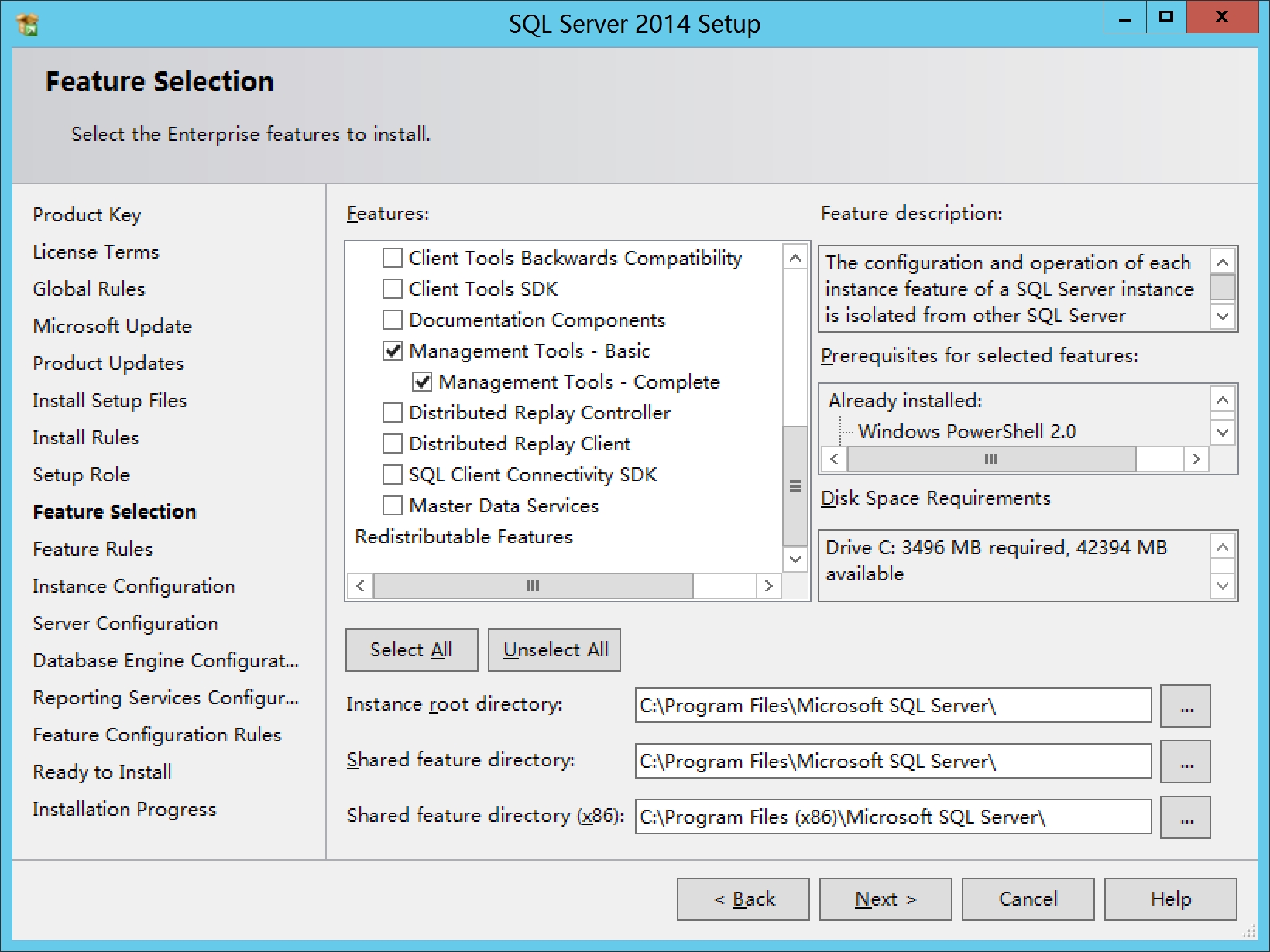
默认Instance,如果提示Instance已经被使用,可以换个新的name

下一步

点击Add Current user
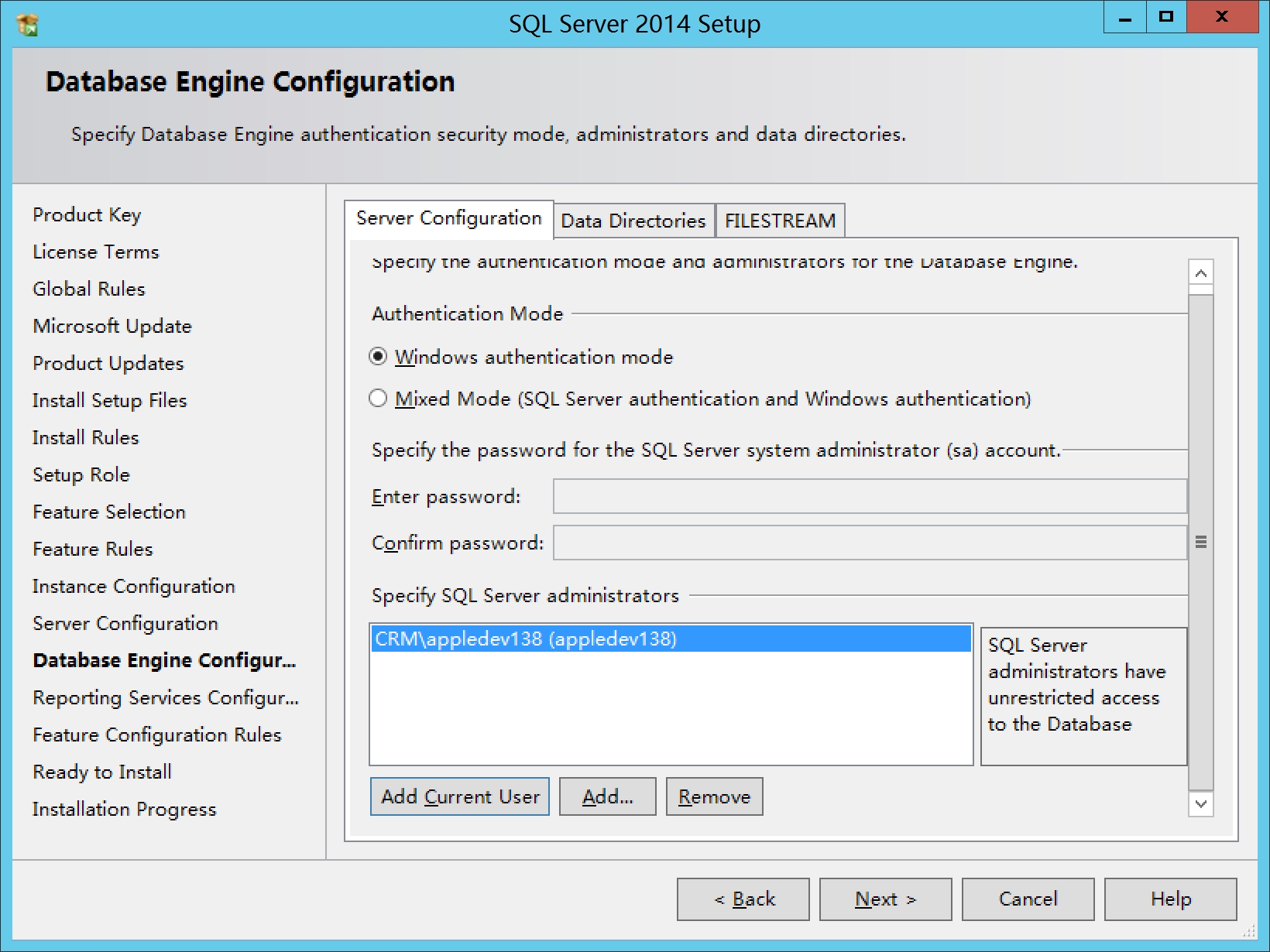
默认第一个选项,下一步

点击Install,等待安装完成
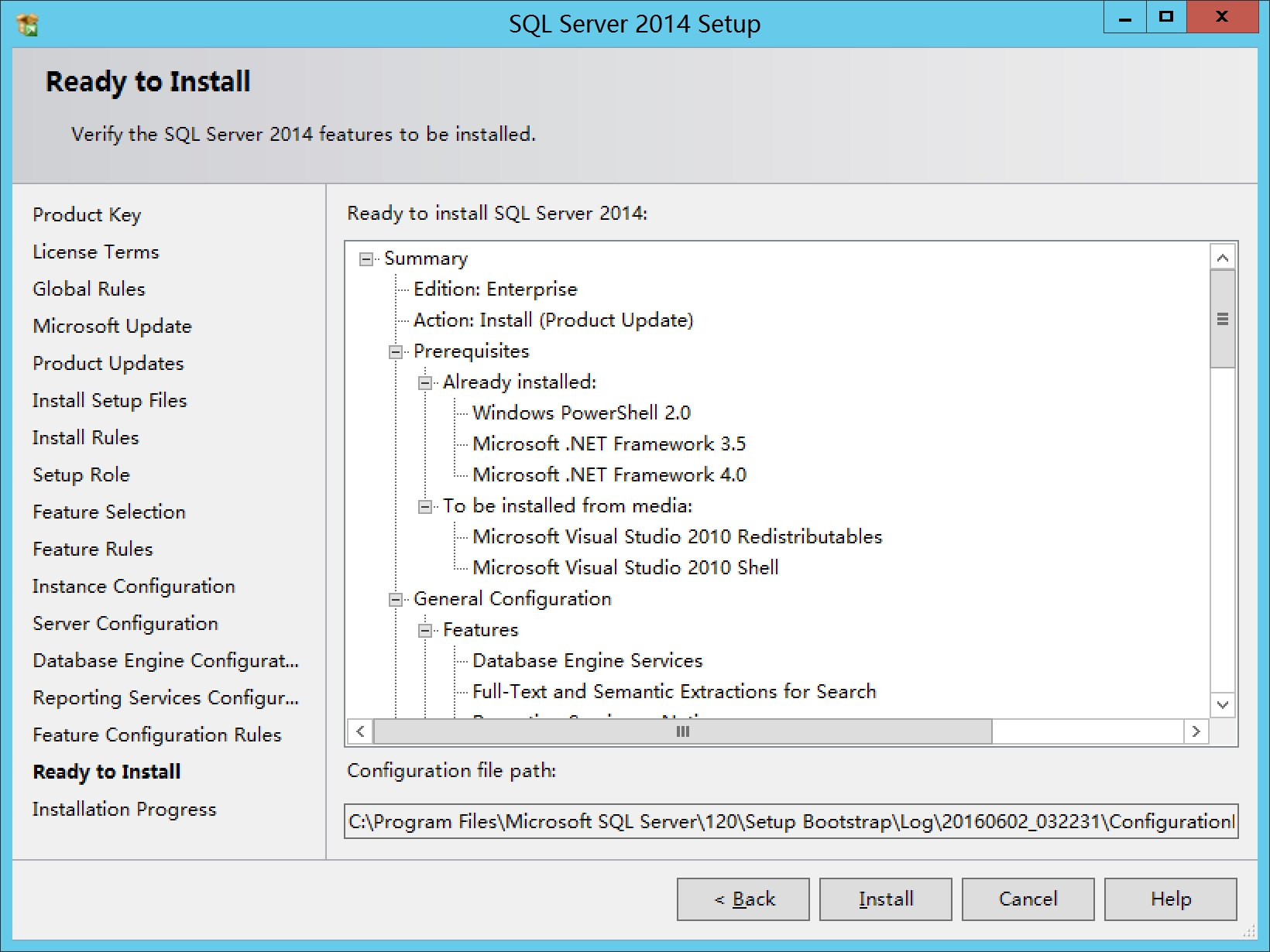
安装完成
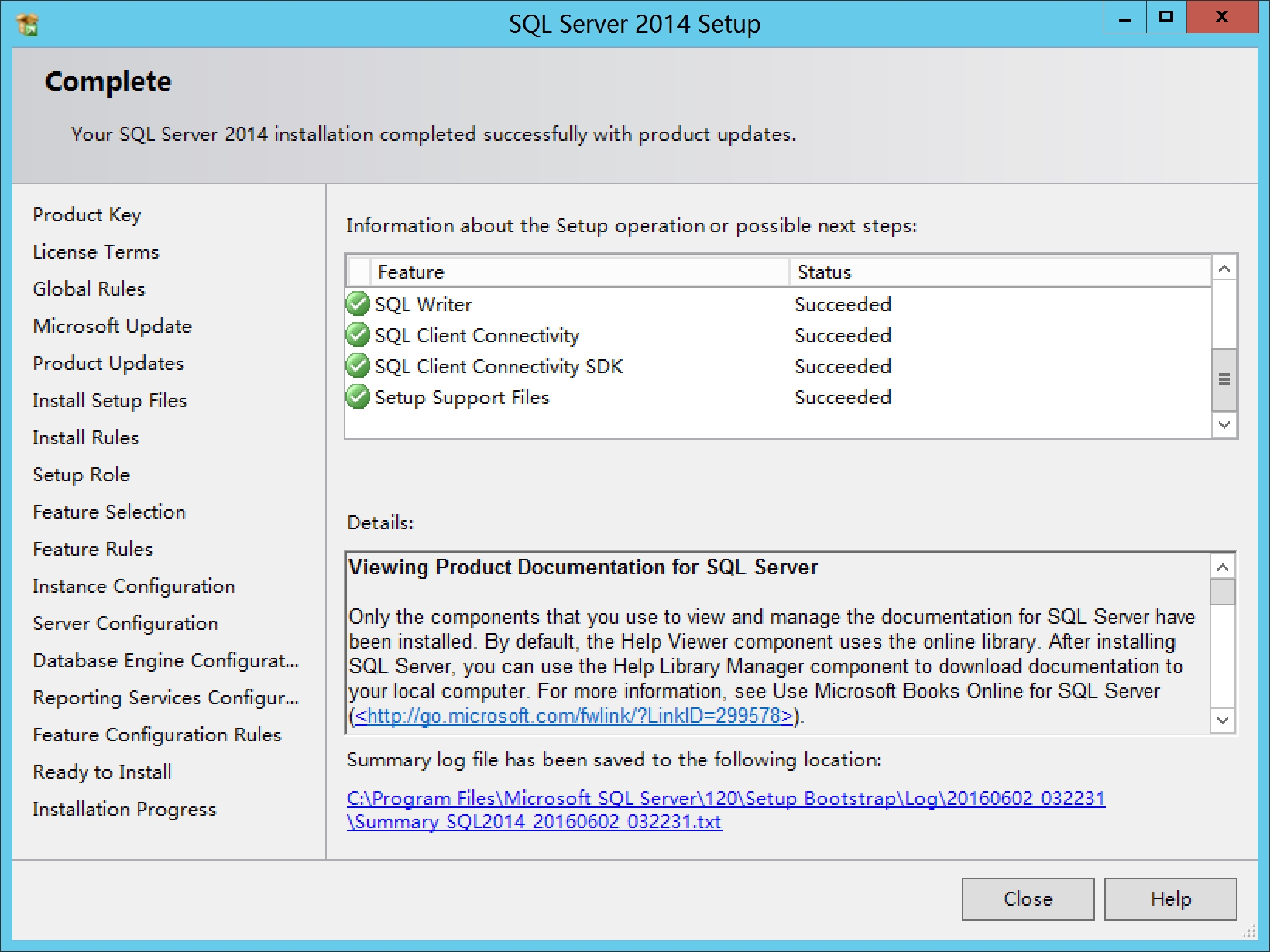
6.安装Dynamics CRM,
选择setup server.exe
输入序列号
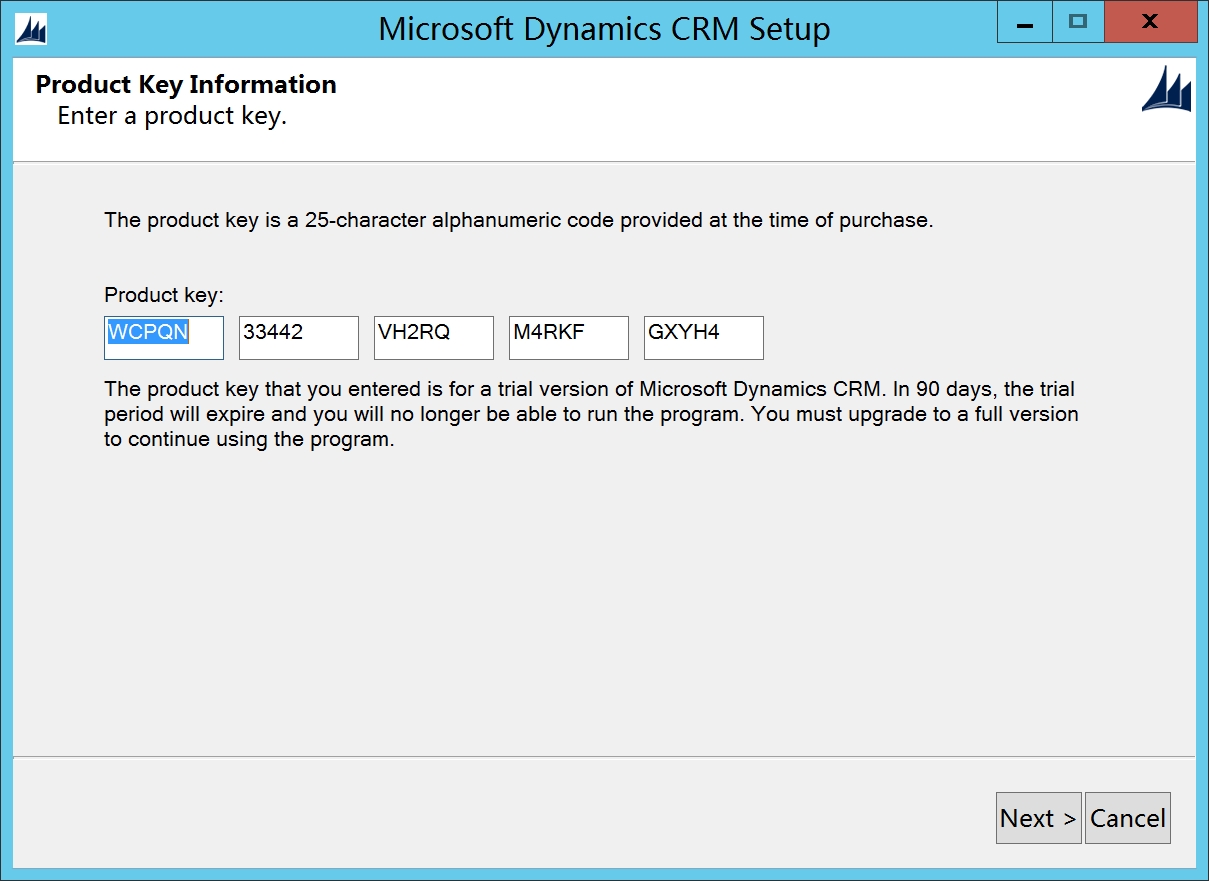
勾选I accept license
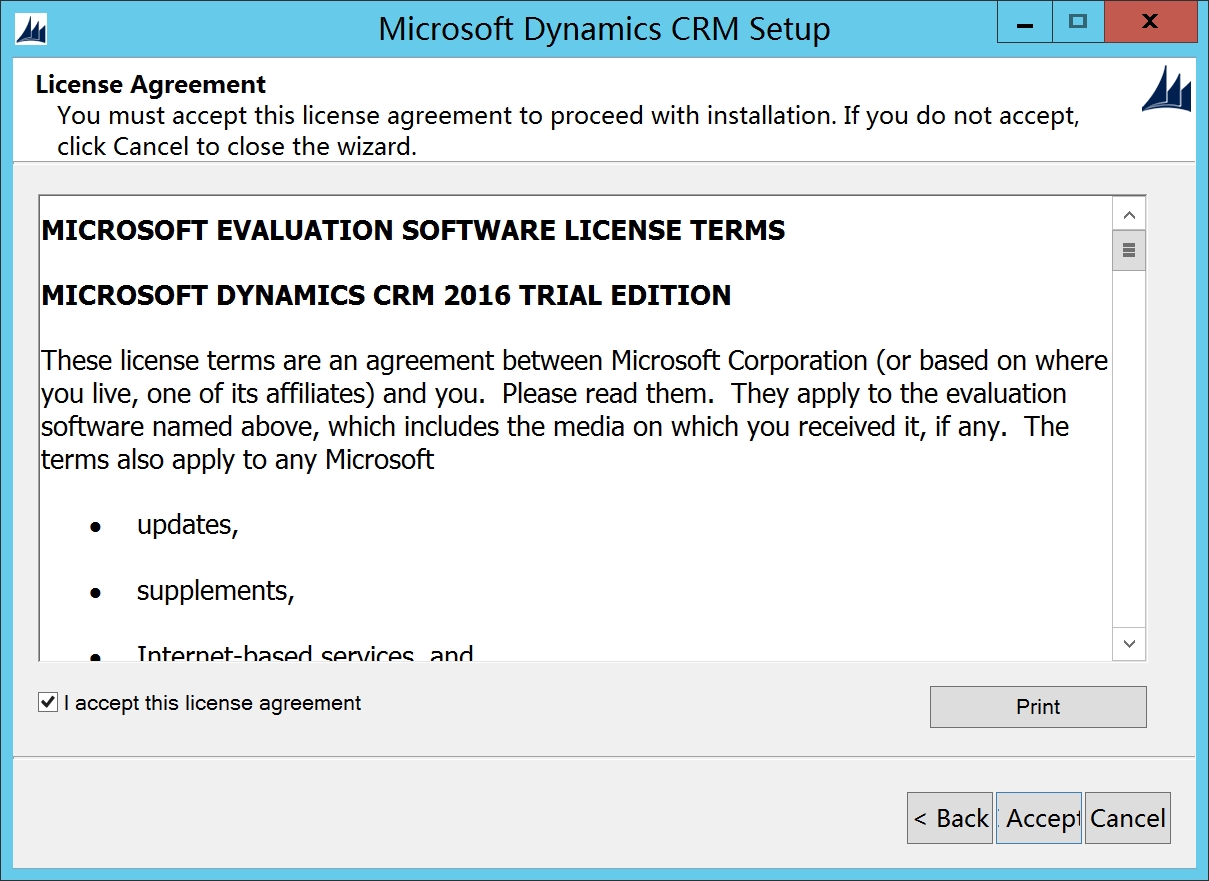
点击Install,安装预备环境软件,安装完Microsoft .NET Framework后可能需要重启,然后重新点击Setup Server.exe安装
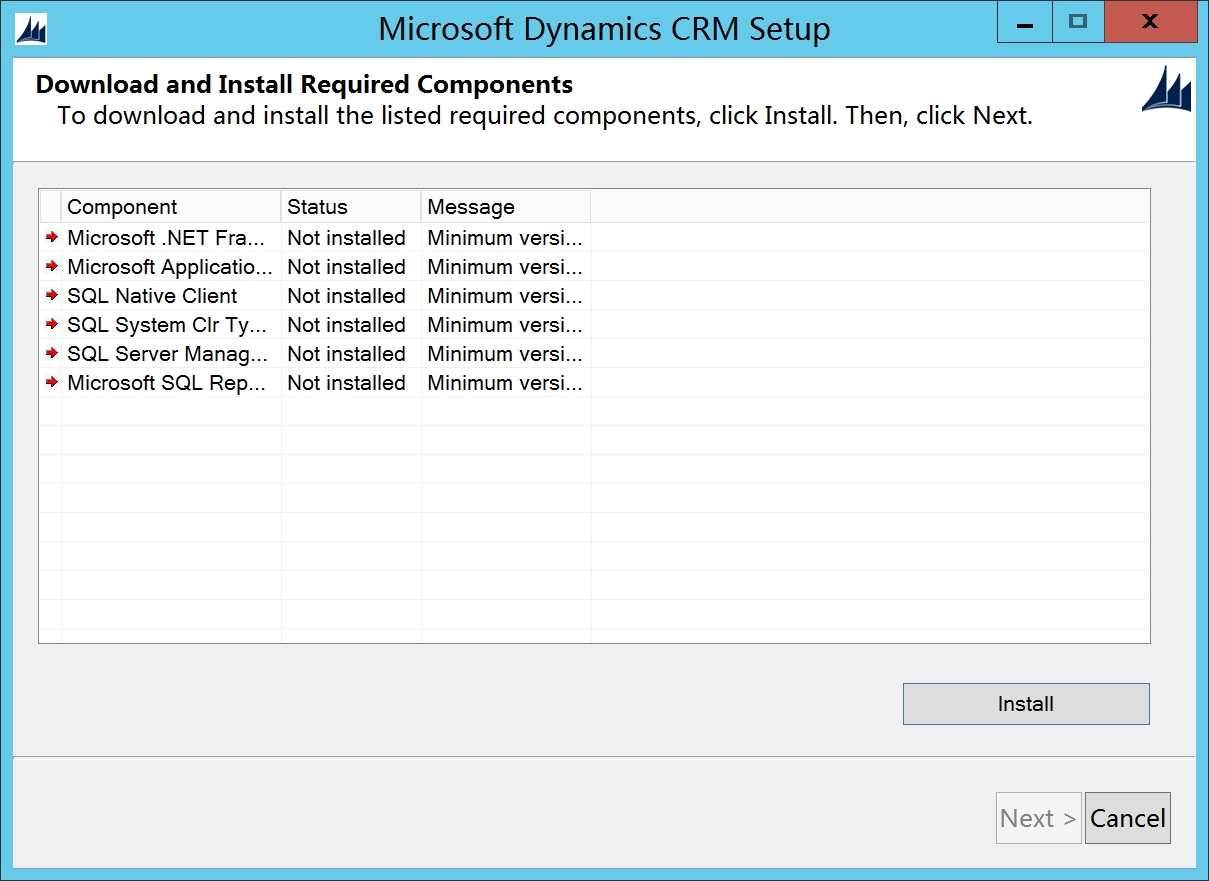
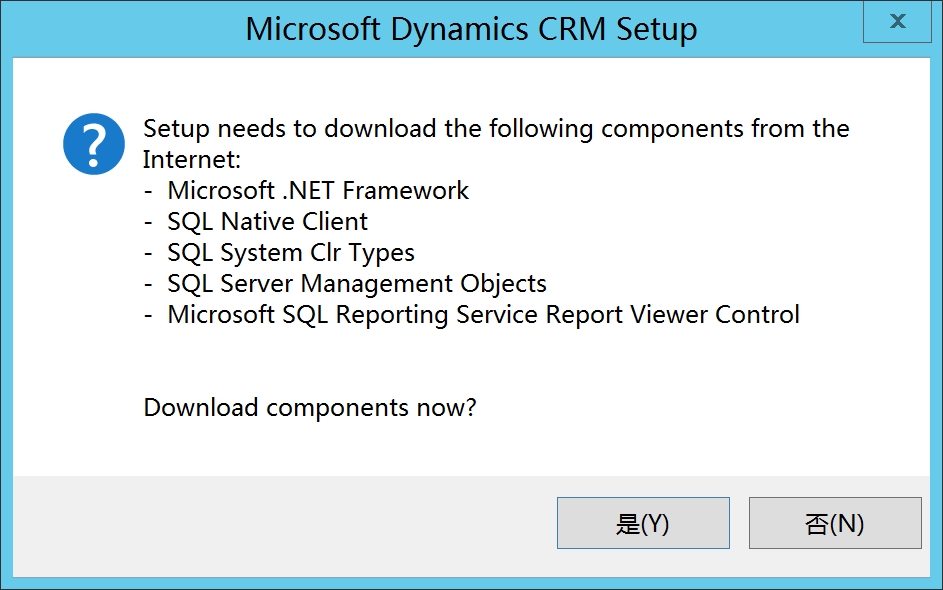
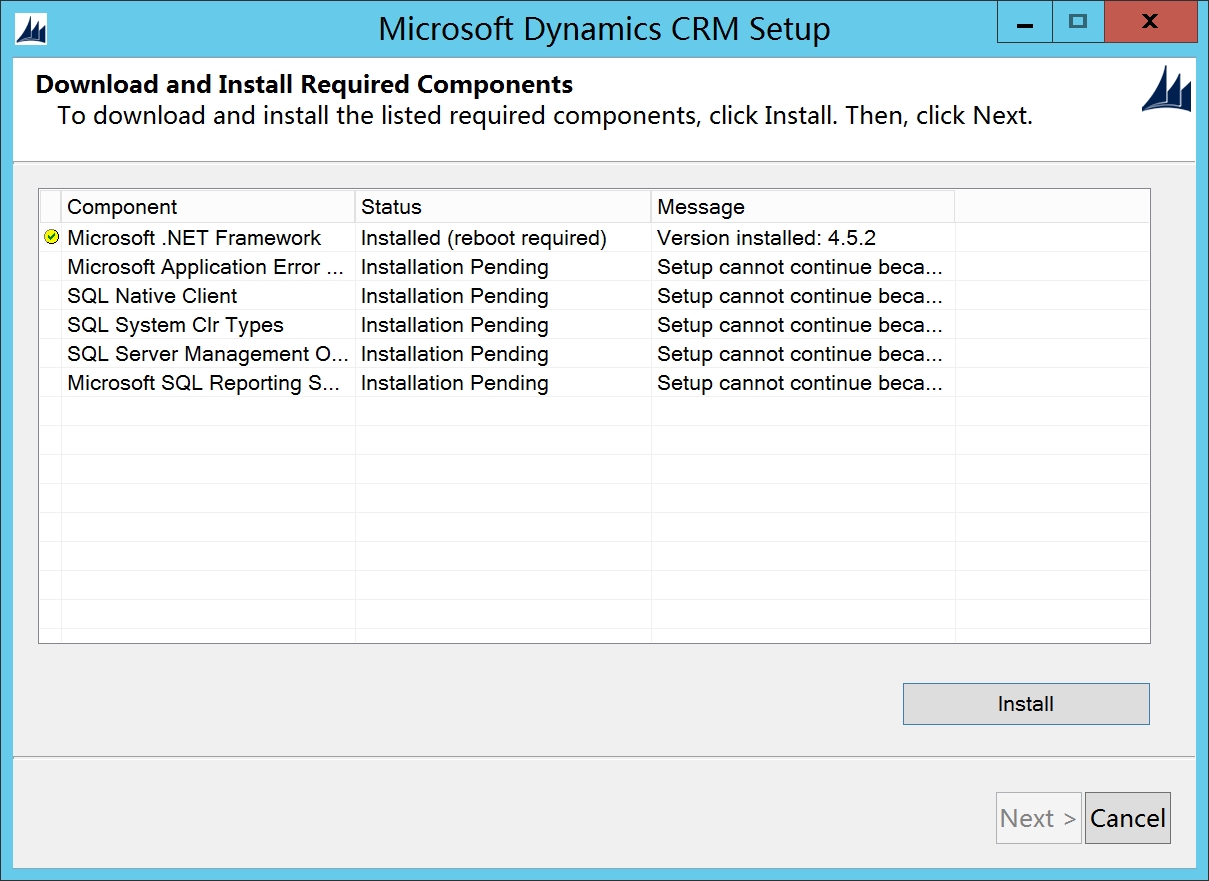
安装完预备环境软件
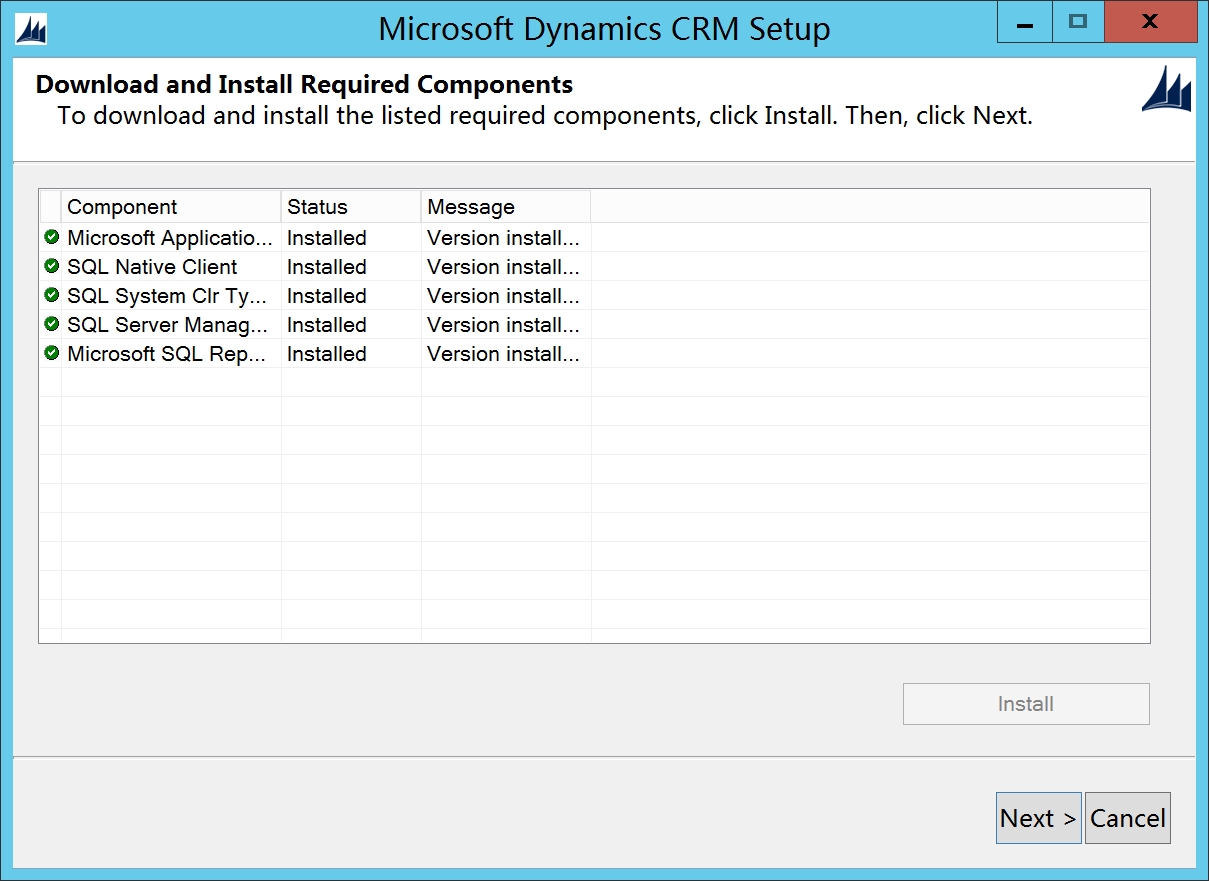
默认路径下一步

默认下一步

输入SQL server安装的计算机名称(第一步提到的)
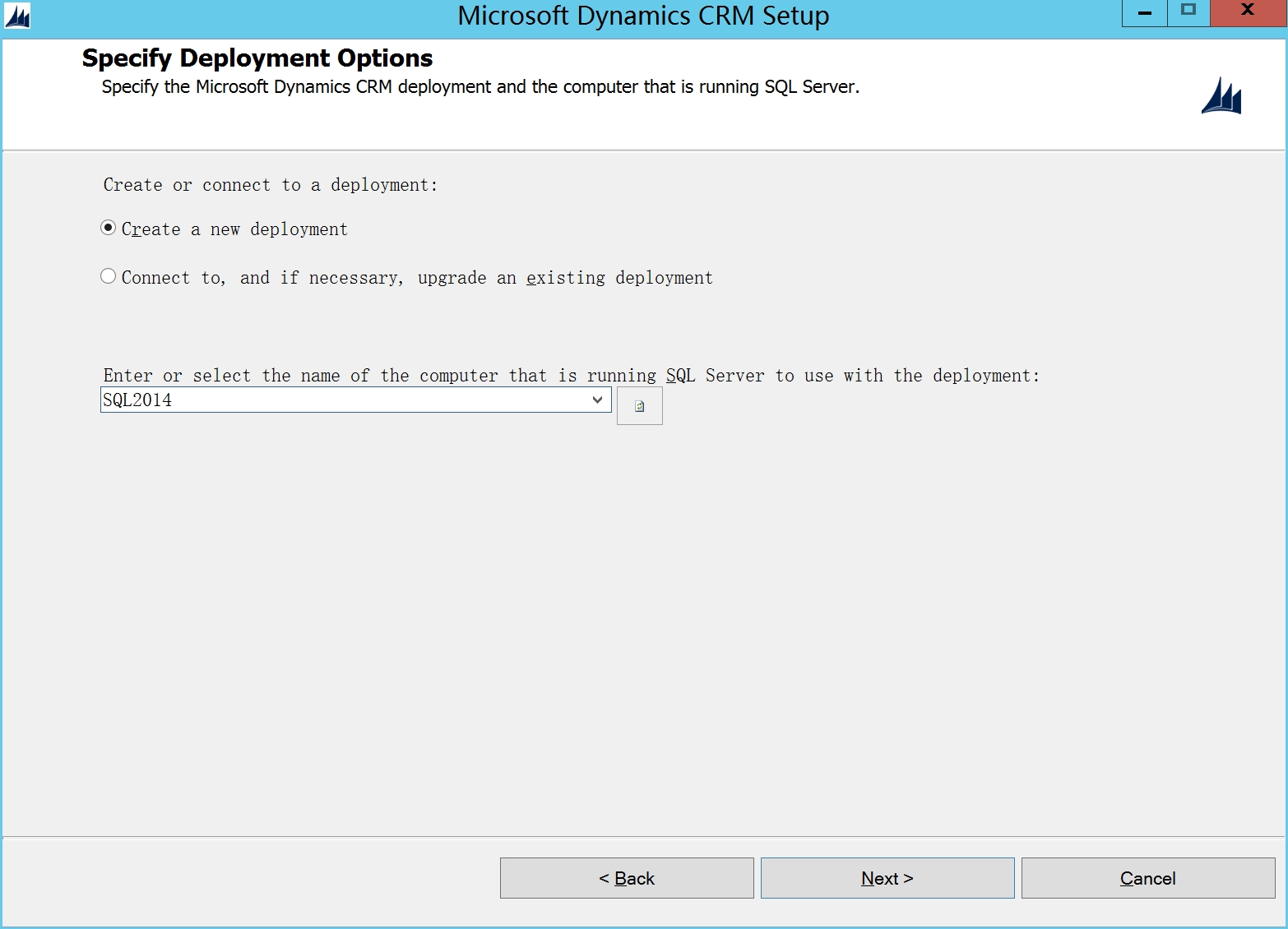
选择browse,选中第一步安装AD后创建的AD OU
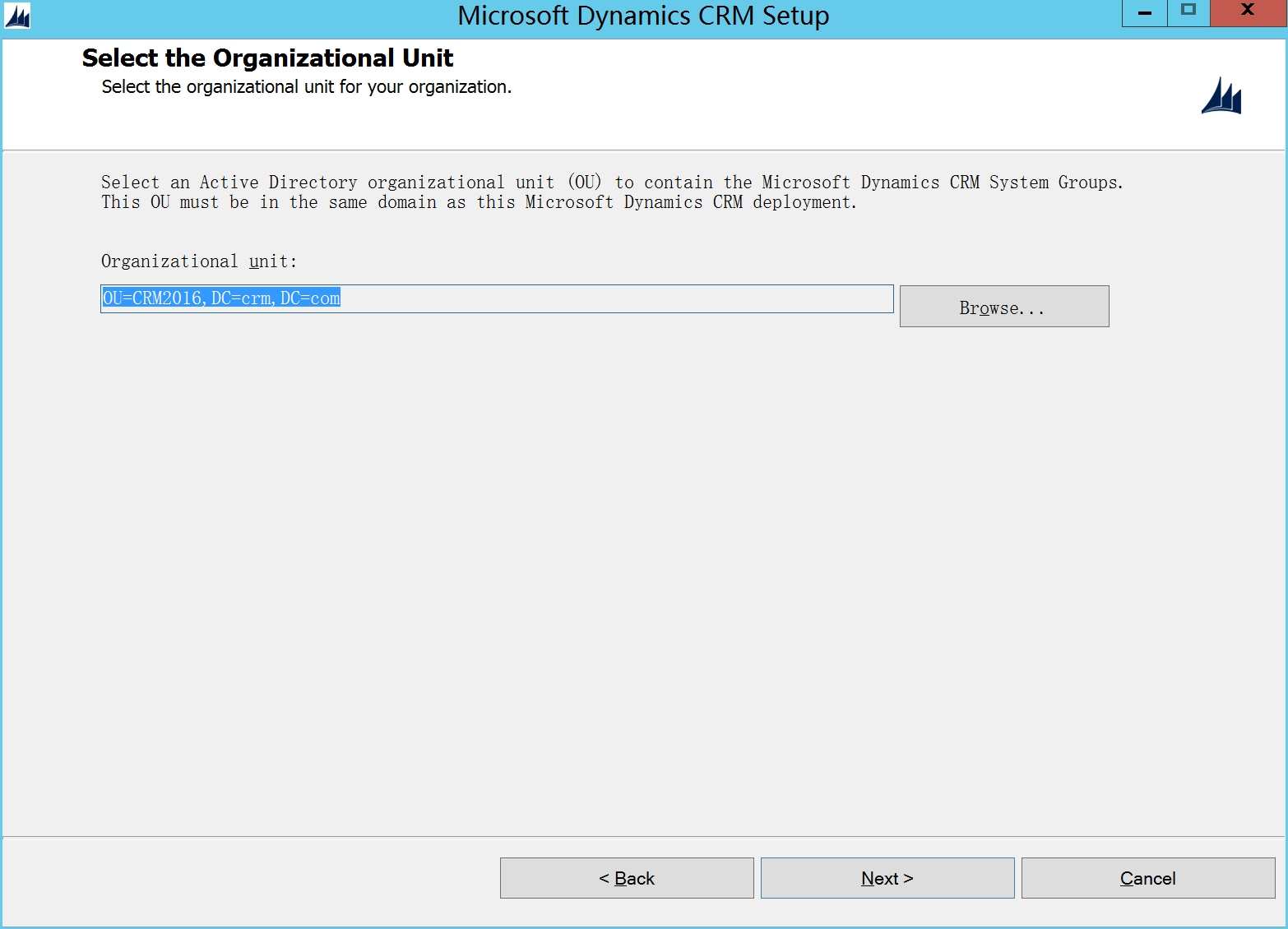
Account Name为:域名 + AD的OU中创建的用户名,Password是OU中的用户名的密码

默认下一步

不填,默认下一步
Display name一般为: CompanyName简称 + Productname
默认下一步
选第二项I dont want to user Microsoft update
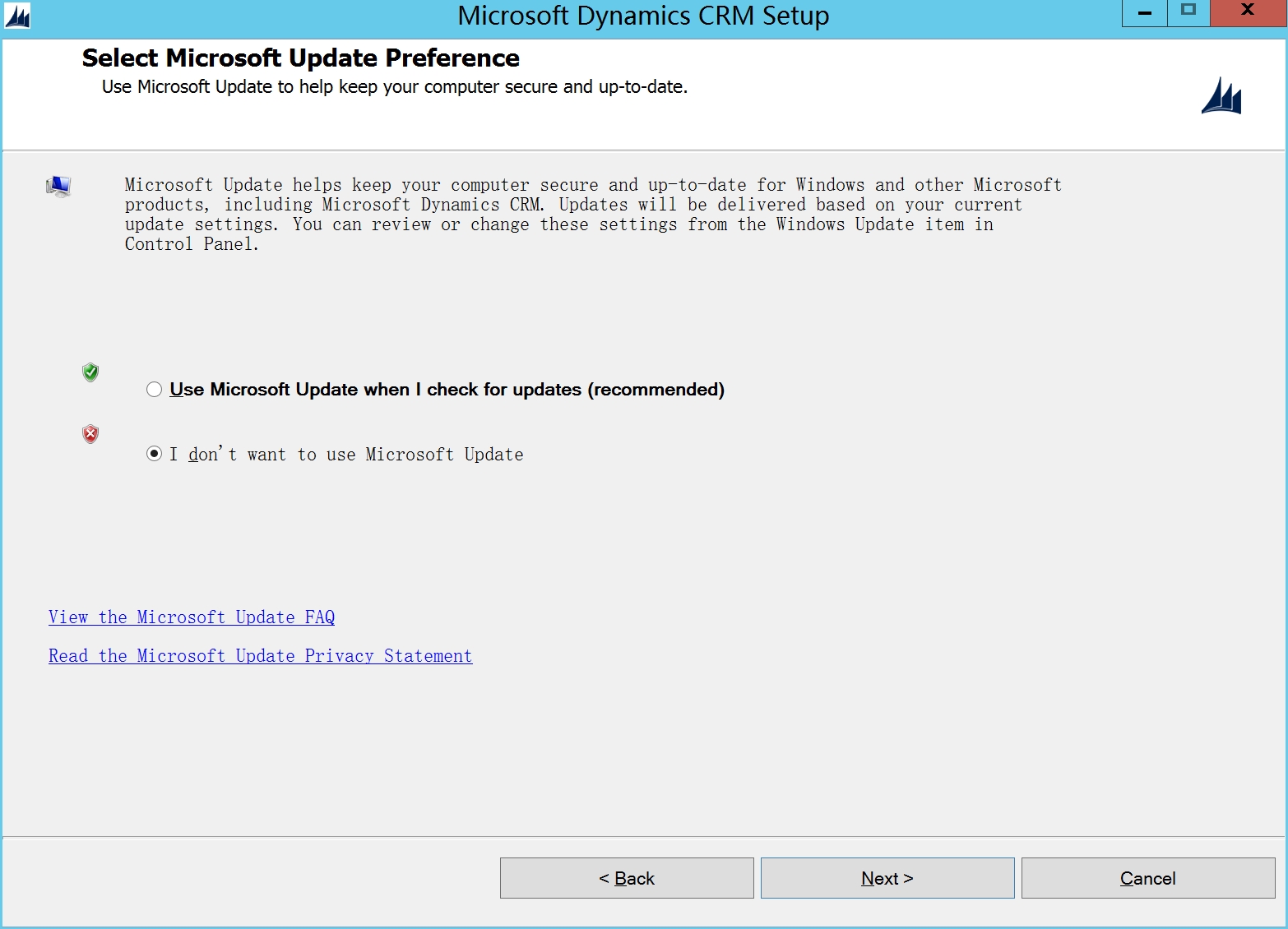
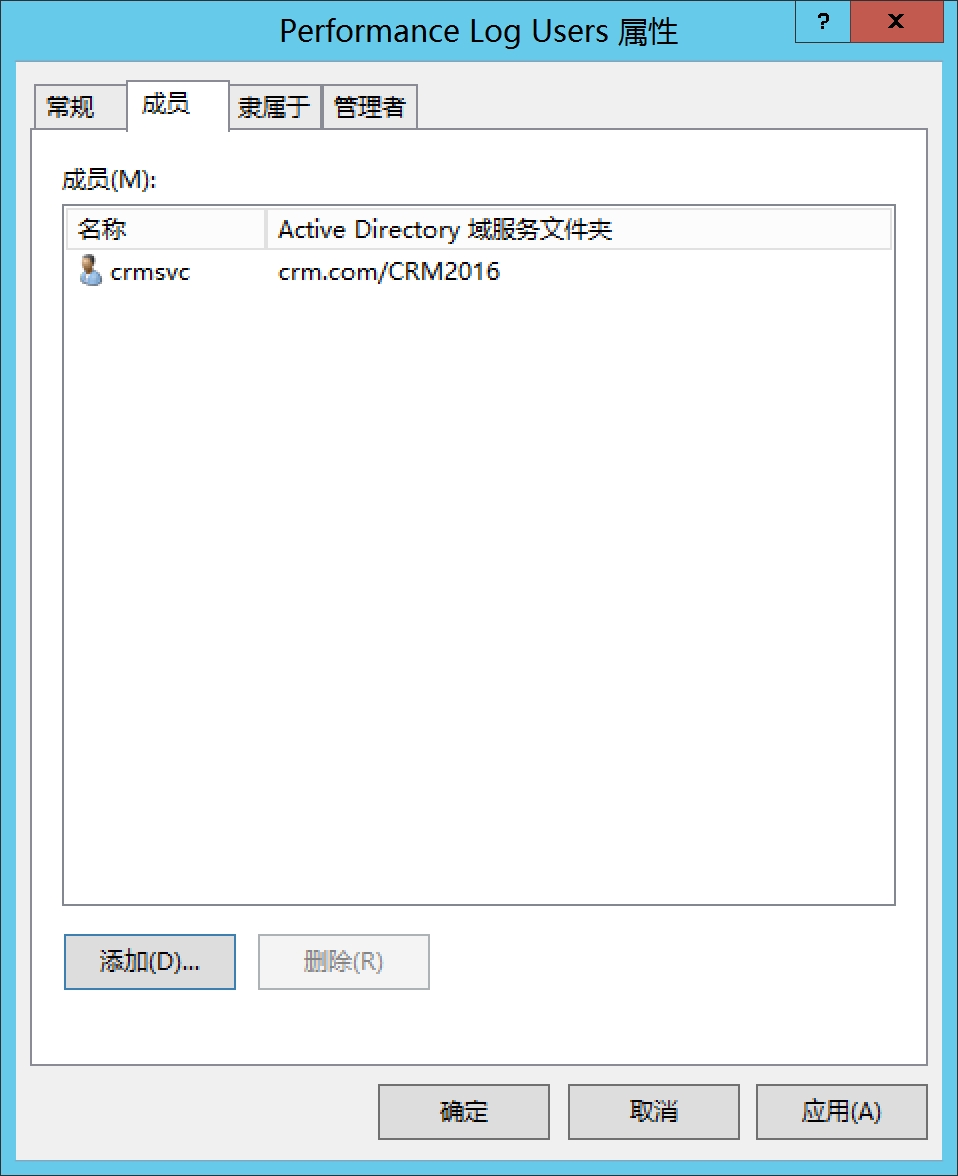
检测过程中会有一些错误,如果是Performance 原因,需要把crmsvc账号加到performance log里面去
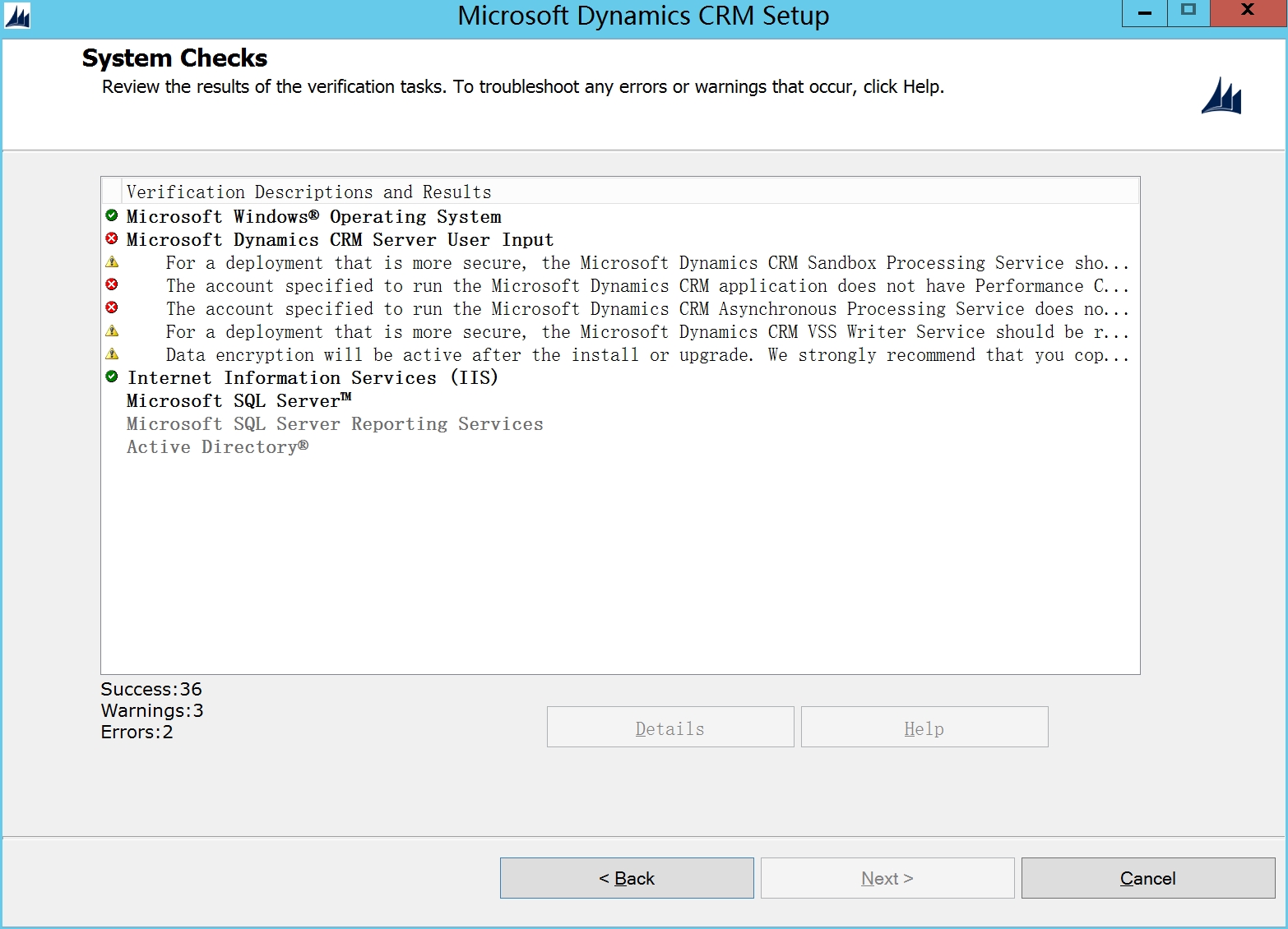
打开AD 用户和计算机,选中Builtin,找到Performance log users
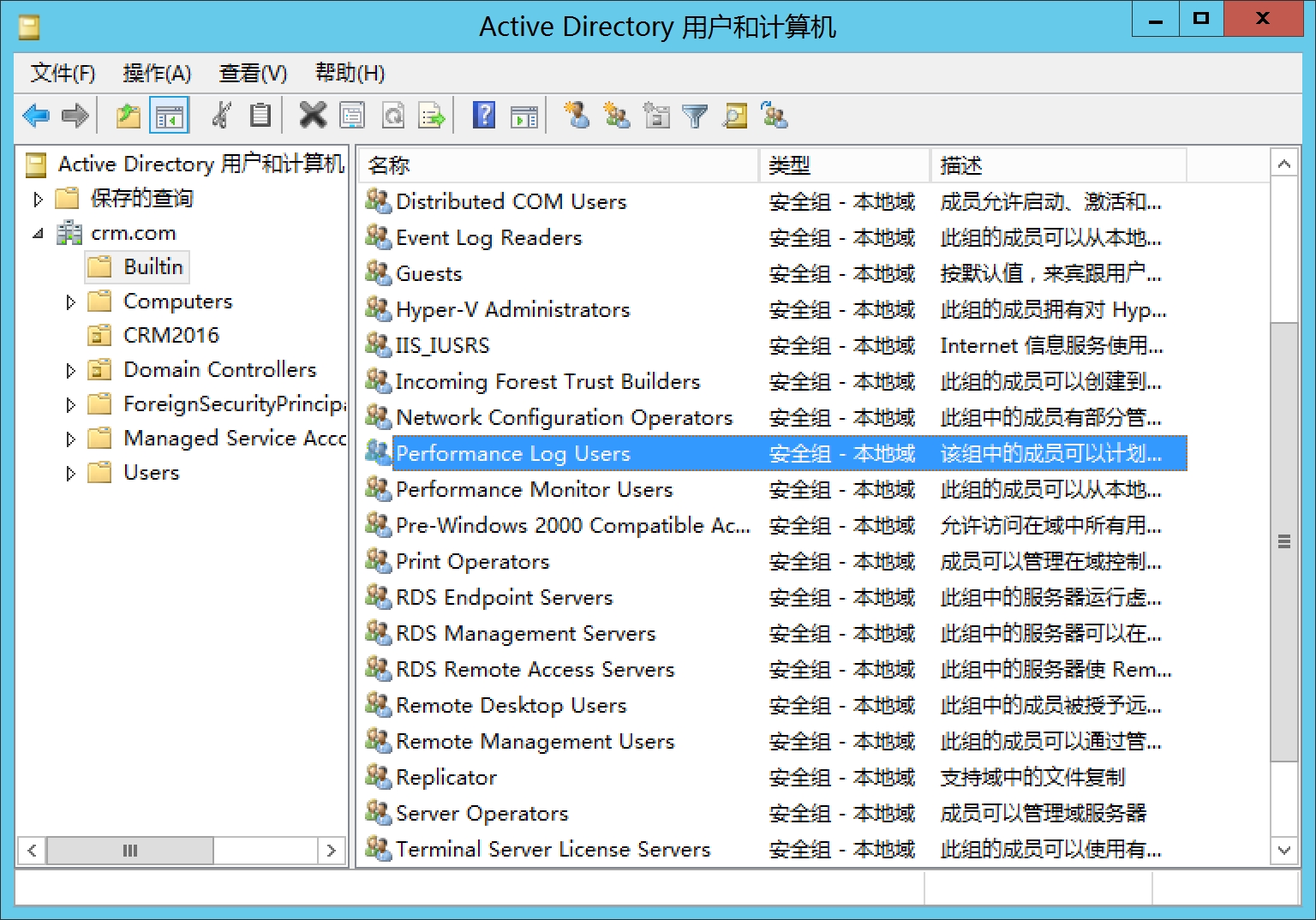
输入crmsvc,点击检查名称,点击确定
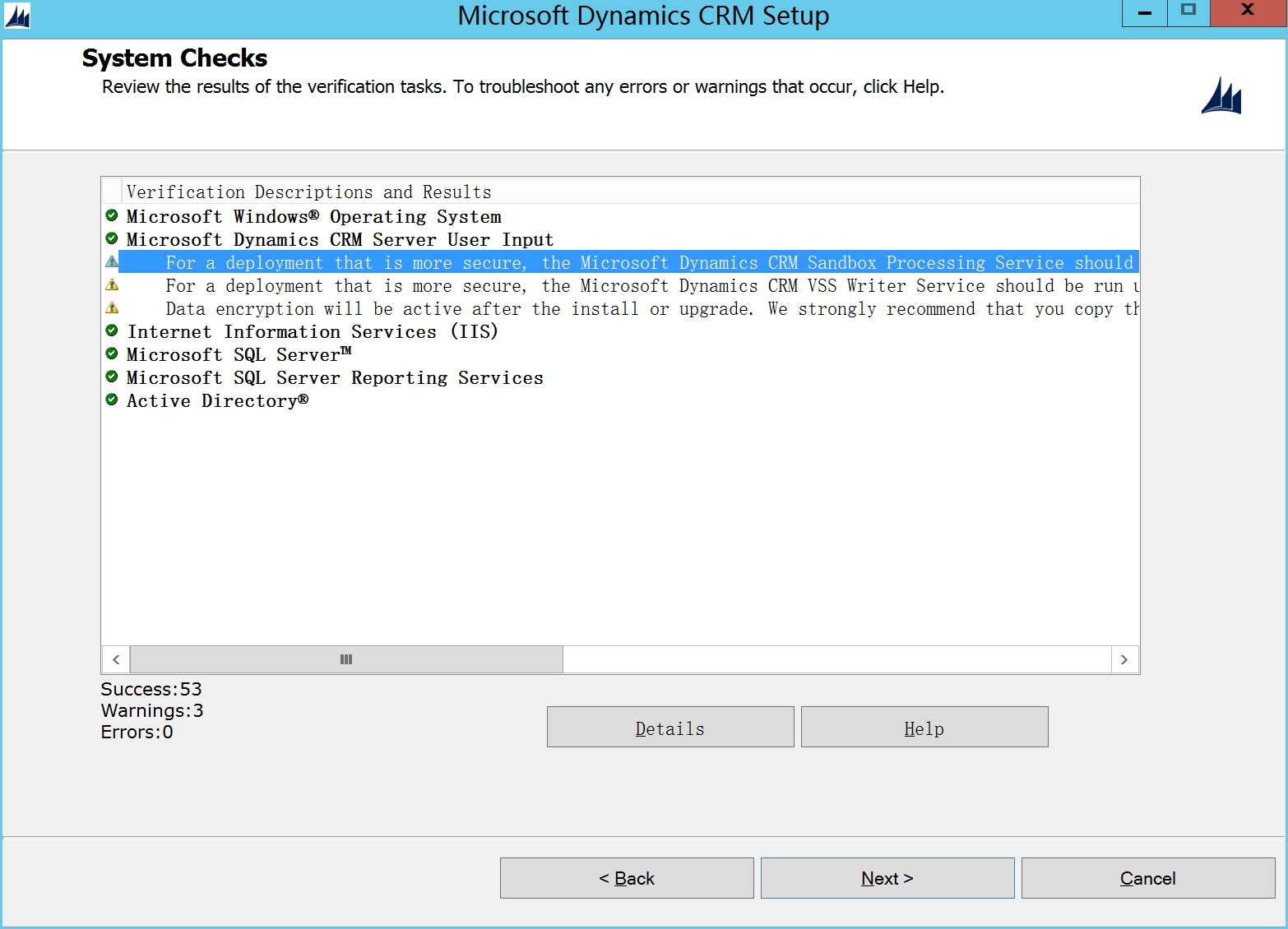
退回上一步,重新检测一下
下一步
点击Install
安装到CRM Tools时会很慢,尤其内存小于2G的时候,如果是在虚拟机上安装,内存一定要大于2G。耐心等待漫长的安装时间后,安装完成。
(安装过程中不要强行关闭安装程序,会导致OU配置失败,退出重新修复也无效。)

安装完成后:
安装完自动安装CRM Reporting Extensions Setup,如果没有自动运行,到CRM安装包下,打开SrsDataConnector文件夹,运行SetupSrsDataConnector.exe,选择Do not get updates
勾选I accpet this license agreement
默认下一步
默认下一步
勾选I dont want to user Microsoft update
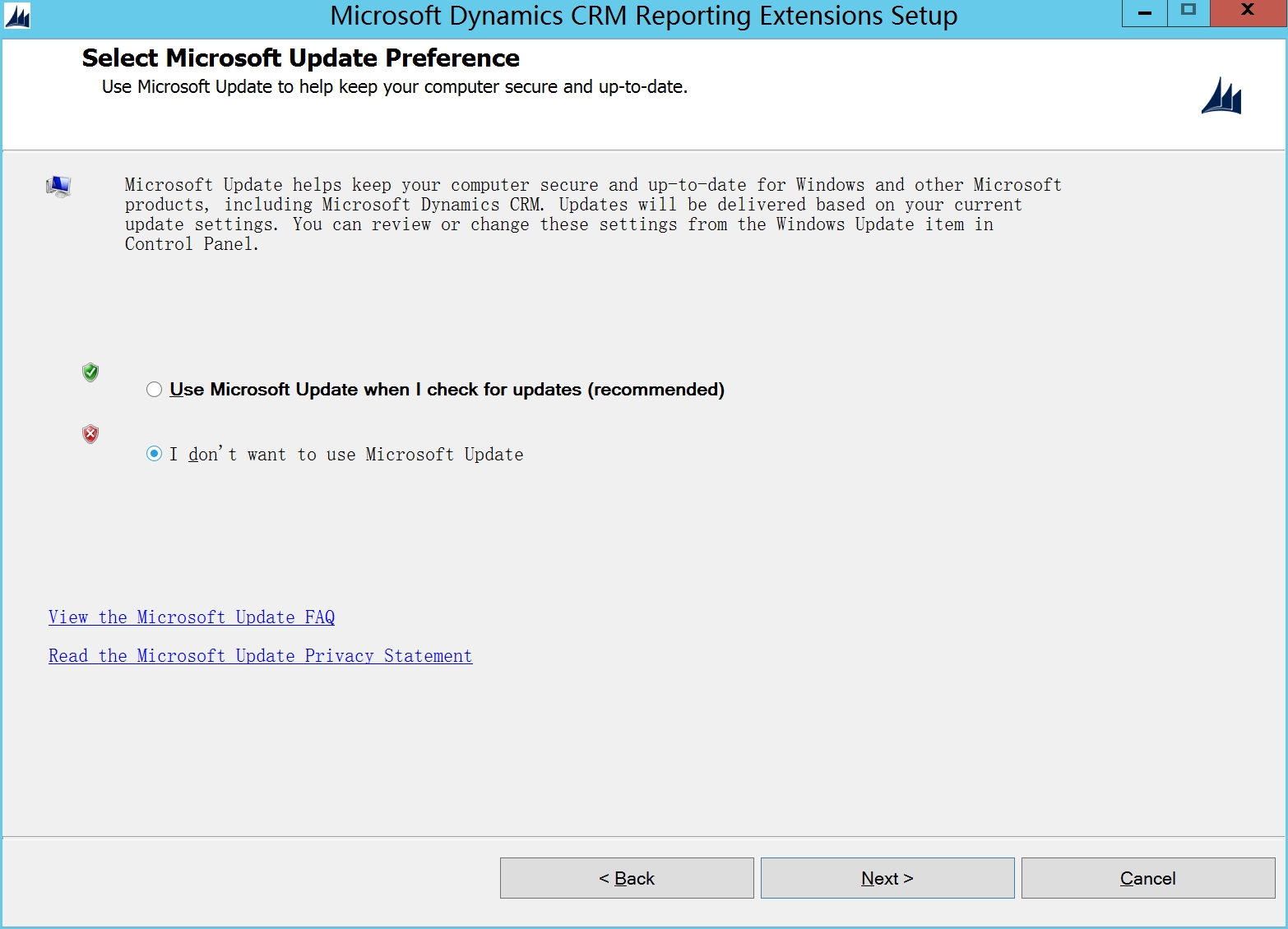
默认下一步
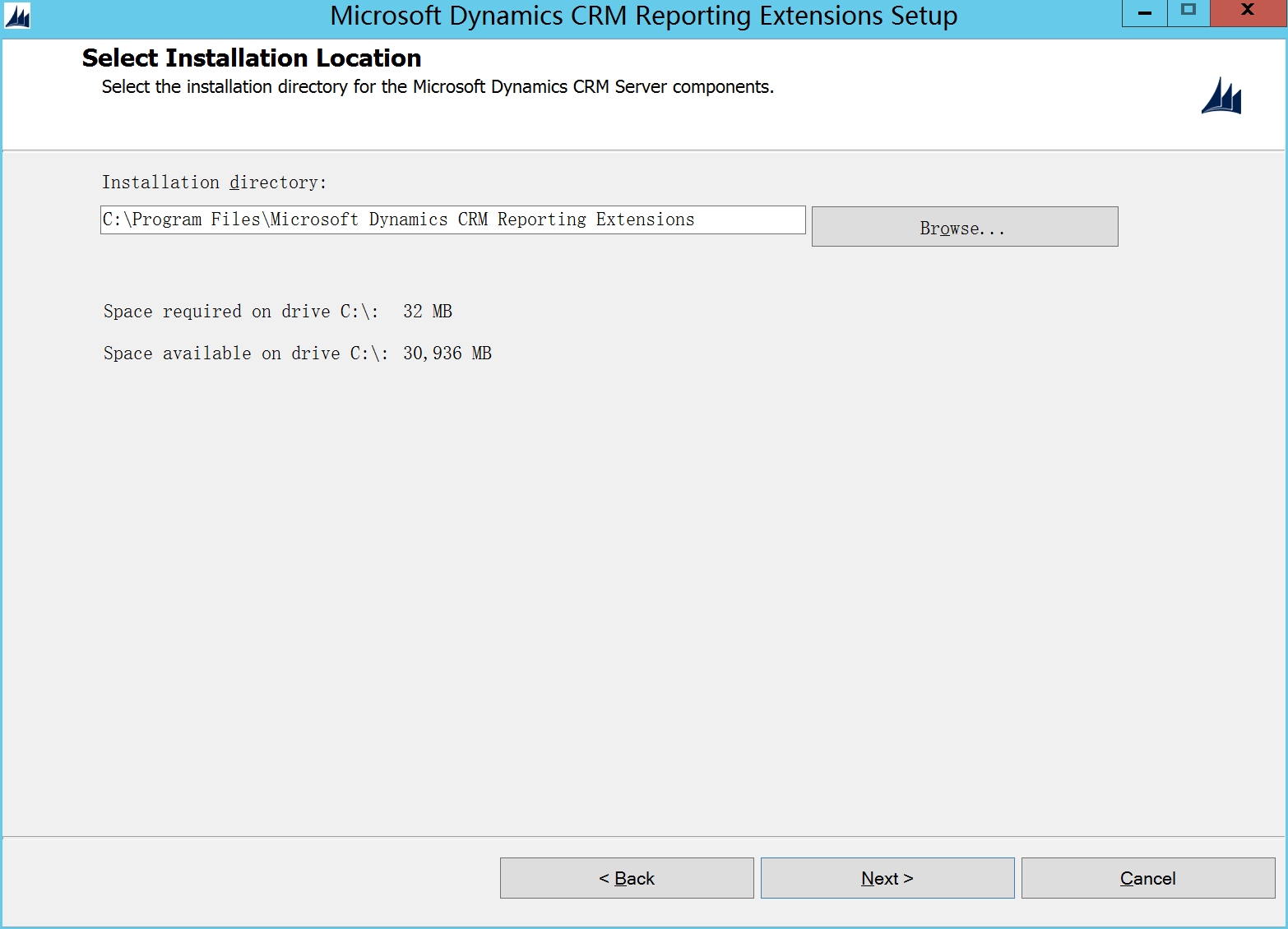
在系统环境检测时可能会遇到The SQL Server Reporting Services account is a local user and is not supported的错误提示,
需要打开SQL Server 2014 Reporting services Configuration manager
默认账号登陆
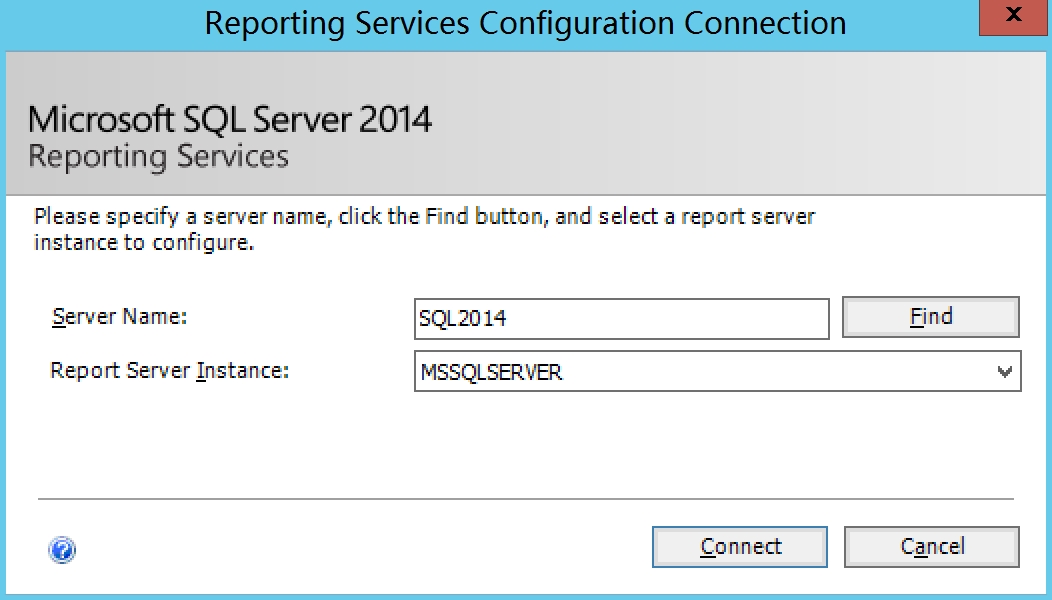
在Service Account中,选择Local System
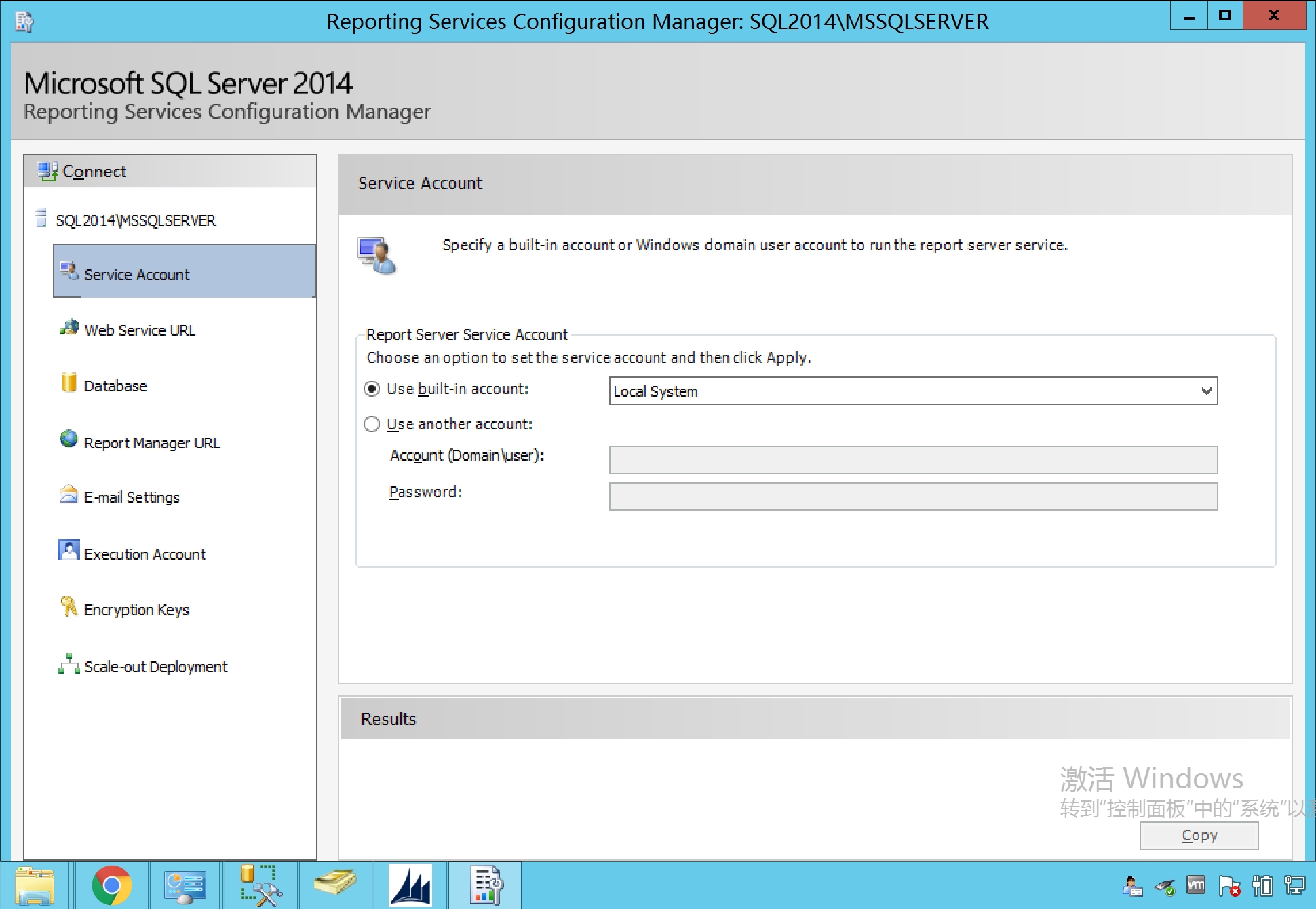
选择文件存放位置,输入密码,密码自定义
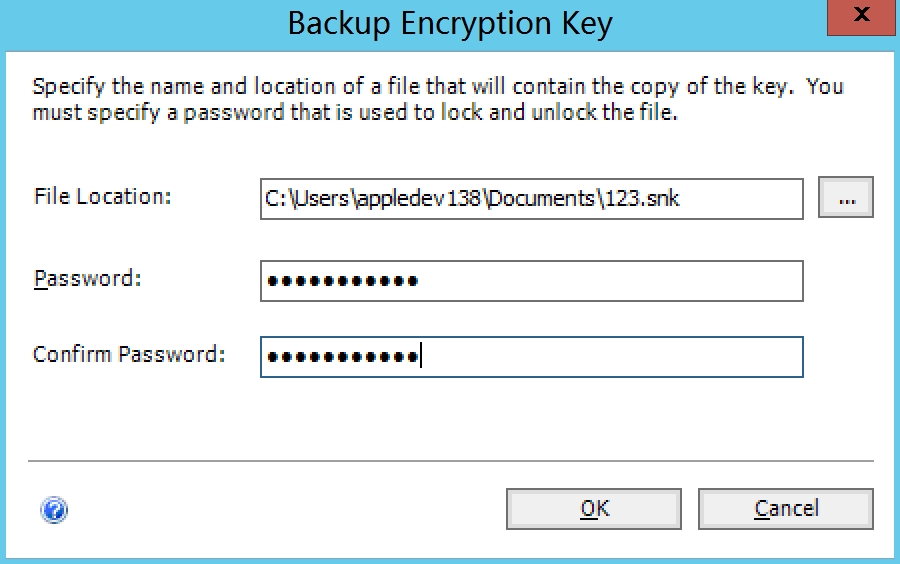
默认OK

完成后状态
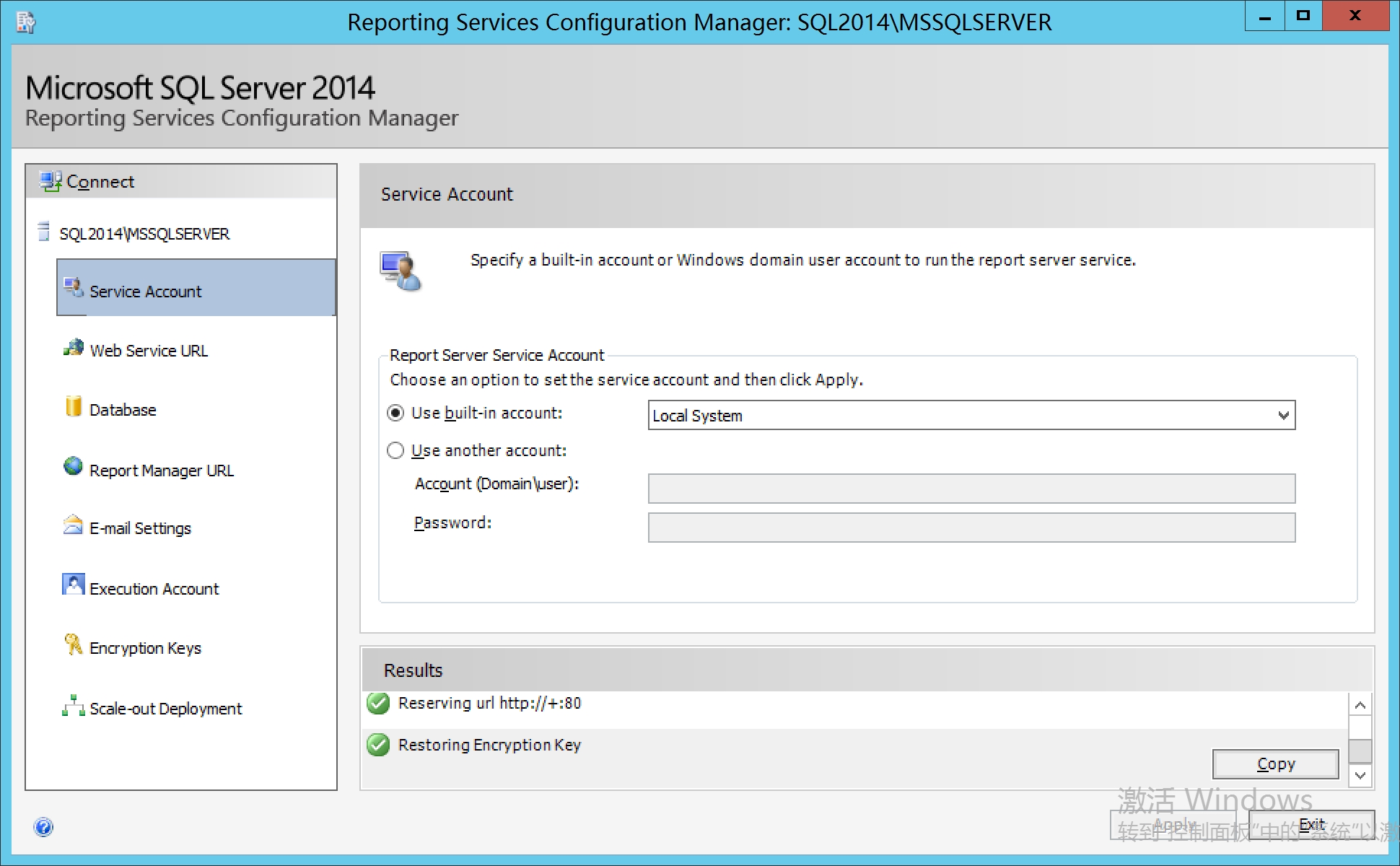
重新运行SetupSrsDataConnector.exe,检测通过

默认下一步
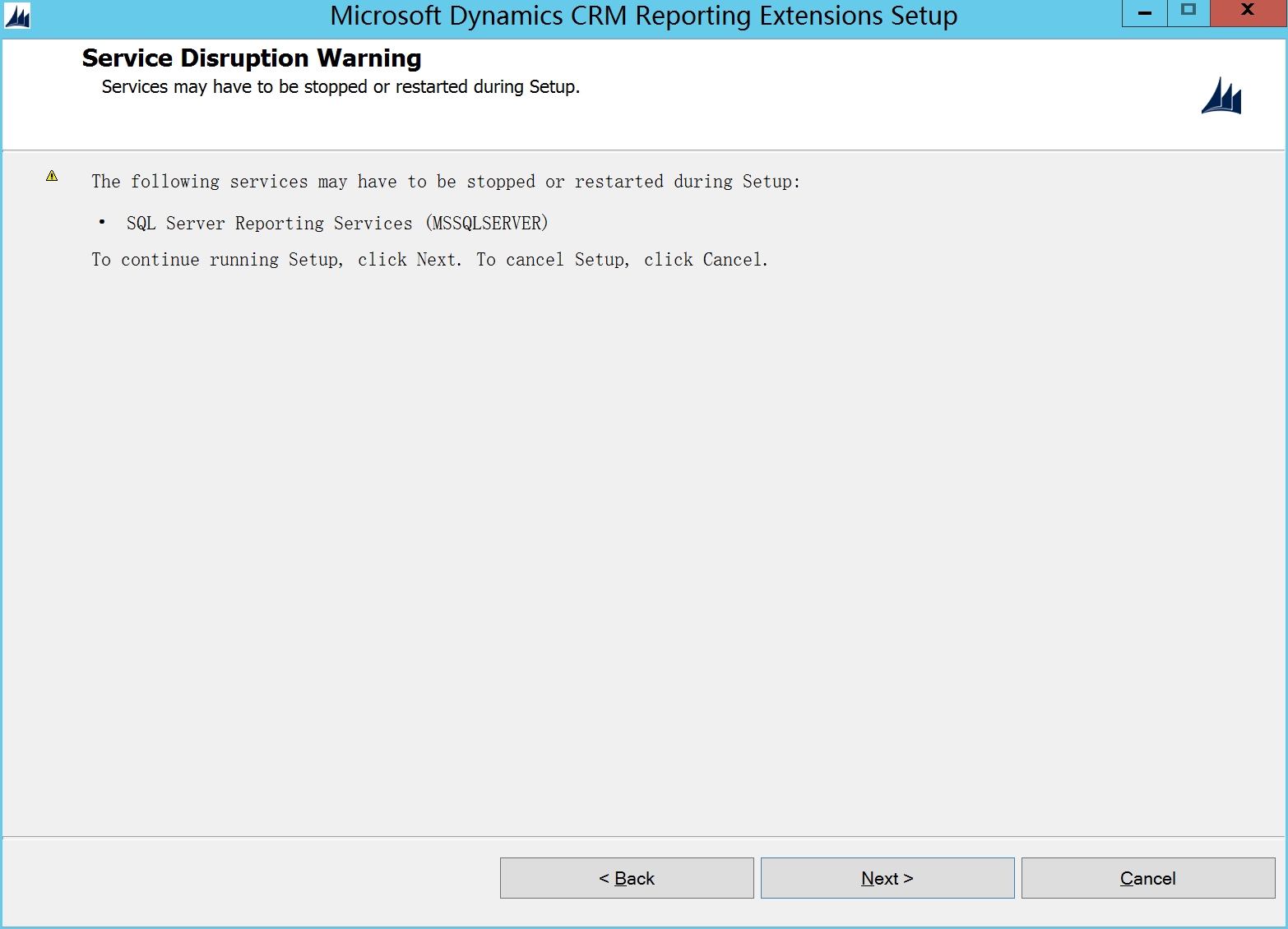
点击Install
安装完成
打开Deployment Manager
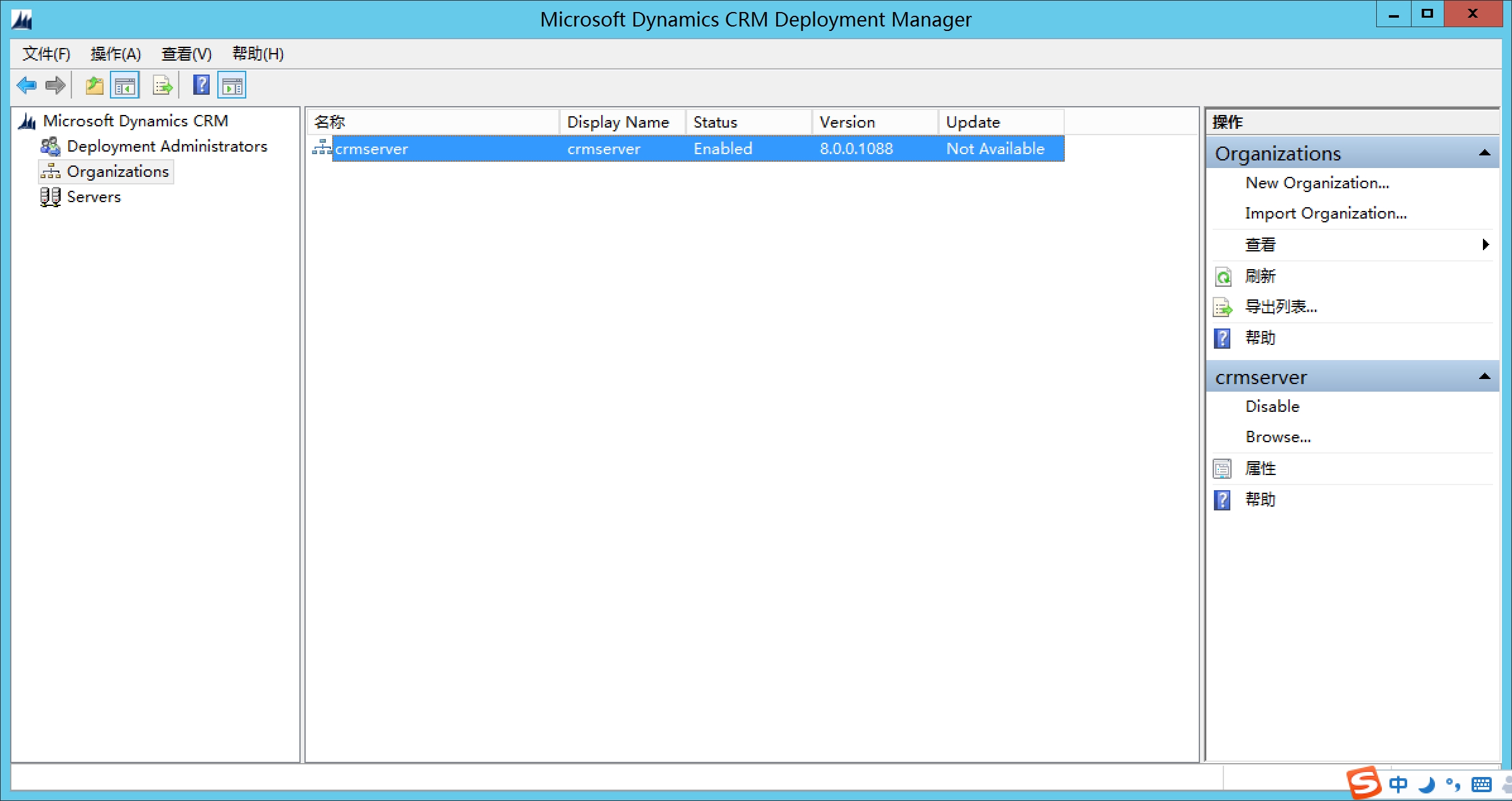
选中Organizations,右键crmserver,选择browse,在弹出的浏览器中输入用户名密码,用户名和密码为域登陆的用户名和密码,进入CRM成功。全部CRM安装配置完成。