一、内网穿透简述
由于国内网络环境问题, 普遍家庭用户宽带都没有分配到公网 IP(我有固定公网 IP, 嘿嘿); 这时候一般我们需要从外部访问家庭网络时就需要通过一些魔法手段, 比如 VPN、远程软件(向日葵…)等; 但是这些工具都有一个普遍存在的问题: 慢+卡!
1.1、传统星型拓扑
究其根本因素在于, 在传统架构中如果两个位于多层 NAT(简单理解为多个路由器)之后的设备, 只能通过一些中央(VPN/远程软件)中转服务器进行链接, 这时网络连接速度取决于中央服务器带宽和速度; 这种网络架构我这里简称为: 星型拓扑

从这张图上可以看出, 你的 “工作笔记本” 和 “家庭 NAS” 之间通讯的最大传输速度为 Up/Down: 512K/s; 因为流量经过了中央服务器中转, 由于网络木桶效应存在, 即使你两侧的网络速度再高也没用, 整体的速度取决于这个链路中最低的一个设备网速而不是你两端的设备.
在这种拓扑下, 想提高速度只有一个办法: 加钱! 在不使用 “钞能力” 的情况下, 普遍免费的软件提供商不可能给予过多的资源来让用户白嫖, 而自己弄大带宽的中央服务器成本又过高.
1.2、NAT 穿透与网状拓扑
本部分只做简述, 具体里面有大量细节和规则可能描述不准确, 细节部分推荐阅读How NAT traversal works.
既然传统的星型拓扑有这么多问题, 那么有没有其他骚操作可以解决呢? 答案是有的, 简单来说就是利用 NAT 穿透原理. NAT 穿透简单理解如下: 在 A 设备主动向 B 设备发送流量后, 整个链路上的防火墙会短时间打开一个映射规则, 该规则允许 B 设备短暂的从这个路径上反向向 A 设备发送流量. 更通俗的讲大概就是所谓的: “顺着网线来打你”

搞清了这个规则以后, 我们就可以弄一台 “低配” 的中央服务器, 让中央服务器来帮助我们协商两边的设备谁先访问谁(或者说是访问规则); 两个设备一起无脑访问对方, 然后触发防火墙的 NAT 穿透规则(防火墙打开), 此后两个设备就可以不通过中央服务器源源不断的通讯了. 在这种架构下我们的设备其实就组成了一个非标准的网状拓扑:

在这种拓扑下, 两个设备之间的通讯速度已经不在取决于中央服务器, 而是直接取决于两端设备的带宽, 也就是说达到了设备网络带宽峰值. 当然 NAT 穿透也不是百分百能够成功的, 在复杂网络情况下有些防火墙不会按照预期工作或者说有更严格的限制; 比如 IP、端口、协议限制等等, 所以为了保证可靠性可以让中央服务器中转做后备方案, 即尽量尝试 NAT 穿透, 如果不行走中央服务器中继.
二、Tailscale 简介
第一部分是为了方便读者理解一些新型内网穿透的大致基本原理, 现在回到本文重点: Tailscale
Tailscale 就是一种利用 NAT 穿透(aka: P2P 穿透)技术的 VPN 工具. Tailscale 客户端等是开源的, 不过遗憾的是中央控制服务器目前并不开源; Tailscale 目前也提供免费的额度给用户使用, 在 NAT 穿透成功的情况下也能保证满速运行.
不过一旦无法 NAT 穿透需要做中转时, Tailscale 官方的服务器由于众所周知的原因在国内访问速度很拉胯; 不过万幸的是开源社区大佬们搓了一个开源版本的中央控制服务器(Headscale), 也就是说: 我们可以自己搭建中央服务器啦, 完全 “自主可控” 啦.
三、搭建 Headscale 服务端
以下命令假设安装系统为 Ubuntu 22.04, 其他系统请自行调整.
3.1、宿主机安装
Headscale 是采用 Go 语言编写的, 所以只有一个二进制文件, 在Github Releases页面下载最新版本即可:
# 下载wget https://github.com/juanfont/headscale/releases/download/v0.16.4/headscale_0.16.4_linux_amd64 -O /usr/local/bin/headscale# 增加可执行权限chmod +x /usr/local/bin/headscale
下载完成后为了安全性我们需要创建单独的用户和目录用于 Headscale 运行
# 配置目录mkdir -p /etc/headscale# 创建用户useradd \ --create-home \ --home-dir /var/lib/headscale/ \ --system \ --user-group \ --shell /usr/sbin/nologin \ headscale
为了保证 Headscale 能持久运行, 我们需要创建 SystemD 配置文件
# /lib/systemd/system/headscale.service[Unit]Description=headscale controllerAfter=syslog.targetAfter=network.target[Service]Type=simpleUser=headscaleGroup=headscaleExecStart=/usr/local/bin/headscale serveRestart=alwaysRestartSec=5# Optional security enhancementsNoNewPrivileges=yesPrivateTmp=yesProtectSystem=strictProtectHome=yesReadWritePaths=/var/lib/headscale /var/run/headscaleAmbientCapabilities=CAP_NET_BIND_SERVICERuntimeDirectory=headscale[Install]WantedBy=multi-user.target
3.2、配置 Headscale
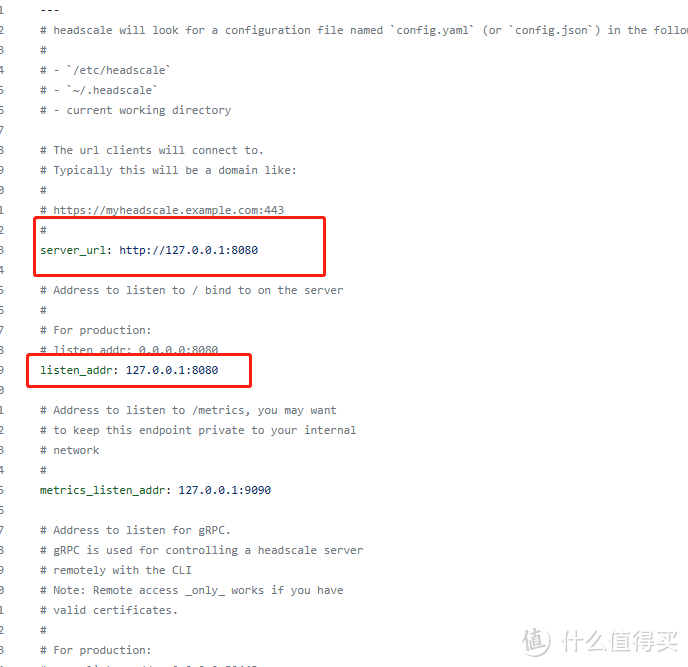
安装完成以后我们需要在 /etc/headscale/config.yaml 中配置 Headscale 的启动配置, 以下为配置样例以及解释(仅列出重要配置):
---# Headscale 服务器的访问地址# # 这个地址是告诉客户端需要访问的地址, 即使你需要在跑在# 负载均衡器之后这个地址也必须写成负载均衡器的访问地址server_url: https://your.domain.com# Headscale 实际监听的地址listen_addr: 0.0.0.0:8080# 监控地址metrics_listen_addr: 127.0.0.1:9090# grpc 监听地址grpc_listen_addr: 0.0.0.0:50443# 是否允许不安全的 grpc 连接(非 TLS)grpc_allow_insecure: false# 客户端分配的内网网段ip_prefixes: - fd7a:115c:a1e0::/48 - 100.64.0.0/10# 中继服务器相关配置derp: server: # 关闭内嵌的 derper 中继服务(可能不安全, 还没去看代码) enabled: false # 下发给客户端的中继服务器列表(默认走官方的中继节点) urls: - https://controlplane.tailscale.com/derpmap/default # 可以在本地通过 yaml 配置定义自己的中继接待你 paths: []# SQLite configdb_type: sqlite3db_path: /var/lib/headscale/db.sqlite# 使用自动签发证书是的域名tls_letsencrypt_hostname: ""# 使用自定义证书时的证书路径tls_cert_path: ""tls_key_path: ""# 是否让客户端使用随机端口, 默认使用 41641/UDPrandomize_client_port: false
3.3、证书及反向代理
可能很多人和我一样, 希望使用 ACME 自动证书, 又不想占用 80/443 端口, 又想通过负载均衡器负载, 配置又看的一头雾水; 所以这里详细说明一下 Headscale 证书相关配置和工作逻辑:
1、Headscale 的 ACME 只支持 HTTP/TLS 挑战, 所以使用后必定占用 80/443
2、当配置了 tls_letsencrypt_hostname 时一定会进行 ACME 申请
3、在不配置 tls_letsencrypt_hostname 时如果配置了 tls_cert_path 则使用自定义证书
4、两者都不配置则不使用任何证书, 服务端监听 HTTP 请求
5、三种情况下(ACME 证书、自定义证书、无证书)主服务都只监听 listen_addr 地址, 与 server_url 没半毛钱关系
6、只有在有证书(ACME 证书或自定义证书)的情况下或者手动开启了 grpc_allow_insecure 才会监听 grpc 远程调用服务
综上所述, 如果你想通过 Nginx、Caddy 反向代理 Headscale, 则你需要满足以下配置:
1、删除掉 tls_letsencrypt_hostname 或留空, 防止 ACME 启动
2、删除掉 tls_cert_path 或留空, 防止加载自定义证书
3、server_url 填写 Nginx 或 Caddy 被访问的 HTTPS 地址
4、在你的 Nginx 或 Caddy 中反向代理填写 listen_addr 的 HTTP 地址
Nginx 配置参考官方 Wiki, Caddy 只需要一行reverse_proxy headscale:8080即可(地址自行替换).
至于 ACME 证书你可以通过使用 acme.sh 自动配置 Nginx 或者使用 Caddy 自动申请等方式, 这些已经与 Headscale 无关了, 不在本文探讨范围内.
3.4、内网地址分配
请尽量不要将 ip_prefixes 配置为默认的 100.64.0.0/10 网段, 如果你有兴趣查询了该地址段, 那么你应该明白它叫 CGNAT; 很不幸的是例如 Aliyun 底层的 apt 源等都在这个范围内, 可能会有一些奇怪问题.
3.5、启动 Headscale
在处理完证书等配置后, 只需要愉快的启动一下即可:
# 开机自启动 并 立即启动systemctl enable headscale --now
再啰嗦一嘴, 如果你期望使用 Headscale ACME 自动申请证书, 你的关键配置应该像这样:
server_url: https://your.domain.comlisten_addr: 0.0.0.0:443tls_letsencrypt_hostname: "your.domain.com"tls_cert_path: ""tls_key_path: ""
如果你期望使用自定义证书, 则你的关键配置应该像这样:
server_url: https://your.domain.comlisten_addr: 0.0.0.0:443tls_letsencrypt_hostname: ""tls_cert_path: "/path/to/cert"tls_key_path: "/path/to/key"
如果你期望使用负载均衡器, 那么你的关键配置应该像这样:
server_url: https://your.domain.comlisten_addr: 0.0.0.0:8080tls_letsencrypt_hostname: ""tls_cert_path: ""tls_key_path: ""
在使用负载均衡器配置时, 启动后会有一行警告日志, 忽略即可:
2022-09-18T07:57:36Z WRN Listening without TLS but ServerURL does not start with http://
3.6、Docker Compose 安装
Compose 配置样例文件如下:
# docker-compose.yamlversion: "3.9"services: headscale: container_name: headscale image: headscale/headscale:0.16.4 ports: - "8080:8080" cap_add: - NET_ADMIN - NET_RAW - SYS_MODULE sysctls: - net.ipv4.ip_forward=1 - net.ipv6.conf.all.forwarding=1 restart: always volumes: - ./conf:/etc/headscale - data:/var/lib/headscale command: ["headscale", "serve"]volumes: config: data:
你需要在与 docker-compose.yaml 同级目录下创建 conf 目录用于存储配置文件; 具体配置请参考上面的配置详解等部分, 最后不要忘记你的 Compose 文件端口映射需要和配置文件保持一致.
四、客户端安装
对于客户端来说, Tailscale 提供了多个平台和发行版的预编译安装包, 并且部分客户端直接支持设置自定义的中央控制服务器.
4.1、Linux 客户端
Linux 用户目前只需要使用以下命令安装即可:
curl -fsSL https://tailscale.com/install.sh | sh
默认该脚本会检测相关的 Linux 系统发行版并使用对应的包管理器安装 Tailscale, 安装完成后使用以下命令启动:
tailscale up --login-server https://your.domain.com --advertise-routes=192.168.11.0/24 --accept-routes=true --accept-dns=false
关于选项设置:
--login-server: 指定使用的中央服务器地址(必填)
--advertise-routes: 向中央服务器报告当前客户端处于哪个内网网段下, 便于中央服务器让同内网设备直接内网直连(可选的)或者将其他设备指定流量路由到当前内网(可选)
--accept-routes: 是否接受中央服务器下发的用于路由到其他客户端内网的路由规则(可选)
--accept-dns: 是否使用中央服务器下发的 DNS 相关配置(可选, 推荐关闭)
启动完成后, tailscale 将会卡住, 并打印一个你的服务器访问地址; 浏览器访问该地址后将会得到一条命令:


注意: 浏览器上显示的命令需要在中央控制服务器执行(Headscale), NAMESAPCE 位置应该替换为一个具体的 Namespace, 可以使用以下命令创建 Namespace (名字随意)并让设备加入:
 x9tA4A
x9tA4A
在 Headscale 服务器上执行命令成功后客户端命令行在稍等片刻便会执行完成, 此时该客户端已经被加入 Headscale 网络并分配了特定的内网 IP; 多个客户端加入后在 NAT 穿透成功时就可以互相 ping 通, 如果出现问题请阅读后面的调试细节, 只要能注册成功就算是成功了一半, 暂时不要慌.
4.2、MacOS 客户端
MacOS 客户端安装目前有两种方式, 一种是使用标准的 AppStore 版本(好像还有一个可以直接下载的), 需要先设置服务器地址然后再启动 App:
首先访问你的 Headscale 地址 https://your.domain.com/apple:

复制倒数第二行命令到命令行执行(可能需要 sudo 执行), 然后去 AppStore 搜索 Hailscale 安装并启动; 启动后会自动打开浏览器页面, 与 Linux 安装类似, 复制命令到 Headscale 服务器执行即可(Namespace 创建一次就行).
第二种方式也是比较推荐的方式, 直接编译客户端源码安装, 体验与 Linux 版本一致:
# 安装 gobrew install go# 编译命令行客户端go install tailscale.com/cmd/tailscale{,d}@main# 安装为系统服务sudo tailscaled install-system-daemon安装完成后同样通过 tailscale up 命令启动并注册即可, 具体请参考 Linux 客户端安装部分.
4.3、其他客户端
关于 Windows 客户端大致流程就是创建一个注册表, 然后同样安装官方 App 启动, 接着浏览器复制命令注册即可. 至于移动端本人没有需求, 所以暂未研究. Windows 具体的安装流程请访问 https://your.domain.com/windows 地址查看(基本与 MacOS AppStore 版本安装类似).
五、中继服务器搭建
在上面的 Headscale 搭建完成并添加客户端后, 某些客户端可能无法联通; 这是由于网络复杂情况下导致了 NAT 穿透失败; 为此我们可以搭建一个中继服务器来进行传统的星型拓扑通信.
5.1、搭建 DERP Server
首先需要注意的是, 在需要搭建 DERP Server 的服务器上, 请先安装一个 Tailscale 客户端并注册到 Headscale; 这样做的目的是让搭建的 DERP Server 开启客户端认证, 否则你的 DERP Server 可以被任何人白嫖.
目前 Tailscale 官方并未提供 DERP Server 的安装包, 所以需要我们自行编译安装; 在编译之前请确保安装了最新版本的 Go 语言及其编译环境.
# 编译 DERP Servergo install tailscale.com/cmd/derper@main# 复制到系统可执行目录mv ${GOPATH}/bin/derper /usr/local/bin# 创建用户和运行目录useradd \ --create-home \ --home-dir /var/lib/derper/ \ --system \ --user-group \ --shell /usr/sbin/nologin \ derper接下来创建一个 SystemD 配置:
# /lib/systemd/system/derper.service[Unit]Description=tailscale derper serverAfter=syslog.targetAfter=network.target[Service]Type=simpleUser=derperGroup=derperExecStart=/usr/local/bin/derper -c=/var/lib/derper/private.key -a=:8989 -stun-port=3456 -verify-clientsRestart=alwaysRestartSec=5# Optional security enhancementsNoNewPrivileges=yesPrivateTmp=yesProtectSystem=strictProtectHome=yesReadWritePaths=/var/lib/derper /var/run/derperAmbientCapabilities=CAP_NET_BIND_SERVICERuntimeDirectory=derper[Install]WantedBy=multi-user.target
最后使用以下命令启动 Derper Server 即可:
systemctl enable derper --now
注意: 默认情况下 Derper Server 会监听在 :443 上, 同时会触发自动 ACME 申请证书. 关于证书逻辑如下:
1、如果不指定 -a 参数, 则默认监听 :443
2、如果监听 :443 并且未指定 --certmode=manual 则会强制使用 --hostname 指定的域名进行 ACME 申请证书
3、如果指定了 --certmode=manual 则会使用 --certmode 指定目录下的证书开启 HTTPS
4、如果指定了 -a 为非 :443 端口, 且没有指定 --certmode=manual 则只监听 HTTP
如果期望使用 ACME 自动申请只需要不增加 -a 选项即可(占用 443 端口), 如果期望通过负载均衡器负载, 则需要将 -a 选项指定到非 443 端口, 然后配置 Nginx、Caddy 等 LB 软件即可. 最后一点 stun 监听的是 UDP 端口, 请确保防火墙打开此端口.
5.2、配置 Headscale
在创建完 Derper 中继服务器后, 我们还需要配置 Headscale 来告诉所有客户端在必要时可以使用此中继节点进行通信; 为了达到这个目的, 我们需要在 Headscale 服务器上创建以下配置:
# /etc/headscale/derper.yamlregions: 901: regionid: 901 regioncode: private-derper regionname: "My Private Derper Server" nodes: - name: private-derper regionid: 901 # 自行更改为自己的域名 hostname: derper.xxxxx.com # Derper 节点的 IP ipv4: 123.123.123.123 # Derper 设置的 STUN 端口 stunport: 3456
在创建好基本的 Derper Server 节点信息配置后, 我们需要调整主配置来让 Headscale 加载:
derp: server: # 这里关闭 Headscale 默认的 Derper Server enabled: false # urls 留空, 保证不加载官方的默认 Derper urls: [] # 这里填写 Derper 节点信息配置的绝对路径 paths: - /etc/headscale/derper.yaml # If enabled, a worker will be set up to periodically # refresh the given sources and update the derpmap # will be set up. auto_update_enabled: true # How often should we check for DERP updates? update_frequency: 24h
接下来重启 Headscale 并重启 client 上的 tailscale 即可看到中继节点:
~ tailscale netcheckReport: * UDP: true * IPv4: yes, 124.111.111.111:58630 * IPv6: no, but OS has support * MappingVariesByDestIP: false * HairPinning: false * PortMapping: UPnP, NAT-PMP, PCP * CaptivePortal: true * Nearest DERP: XXXX Derper Server * DERP latency: - XXXX: 10.1ms (XXXX Derper Server)
到此中继节点搭建完成.
5.3、Docker Compose 安装
目前官方似乎也没有提供 Docker 镜像, 我自己通过 GitHub Action 编译了一个 Docker 镜像, 以下是使用此镜像的 Compose 文件样例:
version: '3.9'services: derper: image: mritd/derper container_name: derper restart: always ports: - "8080:8080/tcp" - "3456:3456/udp" environment: TZ: Asia/Shanghai volumes: - /etc/timezone:/etc/timezone - /var/run/tailscale:/var/run/tailscale - data:/var/lib/derpervolumes: data:
该镜像默认开启了客户端验证, 所以请确保/var/run/tailscale内存在已加入 Headscale 成功的 tailscaled 实例的 sock 文件. 其他具体环境变量等参数配置请参考Earthfile.
六、客户端网络调试
在调试中继节点或者不确定网络情况时, 可以使用一些 Tailscale 内置的命令来调试网络.
6.1、Ping 命令
tailscale ping 命令可以用于测试 IP 连通性, 同时可以看到时如何连接目标节点的. 默认情况下 Ping 命令首先会使用 Derper 中继节点通信, 然后尝试 P2P 连接; 一旦 P2P 连接成功则自动停止 Ping:
~ tailscale ping 10.24.0.5pong from k8s13 (10.24.0.5) via DERP(XXXXX) in 14mspong from k8s13 (10.24.0.5) via DERP(XXXXX) in 13mspong from k8s13 (10.24.0.5) via DERP(XXXXX) in 14mspong from k8s13 (10.24.0.5) via DERP(XXXXX) in 12mspong from k8s13 (10.24.0.5) via DERP(XXXXX) in 12mspong from k8s13 (10.24.0.5) via 3.4.170.23:2495 in 9ms
由于其先走 Derper 的特性也可以用来测试 Derper 连通性.
6.2、Status 命令
通过 tailscale status 命令可以查看当前节点与其他对等节点的连接方式, 通过此命令可以查看到当前节点可连接的节点以及是否走了 Derper 中继:
~ tailscale status10.24.0.8 xmac kovacs macOS - alivpn kovacs linux active; direct 4.3.4.5:41644, tx 1264 rx 944 aliyun kovacs linux - bob kovacs macOS offline bob-imac kovacs macOS offline company kovacs linux active; direct 114.114.114.114:41642, tx 1296 rx 880
6.3、NetCheck 命令
有些情况下我们可以确认是当前主机的网络问题导致没法走 P2P 连接, 但是我们又想了解一下当前的网络环境; 此时可以使用 tailscale netcheck 命令来检测当前的网络环境, 此命令将会打印出详细的网络环境报告:
~ tailscale netcheck2022/10/19 21:15:27 portmap: [v1] Got PMP response; IP: 123.123.123.123, epoch: 2976712022/10/19 21:15:27 portmap: [v1] Got PCP response: epoch: 2976712022/10/19 21:15:27 portmap: [v1] UPnP reply {Location:http://192.168.11.1:39735/rootDesc.xml Server:AsusWRT/386 UPnP/1.1 MiniUPnPd/2.2.0 USN:uuid:23345-2380-45f5-34534-04421abwb7cf0::urn:schemas-upnp-org:device:InternetGatewayDevice:1}, "HTTP/1.1 200 OK\r\nCACHE-CONTROL: max-age=120\r\nST: urn:schemas-upnp-org:device:InternetGatewayDevice:1\r\nUSN: uuid:34564645-2380-45f5-b069-sdfdght3245....."2022/10/19 21:15:27 portmap: UPnP meta changed: {Location:http://192.168.11.1:39735/rootDesc.xml Server:AsusWRT/386 UPnP/1.1 MiniUPnPd/2.2.0 USN:uuid:23345-2380-45f5-b069-04421abwb7cf0::urn:schemas-upnp-org:device:InternetGatewayDevice:1}Report: * UDP: true * IPv4: yes, 123.123.123.123:5935 * IPv6: no, but OS has support * MappingVariesByDestIP: false * HairPinning: true * PortMapping: UPnP, NAT-PMP, PCP * CaptivePortal: true * Nearest DERP: XXXXX Aliyun * DERP latency: - XXXXX: 9.5ms (XXXXX Aliyun) - XXXXX: 53.1ms (XXXXX BandwagonHost)七、其他补充
7.1、某些代理工具兼容性
MacOS 下使用一些增强代理工具时, 如果安装 App Store 的官方图形化客户端, 则可能与这些软件冲突, 推荐使用纯命令行版本并添加进程规则匹配 tailscale 和 tailscaled 两个进程, 让它们始终走 DIRECT 规则即可.
7.2、MacOS 下 CPU 占用突然起飞
在使用一些网络代理工具时, 网络工具会设置默认路由; 这可能导致tailscaled无法获取到默认路由接口, 然后进入死循环并把 CPU 吃满, 同时会与 Derper 服务器产生大量上传流量.截止本文发布此问题已修复, 请使用mian分支编译安装, 具体见ISSUE/5879.
7.3、阿里云安装客户端后无法更新软件
Tailscale 默认使用 CGNAT(100.64.0.0/10) 网段作为内部地址分配网段, 目前 Tailscale 仅允许自己的接口使用此网段, 不巧的是阿里云的 DNS、Apt 源等也采用此网段. 这会导致阿里云服务器安装客户端后 DNS、Apt 等不可用, 解决方案目前只能修改源码删除掉这两个 DROP 规则并重新编译.

7.4、开启路由转发
大多数时候我们可能并不会在每个服务器上都安装 Tailscale 客户端, 通常只安装 2、3 台, 然后想通过这两三台转发该内网的所有流量. 此时你需要
以上两个选项配置后, 只需要 Headscale 服务器上使用 headscale node route enable -a -i XX(ID) 开启即可. 开启后目标节点(ID)的路由就会发布到接受外部路由的所有节点, 想要关闭的话去掉 -a 即可.
7.5、其他问题
以上也只是我个人遇到的一些问题, 如果有其他问题推荐先搜索然后查看 ISSUE, 最后不行可以看看源码. 目前来说 Tailscale 很多选项很模糊, 可能需要阅读源码以后才能知道到底应该怎么做.