如何将手中 20 多台旧电脑,组建一台超级计算机?
作者:知乎用户
链接:https://www.zhihu.com/question/21116669/answer/18864330
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
请不要嘲笑别人的想法,老外已经实现了四台电脑的计算集群,题主20台也应该是可以实现的。这个资料是英文,我找到了部分中文资料,粗略地浏览了一遍,应该是可以实现的,但是细节部分没看明白,求高人翻译资料。(不好意思,我刚才发现和
的回答撞车了,不过,这些资料确实是在我没看他的资料之前自己搜索出来的,嘿嘿,大家就当他回答的补充好了)。知乎里的大神真多,呵呵,以后得好好看回答
资料地址如下 官方网址
Microwulf: A Personal, Portable Beowulf Cluster
中文翻译的资料地址如下
先上张图片震撼一下大家








以下是我找到中文翻译资料,我是直接复制的,没能把图片等复制过来,大家就凑合看吧,也可以看上面那个中文资料的网站
一、作者简介:
乔尔 亚当斯 (
)是卡尔文学院(Calvin College)计算机科学(computer science)教授,1988年获得在匹次堡大学获得博士学位,主要研究超算的内部连接,是几本计算机编程教材的作者,两次获得Fulbright Scholar
(毛里求斯1998, 冰岛 2005).
缇姆 布伦姆(
)是卡耐基大学计算机科学的研究生,2007年五月在卡尔文学院获得计算机科学学士学位。
二、说明:
此小超算拥有超过260亿次的性能,价格少于2500美元,重量少于31磅,外观规格为11" x 12" x 17"——刚好够小,足够放在桌面上或者柜子里上,
更新:2007年8月1日,这个小超算已经可以用1256美元构建成,使得其性价比达到4.8美元/亿次——这样的话,可以增加更多的芯片,以提升性能,让其更接近21世纪初的超算性能。
此小超算是由卡尔文大学的计算机系统教授乔尔 亚当斯和助教 缇姆 布伦姆设计和构建。
下面是原文的目录,可点击查看:
三、介绍
作为一个典型的超算用户,我需要到计算中心排队,而且要限定使用的计算资源。这个对于开发新的分布式软件来说,很麻烦。所以呢,我需要一个自己
的,我梦想中的小超算是可以小到放在我的桌面上,就像普通个人电脑一样。只需要普通的电源,不需要特殊的冷切装置就可以在室温下运行……
2006年末, 两个硬件发展,让我这个梦想接近了现实:
多核普及
千兆局域网相关硬件普及
结果呢,我就设想了一个小型的,4个节点,使用多核芯片,每个节点使用高速网线连接。
2006年秋天, 卡尔文学院计算机系给了我们一笔小钱——就是2500美元,去构建这么一个系统,我们当时设定的目标:
费用少于2500美元——这样一般人都能负担得起,可以促进普及。
足够小,适合放在我的桌面上,适合放到旅行箱里。
要够轻,可以手提,然后带到我的汽车里。
性能强劲,测试结果至少要200亿次:
用于个人研究,
用于我教授的高性能运算课程,
用于专业论坛讲授、高中讲演等,
只需要一根电源线,使用普通的120伏电源。
可在室温下运行。
据我们当时所知,已经有一些小型的超算,或者是性价比不错的超算出现,这些东西给了我们很好的参考:
下面是历年的性价比之王:
2005: Kronos
2003: KASY0
2002: Green Destiny
2001: The Stone Supercomputer
2000: KLAT2
2000: bunyip
1998: Avalon
在同一时间,还有其他更廉价或者是更具性价比的超算集群,不过这些记录都在2007年被改变了,最具性价比的就是下文介绍的小超算(2007年一月,9.41美元/亿次),而其记录半年后就被打破(2007年8月 4.784美元/亿次)。
架构设计:
个人小超算一般做法是使用多核芯片,集中安装到一个小的空间里,集中供电——嗯,如果能自己烧制主板,体积上应该可以做得更小——树莓派的主板体积很小,就是芯片不给力,所以需要那么多片才能达到2007年用普通电脑芯片实现的性能。
1960年代末,吉恩 庵达郝乐(Gene Amdahl)提出了一个设计准则,叫 "庵达赫乐法则"(Amdahl's Other Law),大意是:
为了兼容性考虑, 下面几个特性应该相同:
每片芯片的频率
每根内存大小
每处带宽
高性能计算一般有三个瓶颈:芯片运算速度,运算所需内存,吞吐带宽。本小超算里面,带宽主要是指网络带宽。我们预算是2500美元,在设定了每核内存量,每核的带宽之后,其中芯片运算速度当然是越快越好。
内部使用千兆网络(GigE),则意味着我们的带宽只有1Gbps,如果要更快的,可以使用比如Myrinet,不过那会超预算了,此处核心1吉赫兹+每核1吉B内存+1吉bps,嗯,看起来比较完美,哈哈。最终决定是2.0GHz的双核芯片,每核1GB内存
芯片,使用AMD Athlon 64 X2 3800 AM2+ CPUs. 2007年一月时每片价格$165 ,这种2.0GHz的双核芯片,是当时可以找到的性价比最好的。
(2007年8月就更便宜了,每片只有$65.00).
为了尽量减少体积,主板选用的是MSI Micro-ATX。此主板特点是小(9.6" by 8.2") ,并且有一个AM2
socket,可支持AMD的Athlon多核芯片。其实如果有条件的话,更应该做的是使用AMD的四核Athlon64
CPU替代这个双核,而这系统恰好还不用改。
To do so, we use motherboards with
a smaller form-factor
(like Little Fe)
than the usual ATX size,
and we space them using threaded rods
(like this cluster)
and scrap plexiglass, to minimize "packaging" costs.
By building a "double decker sandwich" of
four microATX motherboards, each with
a dual core CPU and
2 GB RAM (1 GB/core),
we can build a 4-node, 8-core, 8GB multiprocessor
small enough to fit on one's desktop,
powerful enough to do useful work,
and inexpensive enough that anyone can afford one.
此
主板上已经嵌有一个千兆网卡,还有一个PCI-e扩展插槽,在PCI-e插槽插入另一根网卡(41美元),用于平衡芯片运算速度和网络带宽。这样,四块主
板总共就有内嵌的4个网卡,外加PCI-e插槽的4张网卡,一共8个网络通道,用网线把它们都连接到8口路由器(100美元)上。
Our intent was to provide sufficient bandwidth for each
core to have its own GigE channel,
to make our system less imbalanced with respect to
CPU speed (two x 2 GHz cores) and network bandwidth (two x 1 Gbps adaptors).
This arrangement also let us
experiment with channel bonding the two adaptors,
experiment with HPL using various MPI libraries
using one vs two NICs,
experiment with using one adaptor for "computational" traffic
and the other for "administrative/file-service" traffic,
and so on.)
每块主板插了两根内存,共2G,这8G内存消耗了预算的40%!!
为了更小化,本小超算没有使用机箱,而是一个完全非封闭的外架,像Little Fe 和这些集群,把主板直接安装到有机玻璃上面,然后用几根小铁杆撑起来,并连接成一立体状。——(这个架子一般的五金店应该可以制造,用导热性好的铝/铁当托盘,整机的热分布会好点,也有利于集中散热)
最底部是两片有机玻璃隔开的一个夹层,放着8口路由,光驱,还有250GB的硬盘。
结构图如下:
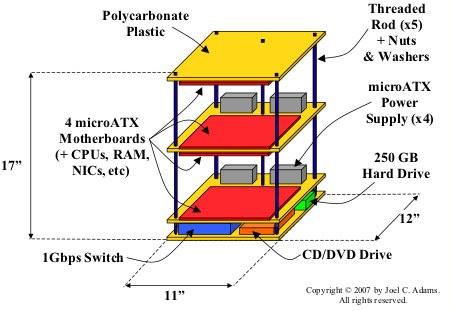
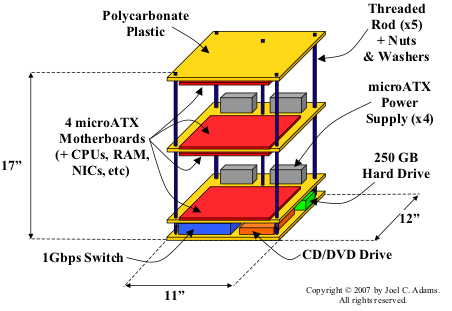
我们这小超算的硬件结构
如图所示,主板放在最顶层的下方,而中间层则两面都放主板,底层则上方放主板,这样做的目的是尽可能减少高度。
Since each of our four motherboards is facing another motherboard,
which is upside-down with respect to it, the CPU/heatsink/fan assembly
on one motherboard
lines up with the PCI-e slots in the motherboard facing it.
As we were putting a GigE NIC in one of these PCI-e slots,
we adjusted the spacing between the Plexiglas pieces so as to leave a 0.5" gap
between the top of the fan on the one motherboard and the top of the NIC on the
opposing motherboard. 这样的结果就是每块主板间的间距为6",如图所示:
主板之间的距离
(说明:这些主板都有一个单独 PCI-e x16插槽,留给以后想提升性能的时候,可以插上一块GPU)
使用350瓦的电源供电(每块主板一个),使用双面胶固定在有机玻璃上,电源插座放在最上面的有机玻璃上,如图所示:
本小超算的电源和风扇
(此处用胶水固定硬盘、光驱、路由器)
最靠近夹层的底部主板作为“主节点”——主控主板,连接硬盘、光驱(可选)等,系统启动/关机/重启的时候也是从这个部分操作。其他的主板当作“分支节点”,使用PXE网络启动方式启动。
对最底部的主控主板做特殊设置,连接250GB硬盘,并且作为启动分区。插入光驱(主要是用于安装初始系统,现在都不需要了,直接用优盘做系统安装盘吧……)
插入另一块网卡10/100 NIC到PCI插槽中,用于连接外部网络。
顶部三个节点都是无硬盘的,
and used NFS to export the space on the 250 GB drive to them。
下图显示了本小超算各个部分的连接关系(节点0为重心,连接了硬盘、光驱、以及连接外部的接口,内部中心为千兆路由,用于连接其他节点):
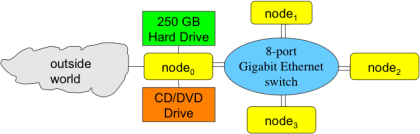
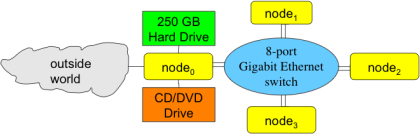
说明:每个节点都有两条独立的通讯线路,连接自己和网络路由器。
With four CPUs blowing hot air into such a small volume, we thought we should
keep the air moving through Microwulf.
To accomplish this, we decided to purchase four Zalman 120mm case fans
($8 each) and grills ($1.50 each).
Using scavenged twist-ties, we mounted two fans
-- one for intake and one for exhaust --
on opposing sides of each pair of facing motherboards.
This keeps air moving across the boards and NICs;Figure Five shows the two exhaust fans:
Figure Five: Two of Microwulf's (Exhaust) Fans
So far, this arrangement has worked very well: under load,
the on-board temperature sensors report
temperatures about 4 degrees above room temperature.
Last, we grounded each component (motherboards, hard drive, etc.)
by wiring them to one of the power supplies.
系统使用的是有奔头(Ubuntu Linux).
开源通用信道(Open MPI)将自动识别每个节点的网络适配器,并让它们之间组成一个圆环型的信息交流系统。
To try to help Open MPI spread the load on both the
sending and receiving side, we configured the on-board
adaptors to be part of a 192.168.2.x subnet,
and the PCI-e adaptors to be part of a 192.168.3.x subnet.
价格参考(2007年一月):
部件
产品名称
单价
数量
总价
主板
$80.00
4
$320.00
芯片
$165.00
4
$660.00
内存
$124.00
8
$992.00
电源
Echo Star 325W MicroATX Power Supply
$19.00
4
$76.00
网卡
Intel PRO/1000 PT PCI-Express NIC
(节点连接路由)
$41.00
4
$164.00
网卡
(主控主板连接外部网络)
$15.00
1
$15.00
路由器
Trendware TEG-S80TXE 8-port Gigabit Ethernet Switch
$75.00
1
$75.00
硬盘
$92.00
1
$92.00
光驱
$19.00
1
$19.00
冷切系统
$8.00
4
$32.00
风扇
Generic NET12 Fan Grill (120mm)
$1.50
+ shipping
4
$10.00
硬件支架
36" x 0.25" threaded rods
$1.68
3
$5.00
硬件固定
Lots of 0.25" nuts and washers
$10.00
机箱或外壳
12" x 11" 有机玻璃(是我们物理实验室的废品)
$0.00
4
$0.00
总价
$2,470.00
非必须的硬件
部件
产品名称
单价
数量
总价
KVM Switch
$50.00
1
$50.00
总价
$50.00
除了技术支持还有硬件加固 (购买自Lowes), 风扇和转接器购买自newegg.com,
其他都购买自(量多有折扣,呵呵):
N F P Enterprises
1456 10 Mile Rd NE
Comstock Park, MI 49321-9666
(616) 887-7385
So we were able to keep the price for the whole system to just under $2,500.
That's 8 cores with 8 GB of memory and 8 GigE NICs for under $2,500,
or about $308.75 per core.
构建配置:
点击此处:软件系统构建说明,有详细的介绍文件下载——建议想自己构建的人下载下来,然后按照其说明,逐步完成。
细节是魔鬼
首先是选用哪个你牛叉发行版:曾经一度使用Gentoo,但后来觉得gentoo太消耗能量了(包括系统管理员的精力和系统的耗电),后来
试了试有奔头,一开始安装的桌面是6.10版本,其内核是2.6.17,但美中不足的是he on-board
NIC的驱动需要到2.6.18才内置,所以一开始两个月,我们的小超算就用的7.04的测试版(内核是2.6.20),直到最后稳定版发行就换了稳定
版。
在其他三个计算节点上,安装的是有奔头的服务器版,因为它们不需要桌面功能。
也就是:有奔头桌面版+3个有奔头服务器版
我们也试过其他的集群管理软件:ROCKS,Oscar, 和 Warewulf.,但ROCKS和Oscar不支持无盘的节点。Warewulf工作良好,但因为本小超算实在太小,目前看不出其优势来。因为这篇论文,曾经想使用iSCSI。不过为了尽快让我们的集群运行起来,还是决定使用NFSroot,因为其配置非常简单,只需要修改/etc/initramfs.conf ,让其生成一个虚拟内存(initial ramdisk) that does NFSroot and then setting up DHCP/TFTP/PXELinux
on the head node, as you would for any diskless boot situation.
We did configure the network adaptors differently:
we gave each onboard NIC an address on a 192.168.2.x subnet,
and gave each PCI-e NIC an address on a 192.168.3.x subnet.
Then we routed the NFS traffic over the 192.168.2.x subnet,
to try to separate "administrative" traffic from computational traffic.
It turns out that OpenMPI will use both network interfaces (see below),
so this served to spread communication across both NICs.
One of the problems we encountered is that the on-board NICs
(Nvidia) present soem difficulties. After our record setting run
(see the next section) we started to have trouble with the on-board NIC.
After a little googling, we added the following option to the forcedeth
module options:
forcedeth max_interrupt_work=35
The problem got better, but didn't go away. Originally we had the onboard Nvidia
GigE adaptor mounting the storage.
Unfortunately, when the Nvidia adaptor started to act up, it reset itself,
killing the NFS mount and hanging the "compute" nodes.
We're still working on fully resolving this problem,
but it hasn't kept us from benchmarking Microwulf.
效果图:直接点击上面目录连接,可查看
性能表现:
所获得的性能表现
Once Microwulf was built and functioning it's fairly obvious that we
wanted to find out how 'fast' it was.
Fast can have many meanings, depending upon your definition.
But since the HPL benchmark is the standard used for the Top500 list,
we decided to use it as our first measure of performance.
Yes, you can argue and disagree with us, but we needed to start somewhere.
We installed the development tools for Ubuntu (gcc-4.1.2) and then built
both Open MPI andMPICH.
Initially we used OpenMPI as our MPI library of choice and we had both GigE NICs
configured (the on-board adaptor and the Intel PCI-e NIC that was in the x16 PCIe slot).
Then we built the
library, and
,
the High Performance Linpack benchmark.
The Goto BLAS library built fine, but when we tried to build HPL
(which uses BLAS),
we got a linking error indicating that someone had left
a function named main() in a module named main.f in /usr/lib/libgfortranbegin.a.
This conflicted with main() in HPL.
Since a library should not need a main() function,
we used ar to remove the offending module from /usr/lib/libgfortranbegin.a,
after which everything built as expected.
Next, we started to experiment with the various parameters for
running HPL - primarily problem size and process layout.
We varied PxQ between {1x8, 2x4}, varied NB between
{100, 120, 140, 160, 180, 200}, and used increasing values of N
(problem size) until we ran out of memory.
As an example of the tests we did, Figure Six below is a plot of the HPL performance
in GFLOPS versus the problem size N.
Figure Six: Microwulf Results for HPL WR00R2R24 (NB=160)
For Figure Six we chose PxQ=2x4, NB=160, and varied
N from a very small number up to 30,000.
Notice that above N=10,000, Microwulf achieves 20 GLFOPS,
and with N greater than 25,000, it exceeds 25 GFLOPS.
Anything above N=30,000 produced "out of memory" errors.
We did achieve a peak performance of 26.25 GFLOPS.
The theoretical peak performance for Microwulf is 32 GLFOPS.
(Eight cores x 2 GHz x 2 double-precision units per core.)
This means we have hit about 82% efficiency (which we find remarkable).
Note that one of the reasons we asume that we achieved such a high efficiency
is due to Open MPI, which will use both GigE interfaces.
It will round-robin data transfers over the various interfaces
unless you explicitly tell it to just use certain interfaces.
It's important to note that this performance occurredusing the default system and Ethernet settings.
In particular, we did not tweak any of Ethernet parameters mentioned inDoug Eadline and Jeff Layton's article on cluster optimization.
We were basically using "out of the box" settings for these runs.
To assess how well our NICs were performing, Tim did some followup HPL runs,
and used netpipe to gauge our NICs latency.
Netpipe reported 16-20 usecs (microseconds) latency on the onboard NICs,
and 20-25 usecs latency on the PCI-e NICs,
which was lower (better) than we were expecting.
As a check on performance we also tried another experiment.
We channel bonded the
two GigE interfaces to produce, effectively, a single interface.
We then used MPICH2 with the channel bonded interface and used the
same HPL parameters we found to be good for Open-MPI.
The best performance we achieved was 24.89 GLOPS (77.8% efficiency).
So it looks like Open MPI and multiple interfaces beats MPICH2 and a
bonded interface.
Another experiment we tried was to use Open MPI and just the PCI-e GigE NIC.
Using the same set of HPL parameters we have been using we achieved a
performance of 26.03 GFLOPS (81.3% efficiency).
This is fairly close to the performance we obtained when using both interfaces.
This suggests that the on-board NIC isn't doing as much work as we thought.
We plan to investigate this more in the days ahead.
下面看看历年最强500超算里面的本小超算性能方面的排名:
Nov. 1993: #6
Nov. 1994: #12
Nov. 1995: #31
Nov. 1996: #60
Nov. 1997: #122
Nov. 1998: #275
June 1999: #439
Nov. 1999: 被踢出名单了
1993年11月,本小超算可以排名世界第6。1999年6月,排名为第439,相比于一般超算放在一个大大的机房里,而且需要众多芯片,这个4片、8芯的集群,只有11" x 12" x 17",能有如此表现,很不错了。
更进一步挖掘下这个列表:1993年11月的排名中,排在第五位的超算是用了512片核芯的Thinking Machines CM-5/512,运算速度达到300亿次。本小超算的4核相当于当年的512核啊,哈哈。
1996年11月,此小超算排在第60位,下一个是用了256片核芯的Cray T3D MC256-8,现在8核俄性能都超过11年前的256核了,此处还没说价格差异呢,T3D花费了上百万美元!
超算性能一般以每秒浮算次数(flops)来衡量。早期超算使用百万次来衡量,随着硬件飞跃,十亿次已经是很落后的指标了,现在都流行用万亿次,甚至千万亿次来表示了。
Early supercomputer performance was measured in
megaflops (Mflops: 10
6
flops).
Hardware advances increased subsequent supercomputers
performance to gigaflops (Gflops: 10
9
flops).
Today's massively parallel supercomputers
are measured in teraflops (Tflops: 10
12
flops),
and tomorrow's systems will be measured in petaflops
(Pflops: 10
15
flops).
When discussing supercomputer performance, you must also
distinguish between
峰值性能 --理论上最大的性能表现
测量性能 -- 用检测软件检测出来的性能表现
一般计算机生产商会标示峰值,但实际检测一般只有峰值的50%-60%左右。
另一个要注意的是精度,一般高性能运算都是用的双精度,所以不可混淆了单精度和双精度运算。
The standard benchmark (i.e., used by thetop500.org supercomputer list)
for measuring supercomputer performance is
high performance Linpack (aka HPL),
a program that exercises and reports a supercomputer's
double-precision floating point performance.
To install and run HPL, you must first install a version of the
Basic Linear Algebra Subprograms (BLAS) libraries,
since HPL depends on them.
In March 2007, we benchmarked Microwulf using HPL andGoto BLAS.
After compiling and installing each package,
we ran the standard, double-precision version of HPL,
varying its parameter values as follows:
We varied PxQ between {1x8, 2x4};
varied NB between {100, 120, 140, 160, 180, 200};
and used increasing values of N, starting with 1,000.
For the following parameter values:
PxQ = 2x4; NB = 160; N = 30,000
HPL reported 26.25 Gflops on its WR00R2R4 operation.
Microwulf also exceeded 26 Gflops on other operations,
but 26.25 Gflops was our maximum.
在最强500超算中,1996年的Cray T3D-256也才达到253亿次,所以我们这个260亿次的性能,是足够用来做很多事情的了。
Since we benchmarked Microwulf,
Advanced
Clustering Technologieshas published a convenient
web-based calculator that removes much of the trial and error from
tuning HPL.
性价比:
When you have measured a supercomputer's performance using HPL,
and know its price, you can measure its cost efficiency
by computing its price/performance ratio.
By computing the number of dollars you are paying for each
floating point operation (flop),
you can compare one supercomputer's cost-efficiency against others.
With a price of just $2470
and performance of 26.25 Gflops,Microwulf's price/performance ratio (PPR)
is $94.10/Gflop, or less than $0.10/Mflop!This makes Microwulf
the first general-purpose Beowulf cluster to break
the $100/Gflop (or $0.10/Mflop) threshold
for measured double-precision floating point performance.
下面列表可作为参考,了解下这个性价比的意义:
In 1976,
the Cray-1
cost more than 8 million dollars
and had a peak (theoretical maximum) performance of 250 Mflops,
making its PPR more than $32,000/Mflop.
Since peak performance exceeds measured performance,
its PPR using measured performance
(estimated at 160 Mflops) would be much higher.In 1985,
the Cray-2
cost more than 17 million dollars
and had a peak performance of 3.9 Gflops,
making its PPR more than $4,350/Mflop ($4,358,974/Gflop).1997年,打败西方象棋世界冠军卡斯帕罗夫的
IBM 深蓝。价格是5百万美元,性能是113.8亿次,其性价比是43936.7美元/亿次In 2003, the U. of Kentucky's Beowulf cluster KASY0
cost $39,454 to build,
and produced 187.3 Gflops on the double-precision version of HPL,
giving it a PPR of about $210/Gflop.Also in 2003, the University of Illinois at Urbana-Champaign's
National Center for Supercomputing Applications built
the PS 2 Cluster
for about $50,000.
No measured performance numbers are available;
which isn't surprising, since the PS-2 has no hardware support for double
precision floating point operations.
This cluster's theoretical peak performance is about 500 Gflops
(single-precision); however, one study
showed that the PS-2's double-precision performance took
over 17 times as long as its single-precision performance.
Even using the inflated single-precision peak performance value,
its PPR is more than $100/Gflop;
it's measured double-precision performance is probably more than 17 times that.In 2004, Virginia Tech built
System X,
which cost 5.7 million dollars,
and produced 12.25 Tflops of measured performance,
giving it a PPR of about $465/Gflop.In 2007, Sun's Sparc Enterprice M9000
with a base price of $511,385,
produced 1.03 Tflops of measured performance,
making its PPR more than $496/Gflop.
(The base price is for the 32 cpu model,
the benchmark was run using a 64 cpu model,
which is presumably more expensive.)
$9.41/亿次,我们的小超算可以说是超算里面性价比最好的一个了,不过呢,还没法提供千万亿次的运算,若有需要,或许可以突破这个价格限制,让性能方面获得更大的提升。
效能 - 世界记录 功耗:
以2007年一月的价格,本小超算用了2470美元,获得262.5亿次的运算速度,平均9.41美元/亿次。这个已经成为新的世界纪录了。
另外,节能方面的事情最近也比较敏感,性耗比(耗电量/性能)也需要测量下了,性耗比对集群是非常重要的,尤其是成片的集群(比如谷歌的服务器场)。本小超算我们测试了下,
待机需要消耗250瓦(平均30瓦每核),
运行是需要消耗450瓦,
算了下运行时的性耗比就是1.714瓦/亿次。
对比下其他的超算。
专门进行节能设计的超算
使用了非常节能的芯片,只需要较低的冷切,240核消耗了3.2千瓦,获得的运算性能是1010亿次,性耗比为3.1瓦/亿次。是我们这个自制的小超算的两倍哦!!!
Another interesting comparison is to the Orion Multisystems clusters.
Orion is no longer around, but a few years ago they sold two commercial
clusters: a 12-node desktop cluster (the DS-12) and
a 96-node deskside cluster (the DS-96).
Both machines used Transmeta CPUs.
The DS-12 used 170W under load, and its performance was about 13.8 GFLOPS.
This gives it a performance/power ratio of 12.31W/GLFOP
(much better than Microwulf).
The DS-96 consumed 1580W under load, with a performance of 109.4 GFLOPS.
This gives it a performance/power ratio of 14.44W/GFLOP,
which again beats Microwulf.
Another way to look at power consumption and price is to use the metric
from Green 500.
Their metric is MFLOPS/Watt (the bigger the number the better).
Microwulf comes in at 58.33, the DS-12 is 81.18, and the deskside unit is 69.24.
So using the Green 500 metric we can see that the Orion systems are
more power efficient than Microwulf.
But let's look a little deeper at the Orion systems.
The Orion systems look great at Watts/GFLOP and considering the age of
the Transmeta chips, that is no small feat.
But let's look at the price/performance metric.
The DS-12 desktop model had a list price of about $10,000,
giving it a price/performance ratio of $724/GFLOP.
The DS-96 deskside unit had a list price of about $100,000,
so it's price/performance is about $914/GFLOP.
That is, while the Orion systems were much more power efficient,
their price per GFLOP is much higher than that of Microwulf,
making them much less cost efficient than Microwulf.
Since Microwulf is better than the Orion systems in price/performance,
and the Orion systems are better than Microwulf in power/performance,
let's try some experiments with metrics to see if we can find a useful
way to combine the metrics.
Ideally we'd like a single metric that encompasses
a system's price, performance, and power usage.
As an experiment, let's compute MFLOP/Watt/$.
It may not be perfect, but at least it combines all 3 numbers into a
single metric, by extending the Green 500 metric to include price.
You want a large MFLOP/Watt to get the most processing power per
unit of power as possible.
We also want price to be as small as possible
so that means we want the inverse of price to be as large as possible.
This means that we want MFLOP/Watt/$ to be as large as possible.
With this in mind, let's see how Microwulf and Orion did.
Microwulf: 0.2362
Orion DS-12: 0.00812
Orion DS-96: 0.00069
From these numbers (even though they are quite small),
Microwulf is almost 3 times better than the DS-12
and almost 35 times better than the DS-96 using this metric.
We have no idea if this metric is truly meaningful but it give us
something to ponder.
It's basically the performance per unit power per unit cost.
(OK, that's a little strange, but we think it could be a useful
way to compare the overall efficiency of different systems.)
We might also compute the inverse of the MFLOP/Watt/$ metric:
-- $/Watt/MFLOP --
where you want this number to be as small as possible.
(You want price to be small and you want Watt/MFLOP to be small).
So using this metric we can see the following:
Microwulf: 144,083
Orion DS-12: 811,764
Orion DS-96: 6,924,050
This metric measures the price per unit power per unit performance.
Comparing Microwulf to the Orion systems, we find that Microwulf is
about 5.63 times better than the DS-12,
and 48 times better than the DS-96.
It's probably a good idea to stop here,
before we drive ourselves nuts with metrics.
While most clusters publicize their performance data,
Very few clusters publicize their power consumption data.
Some notable exceptions are:
Green
Destiny,
an experimental blade cluster built at Los Alamos National Labs in 2002.
Green Destiny was built expressly to minimze power consumption,
using 240 Transmeta TM560 CPUs.
Green Destiny consumed 3.2 kilowatts and produced 101 Gflops
(on Linpack), yielding a power/performance ratio of 31 watts/Gflop.
Microwulf's 17.14 watts/Gflop is much better.The (apparently defunct) Orion
Multisystems DS-12 and DS-96 systems:The DS-12 "desktop" system consumed 170 watts under load,
and produced 13.8 Gflops (Linpack),
for a power/performance ratio of 12.31 watts/Gflop.
(The DS-12's list price was about $10,000,
making its price/performance ratio $724/Gflop.)The DS-96 "under desk" system consumed 1580 watts under load,
and produced 109.4 Gflops (Linpack),
for a power/performance ratio of 14.44 watts/Gflop.
(The DS-96's list price was about $100,000,
making its price/performance ratio about $914/Gflop.)我们的小超算性价比上
远超这些商业机器,其性耗比也居于前流。
节能500超算名单,是基于最强500超算的(本小超算没有被列入,呵呵),排名按每瓦运算次数排列。我们的小超算是1.713瓦/亿次,换算如下:
1 / 17.14 W/Gflop * 1000 Mflops/Gflop= 58.34 Mflops/W
2007年8月,我们的小超算超越了节能500超算的第二位,Mare Nostrum (58.23 Mflops/W) -- 可惜啊,和排名第一BlueGene/L (112.24 Mflops/W)的距离有点远。
结论
此小超算用了4块芯片、8核集群,大小为11" x 12" x 17",适合放在桌面上,也适合打包放到飞机上运输。
除了小巧,HPL检测本超算有262.5亿次的运算性能,总花费是2470美元(2007年1月),性价比为9.41美元/亿次。
本小超算能有如此神力的原因是:
多核芯片已经普及:这样可以让系统变得更小。
内存大降价:此小超算最贵的部分就是这个,不过价格一直在快速下降中,8G内存应该够用了吧??
千兆网卡已经普及:On-board GigE adaptors, inexpensive GigE NICs,
and inexpensive GigE switches allow Microwulf to offer
enough network bandwidth to avoid starving a parallel computation
with respect to communication.
我们不打算保守我们的技术秘密,而是希望所有人都来尝试这玩玩,嗯,其实很多部件都是可以替换的。
比如,随着固态硬盘的降价,可以试试固态硬盘替换掉机械硬盘,看看对性能有何影响。
比如内存:因为内存降价,可以把内存换为2GB的,这样每核可以2GB内存。Recalling that HPL kept running out of memory when we increased N above 30,000,
it would be interesting to see how many more FLOPS one could eke out with
more RAM.
The curve in Figure Six suggests that performance is beginning to plateau,
but there still looks to be room for improvement there.
比如主板和芯片:此微星主板使用AM2插槽,这个插槽刚好支持威盛新的4核Athlon64芯片,这样就可以替换掉上文中的双核芯片,使得整个系统变成
16核,性能更加强劲。有兴趣的同学可以测测这么做的结果性能提升多少?性价比因此而产生的变化?千兆内部网的效能变化等……
等等……尤其是已经几年后的今天(2012),这个列表几乎可以全部替换掉了。
2007年8月配件价格:
各个部件的价格下降很快。芯片、内存、网络、硬盘等,都降了好多价格。2007年8月在 新蛋(Newegg) 中的价格:
部件
产品名称
单价
数量
总价
主板
4
$201.28
芯片
威盛 Athlon 64 X2 3800+ AM2 CPU$65.00
4
$260.00
内存
Corsair DDR2-667 2 x 1GByte RAM
$75.99
4
$303.96
电源
LOGISYS Computer PS350MA MicroATX 350W Power Supply$24.53
4
$98.12
网卡
Intel PRO/1000 PT PCI-Express NIC
(节点连接路由)
4
$139.96
网卡
(主控主板连接外部网络)
1
$15.30
路由器
SMC SMCGS8 10/100/1000Mbps 8-port Unmanaged Gigabit Switch$47.52
1
$47.52
硬盘
1
$64.99 光驱
Liteon SHD-16S1S 16X$23.831$23.83
制冷设备
Zalman ZM-F3 120mm Case Fans$14.98
4
$59.92
风扇
Generic NET12 Fan Grill (120mm)$6.48
4
$25.92
硬件支架
36" x 0.25" threaded rods
$1.68
3
$5.00
硬件加固
Lots of 0.25" nuts and washers
$10.00
机箱或外壳
12" x 11" 有机玻璃(来自物理实验室的废物)
$0.00
4
$0.00 总价$1,255.80
(现在价格应该更低了!而且性能方面应该更强悍了!!!)
可见,2007年8月,这个性价比已经达到了4.784美元/亿次,突破5美元/亿次!!!!!
性耗比则保持不变。
如果融合价格、性能、功耗,则每百万次/瓦/美元为0.04645,是原来的小超算两倍。美元/瓦/百万次为 73,255,也是原来的两倍。
应用:
和其他超算一样,本小超算可以运行一些并行运算软件——需要特别设计,以利用系统的并行运算能力。
这些软件一般会使用 通用信道和并行虚拟机。这几个库提供了分布式计算的最基础功能,一是使得进程可以在网络间沟通和同步,二是提供了一个分布执行最后汇总的机制,使得程序可以被复制成多份,分别在各个节点上运行。
有很多应用软件已经可以在本小超算上使用,大部分是由特定领域的科学家写的,用于解决特定问题:
CFD
codes,
an assortment of programs for computational fluid dynamicsDPMTA,
a tool for computing N-body interactions fastDNAml,
a program for computing phylogenetic trees from DNA sequencesParallel finite element analysis (FEA) programs, including:
Adventure,
the ADVanced ENgineering analysis Tool
for Ultra large REal world,
a library of 20+ FEA modulesdeal.II,
a C++ program library providing computational solutions
for partial differential equations using adaptive finite elementsDOUG,
Domain decomposition On Unstructured GridsGeoFEM,
a multi-purpose/multi-physics parallel finite element
simulation/platform for solid earthParaFEM,
a general parallel finite element message passing libaryParallel FFTW,
a program for computing fast Fourier transforms (FFT)GADGET,
a cosmological N-body simulatorGAMESS,
a system for ab initio quantum chemistry computationsGROMACS,
a molecular dynamics program for modeling molecular interactions,
especially those from biochemistryMDynaMix,
a molecular dynamics program for simulating mixturesmpiBLAST,
a program for comparing gene sequencesNAMD,
a molecular dynamics program
for simulating large biomolecular systemsNPB 2,
the NASA Advanced Supercomputing Division's Parallel Benchmarks
suite. These include:BT, a computational fluid dynamics simulation
CG, a sparse linear system solver
EP, an embarrassingly parallel floating point solver
IS, a sorter for large lists of integers
LU, a different CFD simulation
MG, a 3D scalar Poisson-equation solver
SP, yet another (different) CFD simulation
ParMETIS,
a library of operations on graphs, meshes, and sparse matricesPVM-POV,
a ray-tracer/rendererSPECFEM3D,
a global and regional seismic wave simulatorTPM,
a collisionless N-body (dark matter) simulator
这是我们使用小超算的领域:
给卡尔文大学的本科生做研究项目
As a high performance computing resource for
CS 374:
High Performance Computing正在做的事情:
给本地的高中学校也定制几个,以提升学生了解计算的兴趣
用于会议,作为一个个人超算的示例模型。
When not being used for these tasks,
Microwulf runs the client for Stanford's Folding@Home project,
which helps researchers better understand protein folding,
which in turn helps them the causes of
(and hopefuly the cures for) genetic diseases.
Excess CPU cycles on a Beowulf cluster like Microwulf can be
devoted to pretty much any distributed
computing project.
常见问题回答:
Will Microwulf run [insert favorite program/game] faster?
Unless the program has been written specifically to run in
parallel across a network
(i.e., it has been written using a parallel library like
message passing interface (MPI)), probably not.A normal computer with a multicore CPU is a shared memory multiprocessor, since programs/threads running on the
different cores can communicate with one another through
the memory each core shares with the others.On a Beowulf cluster like Microwulf, each motherboard/CPU has its own
local memory, so there is no common/shared memory through which
programs running on the different CPUs can communicate.
Instead, such programs communicate through the network,
using a communication library like
MPI.
Since its memory is distributed among the cluster's CPUs,
a cluster is a distributed memory multiprocessor.Many companies only began writing their programs for shared-memory
multiprocessors (i.e., using multithreading) in 2006
when dual core CPUs began to appear.
Very few companies are writing programs for distributed memory
multiprocessors (but there are some).
So a game (or other program) will only run faster on Microwulf
if it has been parallelized to run on a distributed multiprocessor.可以使用视窗系统来驱动小超算么?
The key to making any cluster work is the availability of
a software library that will in parallel run a copy of a program
on each of the cluster's cores,
and let those copies communicate across the network.
The most commonly used library today is
MPI.There are several versions of MPI available for Windows.
(To find them, just google 'windows mpi'.)
So you can build a cluster using Windows.
But it will no longer be a Beowulf cluster,
which, by definition, uses an open source operating system.
Instead, it will be a Windows cluster.Microsoft is very interested in high performance computing --
so interested, they have released a special version of Windows called Windows
Compute Cluster Server (Windows CCS),
specifically for building Windows clusters.
It comes with all the software you need to build a Windows cluster,
including MPI.
If you are interested in building a Windows cluster,
Windows CCS is your best bet.我也要搞部小超算,可到哪里学习?
There are many websites that describe how.
Here are a few of them:Building a Beowulf System, by Jan Lindheim,
provides a quick overviewJacek Radajewski and Douglas Eadline's HowTo
provides a more detailed overviewKurt Swendson's HowTo
provides step-by-step instructions for
building a cluster using Redhat Linux and LAM-MPIEngineering a Beowulf-style Compute Cluster,
by Robert Brown, is an online book on building Beowulf clusters,
with lots of useful information.The Beowulf mailing list FAQ,
by Don Becker, et al, is a list of answers to questions
frequently posted to the
Beowulf.org mailing list,
which has a searchable Archive.Beowulf.org's Projects page
provides a list of links to the first hundred or so Beowulf
cluster project sites.
Many of these sites provide information that is useful to
someone building a Beowulf cluster.How did you mount the motherboards to the plexiglas?
Our vendor supplied
screws and brass standoffs
with our motherboards.
The standoffs have a male/screw end, normally screwed into the case;
and a female/nut end, to which the motherboard is screwed.
To use these to mount the motherboards,
we just had to:To prepare each plexiglass piece, we laid a motherboard on top of it
and then used a marker to color the plexiglass through the
motherboard's mounting holes.
The only tricky parts are:We used a red marker to mark the positions of the
holes on motherboards facing up, and a blue marker to mark
the positions of the holes on motherboards facing down.With the plexiglass pieces marked,
we took them to our campus machine shop
and used a drill press to drill holes in each piece of plexiglass.When all the motherboard holes were drilled, we stacked the
plexiglass pieces as they would appear in Microwulf and
drilled holes in their corners for the threaded rods.We then screwed the standoffs into the plexiglass,
taking care not to overtighten them.
Being made of soft brass, they are very easy to shear off.
If this happens to you, just take the piece of plexiglass back to the
drill press and drill out the bit of brass screw that's in the hole.
(Or, if this is the only one, you can just leave it there and
use one fewer screws to mount the motherboard.)With the standoffs in place,
we then placed the motherboards on the standoffs,
and used screws to secure them in place.
That's it!The only other detail worth mentioning is that before we screwed
each motherboard tight to the standoffs, we chose one standoff
on each motherboard to ground that motherboard against static.
To do this grounding, we got some old phone wire,
looped one end to the standoff,
and then tightened the screw for that standoff.
We then grounded each wire to one of the threaded rods,
and grounded that threaded rod to one of the power supplies.one piece of plexiglass has motherboards on both its top
and its bottom, so you have to mark both sides; andtwo motherboards hang upside down, and two sit right-side up,
so you have to take that into account when marking the holes.drill holes in the plexiglass pieces
in the same positions as the motherboard mounting holes;screw the brass standoffs into the holes in the
plexiglass pieces; andscrew the motherboards to the standoffs.
这小超算是商品么?可以卖么?
否,主要是因为我们都不懂商业。But we are trying to build an endowment to provide in-house
funding for student projects like Microwulf,
so if you've found this site to be useful,
please consider making a (tax-deductible) donation to it:CS Hardware Endowment Fund Department of Computer Science Calvin College 3201 Burton SE Grand Rapids, MI 49546
谢啦!
某网友测试过评论如下
好多年前的事情了.....
不在于系统是ubuntu Linux
而问题的重点是:
你会组装机器 硬件组装; 会作系统优化配置, 会配置很多服务, 比如NFS(构建无盘系统),NIS, 构建用户信息, MPI(高斯可以不用这个并行环境), 网络优化, 几个机器之间通信能力的优化,
如果你仅仅是明白硬件, 而对于linux系统的水平只专注于3D桌面之类的桌面应用, 那么你要搞明白这套系统,
还是比较困难的。
我自己作过, 只不过是用的两台机器,也是无盘系统, 系统采用自己熟悉的RHEL, 5.3 ,
那位作者的组装说明, 适合管理过linux系统, 熟悉linux网络应用的人看,
没有涉及过网络管理, 网络应用的, 要作下去比较费劲的。
他写的只是一个方案, 不是具体的每一步的how-to,
谁有兴趣的可以试试!
这套无盘系统, 性能很大程度取决于你的磁盘性能!
注意,这套系统, 适合并